La ricerca della compatibilità tra Linux e Windows è una storia lunga quasi quanto i due sistemi operativi. È un percorso fatto di tentativi, fallimenti e incredibili successi. Oggi diamo per scontato di poter avviare software Windows su Linux, ma un tempo questa idea sembrava pura fantascienza.
In questo scenario, nei primi anni Duemila, un progetto ambizioso provò a fare l'impossibile: creare un ponte tra questi due mondi. Sei pronto a scoprire la storia di un pioniere coraggioso che ha anticipato i tempi?
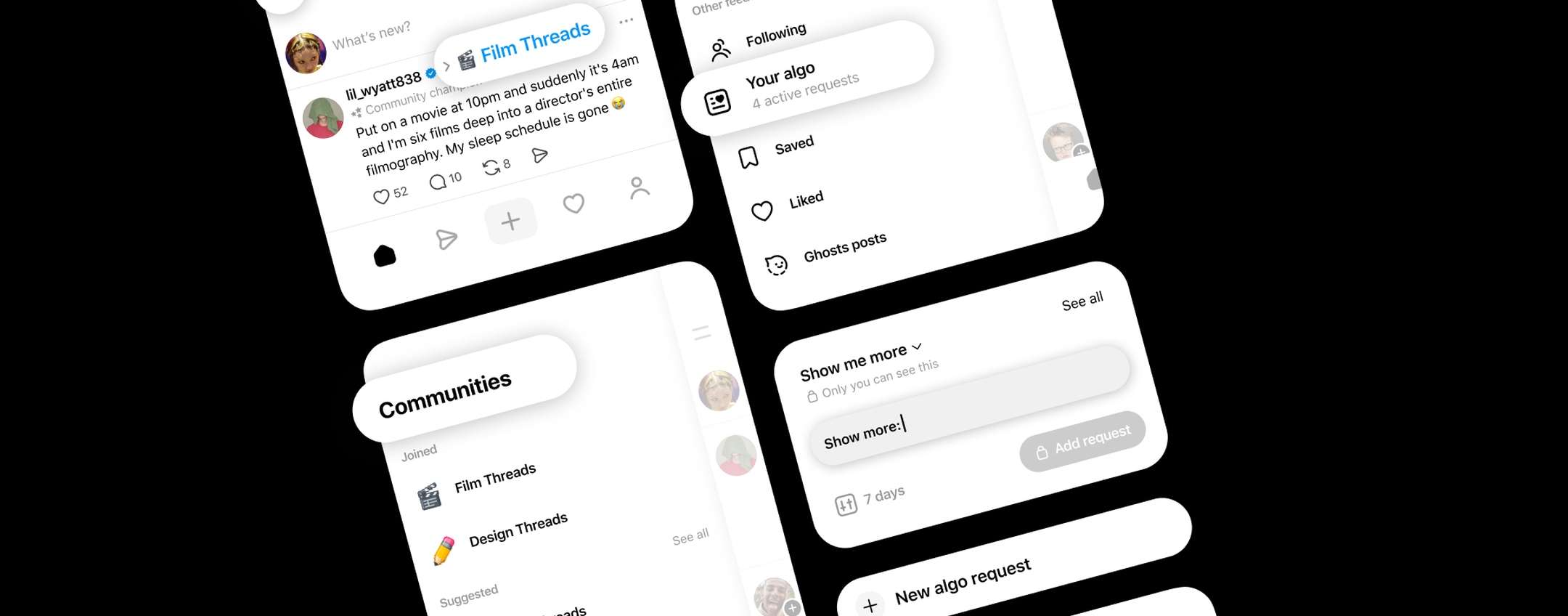
Un sogno audace: Linux per tutti, con i programmi di sempre
Immagina la scena: siamo nel 2001. Il mondo dei PC è dominato da Microsoft, con Windows XP che si prepara a diventare il re incontrastato. Linux, d'altra parte, è un sistema potente ma percepito come complesso dall'utente medio. Il principale ostacolo alla sua adozione? La mancanza di software. Chiunque volesse passare a Linux si trovava di fronte a un muro. Come usare i programmi di lavoro, le utility e i giochi a cui era abituato?
In questo contesto, l'imprenditore Michael Robertson, già noto per l'avventura di MP3.com, lanciò una sfida folle. L'obiettivo era creare una distribuzione Linux in grado di eseguire le applicazioni Windows in modo semplice e trasparente, senza complesse configurazioni. L'idea non era creare un prodotto di nicchia, ma portarlo sui computer preassemblati, venduti nei grandi magazzini come Walmart. Un vero e proprio attacco diretto al monopolio di Microsoft, pensato per l'utente comune.
Come funzionava (e non funzionava) Lindows?
Tecnicamente, il sistema operativo era basato su una solida distribuzione, Debian, e utilizzava una versione primordiale di Wine come "traduttore" per i file .exe di Windows. Wine, che oggi è un software maturo e potentissimo, all'epoca era ancora un progetto acerbo. Il suo compito era, ed è tuttora, quello di replicare le API (le librerie di sistema) di Windows, ma il suo supporto era estremamente limitato. Il risultato? La realtà tecnica presentò presto il conto.
Molte applicazioni mostravano problemi di ogni tipo: Anomalie grafiche e instabilità. Incompatibilità con driver e periferiche. Crash improvvisi dovuti a chiamate di sistema non supportate. Nonostante le difficoltà, il progetto introdusse un'idea geniale e in anticipo sui tempi: Click-N-Run (CNR). Si trattava di un servizio che permetteva di installare applicazioni Linux con un solo clic da un catalogo digitale. Il tutto, senza dover mai toccare la riga di comando. Un concetto che sarebbe diventato familiare a tutti solo molti anni dopo, con l'avvento degli app store.
La battaglia legale: quando un nome costa 20 milioni
Ovviamente, un nome come "Lindows" non poteva passare inosservato a Redmond. Microsoft non perse tempo e intentò una causa legale, sostenendo che il marchio creasse confusione con il suo prodotto di punta, Windows. La difesa, però, fu astuta. Sostenne che il termine "windows" (finestre) era una parola generica nel mondo dell'informatica per descrivere le interfacce grafiche, utilizzata ben prima di Windows 1.0.
A sorpresa, alcuni tribunali si mostrarono aperti a questa tesi, creando un rischio concreto per Microsoft. Dopo quasi tre anni di battaglie legali, Microsoft decise di chiudere la disputa con un accordo da 20 milioni di dollari. Con quella cifra non acquistò la tecnologia, ma semplicemente il diritto su quel nome, proteggendo così il suo brand più prezioso. L'azienda di Robertson fu costretta a cambiare identità, rinascendo come Linspire.
L'eredità di Lindows: la compatibilità tra Linux e Windows oggi
Cosa ci insegna questa storia? L'OS non riuscì a mantenere le sue promesse, ma fu un pioniere visionario. Individuò un problema reale e provò a risolverlo con gli strumenti limitati della sua epoca. Oggi, quel sogno di compatibilità è diventato realtà grazie a tecnologie incredibilmente più avanzate.
Da Wine a Proton: la rivoluzione del gaming
Il progetto Wine non si è mai fermato e ha raggiunto una maturità impensabile. Gran parte del merito va a Valve, che con il suo progetto Proton (una versione potenziata di Wine) ha reso Linux una piattaforma credibile per il gaming. Migliaia di giochi nati per Windows ora girano perfettamente, spesso con un semplice clic, grazie all'integrazione con Steam.
Approcci diversi per una compatibilità totale
Oltre a Wine, oggi esistono soluzioni ancora più radicali. Progetti come WinApps, ad esempio, eseguono una vera e propria copia di Windows in un ambiente virtuale nascosto, integrando le singole applicazioni nel desktop Linux. L'utente avvia Word o Photoshop come se fossero programmi nativi, garantendo una compatibilità quasi perfetta. In conclusione, la domanda che Lindows si pose nel 2001 è ancora la stessa. Ciò che è cambiato sono gli strumenti per rispondere. Quell'idea, un tempo considerata folle, ha gettato le basi per un futuro in cui i confini tra sistemi operativi sono sempre più sottili.
Firefox 152 is now available for download, after no fewer than four minor point releases to its predecessor, last month’s Firefox 151. And quieting noisy tabs has never been easier. It’s a good time to check out the Fox: recently, this patch to the Google Chromium codebase, continues closing the door to Manifest V2 extensions, as The Register warned you was coming early last year. As the W3C documents, the forthcoming Google Chrome 150 turns off the last workarounds available for full-power ad blockers, and Chrome 151 will nuke them altogether. Firefox 152 revamps the layout of the Settings page. To be honest, we had no particular problems with this before, but it’s a good thing to make it easier to twiddle the knobs and dials that make Firefox arguably the most extensible and customizable web browser. The new version also understands that sometimes you just want it to shut up. When a tab (or, worse, multiple tabs) are playing audio, if you go to the address bar and type “mute” (or “sssh” or “hush”), then a new Quick Action button appears beneath it offering to immediately silence all tabs in all windows at once. For some streaming services, there are also improved media playback controls on the tab context menu, but we don’t use streaming much around these parts and weren’t able to test this. If you admired the cleverness of the JPEG XL format as much as this Vulture , then we have glad tidings. Back in 2022, we reported that Google was dropping JPEG-XL support from Chromium and Chrome. Back in January, Mountain View changed track on this, and now, Firefox 152 has experimental JPEG XL support too. The functions for sending tabs to other devices, and for copying URLs for easier sharing, have been improved. There’s an optional new “Send Tab” toolbar button. You can also right-click on a tab button and get options to send it to a nominated device, or copy its URL for sharing. Better still, this also applies to groups of tabs: hold down Ctrl or Cmd, select several, and right-click any of them, and they’ll all be sent, or their URLs copied, in one action. There are also multiple bug fixes, about 40 security fixes, and as always, some new features for developers. Speakers of Basque or Galician will welcome their inclusion in its translation répertoire. Mozilla’s fast release cycle for Firefox is a minor irritation, yes. (Of course, there’s always the Extended Support Release channel, if you want to hop off the treadmill.) However, one interpretation of it – and the stream of bug-fix versions – is that Mozilla is working hard on Firefox, and in our view that’s good news. A new source of information that the company has published with this version) is the new Firefox Roadmap, which has info about future planned changes. ®
UBUNTU SUMMIT At a Canonical event, we didn't expect a presentation on using Red Hat's container management tools, but if this is something you might need, it does sound useful. At Ubuntu Summit 26.04, Red Hat Principal Software Engineer Joseph Marrero Corchado presented a talk called Bootc: Use your container knowledge and infrastructure to build and deploy your Ubuntu hosts. Although Ubuntu is very strong in the desktop Linux space, in large corporate server environments, Ubuntu is just another distro among many. This can be a good thing: it is just another Linux distro, and that means that it's perfectly possible to deploy and manage it using existing FOSS tooling. Marrero introduced himself by saying that he works at Red Hat, but personally runs Ubuntu – and has been doing so for long enough that he has some original media from Canonical's ShipIt program, which the company discontinued in 2011. While we were surpised to see a Red Hat engineer presenting a talk at the summit, it's not unprecedented. System76's Pop!_OS distro is based on Ubuntu, but it overlaps with other distros as well. It has its own desktop and eschews Snap for Flatpak – and yet, at the previous Summit, System76 boss Carl Richell presented a talk about it. The year before, the Academy Software Foundation's talk started by telling us that Rocky Linux strongly dominated the SFX industry. Our plan here isn't to recap the entire talk. It's up on YouTube now, and if this is the sort of thing that sounds interesting, it's probably a good use of 42 minutes of your time. bootc grows up We've mentioned the bootc toolchain a few times on The Register. Back in April 2024, we reported that Fedora 40's immutable editions were being rebuilt as bootable containers. Two years and four more Fedora releases later, the toolchain is getting more mature, as we covered in April with Fedora 44, and we linked to Quentin Joly's explainer, Bootc and OSTree: Modernizing Linux System Deployment, which is still one of the best we've read. Now bootc has graduated to the point of being a CNCF incubator project. The new project website has a slightly better explanation: Transactional, in-place operating system updates using OCI/Docker container images. The tools for creating and managing OCI containers are familiar to many sysadmins now, and the idea of bootc is to make it possible to manage complete OS images, either for VMs or for bare metal, using the same tooling. Marrero explained bootc by saying that it lets you perform OS installations and upgrades with OCI containers, which lets you define and ship your customized images of the Ubuntu OS as OCI container images. This allows transactional in-place updates, with rollback. This tech is already in real-world public-facing use: SteamOS uses bootc, and he pointed to the Bootcrew project, which maintains a growing collection of bootc images of different OSes, including Ubuntu, SteamOS, openSUSE, and Debian. What's special about these images is that each one is a container, but with a kernel. So this means that it can run on metal, but you can run (and test) it in continuous integration as well. Ubuntu on bootc is still Ubuntu; it's just a different way to deploy it. Doing it this way is an alternative to Canonical's own Ubuntu-image system, which uses standard Ubuntu and Canonical tools, the apt command, normal repositories, and so on. Instead, bootc uses container tools and container images, and a container registry in place of Ubuntu's apt repositories. Marrero has his own experimental Ubuntu-bootc image on GitHub, whose description says: An Ubuntu 26.04 LTS ("Resolute Raccoon") bootable container image with cloud-init and podman built-in, designed for use with bootc and bcvk. (For the record, bcvk is the bootc virtualization kit, which "helps launch ephemeral VMs from bootc containers, and also create disk images that can be imported into other virtualization frameworks.") The idea is that this lets you manage and deploy a server, cloud, or desktop OS, along with all its tools and all its applications, from a single central point that you control. This replaces a whole raft of configuration management tools, including local update management, and eliminates the need for tools such as "Puppet, Chef, or shell automation." The images are constructed using composefs – specifically, the Rust-based composefs-rs – which in turn builds on existing and established Linux tools such as overlayfs, the EROFS read-only filesystem, and fsverity for integrity-checking. He noted that some of Ubuntu's metadata initially stopped composefs from working, but he and the Bootcrew team found it and fixed it. He also offers an Ubuntu 26.04 LTS with bootc – Getting Started Guide, which "walks you through converting an Ubuntu 26.04 LTS VM into a bootc-managed system using composefs. By the end you will have an immutable, image-based Ubuntu system that can be updated atomically via container images." He also demonstrated the tech live on stage using a few demonstration images he'd built beforehand. First, he deployed an empty default Ubuntu installation, with no additional tools. Running it under QEMU took just a couple of seconds. Then, by adding another single-line container file layered on top, he added the tmux terminal multiplexer. He also used wget to demonstrate that no web server was running and the VM didn't respond to HTTP requests, then switched the existing VM to a different image with Apache and a demo page installed, which took only about a second to deploy, followed by a VM reboot. He also demonstrated that it really was Ubuntu, that snapd was present and working, and installed LXD to prove the point. The "bootable containers" toolchain has visibly matured since we first encountered it, and the demo was quite impressive. This vulture is very happy that he no longer has to run servers for a living, and is positively delighted that he has no use for any of these tools. Even so, it's impressive to see that without all that much work, Ubuntu can be slotted into a very different set of management tools and function quite happily. ®
Flatpak development has been very quiet for years. Discussions about a next-generation take are happening – and some of the signs are worrying if, like many FOSS folks, you are systemd-intolerant. In the course of researching our article on MX Linux 25.2, we came across an interesting Reddit discussion from last month, which in turn led us to a Flatpak development blog post from late last year. It looks like a team is collecting ideas for what is currently called "Flatpak-NG" – as in next generation. If this solidifies into code, this may form the basis of Flatpak version 2. The blog post isn't very informative, but the Reddit thread links to the video of a presentation from last month's Linux App Summit in Berlin, which spells things out more clearly. The Flatpak-NG idea involves handing off a lot of the isolation in Flatpak from the current bubblewrap layer to an as-yet-unwritten systemd component that the developers are currently calling systemd-appd. This would considerably simplify Flatpak, and enable it to do more isolation, including virtualizing the network stack – but at the price of making Flatpak 2 depend on systemd. A developer who was at the talk, Jorge Castro, later explained and confirmed this in a Fediverse thread. The teams behind other init systems could, of course, write their own replacement for the notional systemd-appd, but that would be a substantial amount of work. The tool that provides the new init-switching functionality in MX Linux 25.1 and 25.2, init-diversity, currently supports six other init systems besides systemd, and we've seen little sign of them cooperating to create an alternative to systemd that provides even a subset of its wider functionality. Flatpak is widely used and supported. Not all distros include it by default, but it's the only widely adopted alternative to Canonical's Snap packaging system. Snap is more versatile: it works fine with shell programs, and even the kernel can be packaged as a Snap, which is how Ubuntu Core handles it. Snap's implementation is much simpler and cleaner than Flatpak's, as is the distribution model – which, as we've reported before, is entirely open source. The only proprietary part is Canonical's Snap Store website. The trouble is, the louder advocates in the peanut gallery rarely even think about things like implementation details; they just get upset about more visible things that are easier to understand – such as who owns a website. There are other alternatives out there, such as AppImage, 0install, AppDir, and GNUstep's implementation of NeXT and Apple's .app format. We have compared these in detail before. Only two really have wide adoption, though. There's Snap, which Canonical claims has more users simply because Ubuntu has more users than all the other desktop distros put together, and there's Flatpak, which is used by every other distro with any kind of cross-distro package support. The snag is, if Flatpak 2 does arrive in a year or two, and requires systemd, then that could spell the end of Flatpak support on many systemd-free distros. That includes MX Linux, Alpine Linux, Devuan, Slackware, and many other smaller projects. For many of these, Flatpak is a lifeline: the only way to access much of the wider Linux app market. It's not so much that the Flatpak-NG team is the "A-Team," but the only team. In the original A-Team, Colonel John "Hannibal" Smith was wont to say "I love it when a plan comes together." We suspect a lot of people will not love it if this plan comes together. ®
Le funzioni di iOS 27 nascoste che stanno emergendo promettono di rendere il tuo iPhone ancora più potente di quanto immagini. Il WWDC 2026 ci ha già svelato meraviglie, con l'intelligenza artificiale di Siri a rubare la scena. Eppure, sembra che Apple abbia tenuto in serbo alcune sorprese.
Dietro le quinte, l'azienda sta lavorando a delle chicche non mostrate sul palco. Non si tratta di piccole correzioni, ma di funzionalità capaci di cambiare l'uso quotidiano dei tuoi dispositivi. Sei pronto a scoprire cosa bolle in pentola a Cupertino? Vediamo insieme le tre novità più interessanti che potrebbero arrivare entro settembre.
Un quadrante esclusivo arriva per tutti su Apple Watch
Hai mai desiderato lo stile del quadrante Modular Ultra, ma non possiedi un Apple Watch Ultra? Buone notizie in arrivo. Apple sta per rendere disponibile una versione alleggerita di questo amatissimo quadrante per un pubblico più vasto. L’idea è semplice ma geniale.
Manterrà l'orologio di grandi dimensioni che lo rende così leggibile e iconico, eliminando però la seconda fila di complicazioni. Il risultato è un'interfaccia più pulita e snella, perfetta per chi è passato da un modello Ultra a un Series 10 e sente la mancanza di quel design. È una piccola attenzione che dimostra quanto Apple ascolti i feedback degli utenti.
Siri diventa più intelligente con le estensioni di terze parti
Questa è forse la novità più attesa. L'attuale integrazione di Siri con ChatGPT è stata solo un assaggio del futuro. Con iOS 27, Apple ha in programma di fare un passo da gigante, aprendo finalmente le porte ad altri chatbot come Gemini e Claude. La vera rivoluzione si chiama Extensions API.
Invece di stringere accordi commerciali con ogni singola azienda, Apple fornirà agli sviluppatori uno strumento per integrare i loro modelli di intelligenza artificiale direttamente in Siri. Questo significa un ecosistema più aperto e competitivo. Tuttavia, c'è un rovescio della medaglia: non essendo partnership dirette, le garanzie sulla privacy potrebbero essere diverse rispetto all'accordo iniziale con OpenAI.
Perché Apple non ne ha ancora parlato?
Ti starai chiedendo perché un annuncio così importante sia stato tenuto nascosto. Le ragioni potrebbero essere diverse e molto strategiche:
La questione legale in Europa: una maggiore apertura potrebbe complicare la battaglia di Apple contro il Digital Markets Act (DMA).
Mantenere i riflettori su Apple: presentare modelli esterni più potenti avrebbe potuto mettere in ombra i progressi dell'intelligenza artificiale di Apple.
Rapporti con i partner: si vocifera di possibili tensioni con OpenAI, che non avrebbe gradito essere "una delle tante" opzioni.
Semplicità per l'utente: troppe integrazioni fin da subito avrebbero potuto creare confusione.
La tua fotocamera, le tue regole: personalizzazione totale in arrivo
L'ultima delle funzioni nascoste di iOS 27 riguarda un'app che usiamo tutti i giorni: la Fotocamera. Immagina di poter spostare i controlli, come il flash o il timer, esattamente dove li vuoi tu. Non dovrai più cercare le impostazioni giuste nel momento sbagliato. iOS 27 dovrebbe introdurre una fotocamera completamente personalizzabile.
Potrai riorganizzare l'interfaccia per adattarla perfettamente al tuo stile di scatto, rendendo l'esperienza più rapida e intuitiva. Anche se questa novità non è apparsa nella prima beta per sviluppatori, l'attesa è altissima. Sarebbe un cambiamento che premierebbe sia i fotografi amatoriali che i professionisti.
Cosa dobbiamo aspettarci davvero?
In sintesi, iOS 27 si preannuncia un aggiornamento ancora più ricco di quanto visto al WWDC. Un quadrante più accessibile, un Siri finalmente aperto al mondo e una fotocamera su misura sono novità che potrebbero davvero migliorare la nostra esperienza quotidiana. Sebbene non ancora ufficiali, queste indiscrezioni provengono da fonti molto affidabili nel mondo Apple. Non ci resta che attendere il rilascio ufficiale a settembre. E tu, quale di queste funzioni attendi con più impazienza?
La nuova sinergia tra Firefox, Vulkan e le GPU NVIDIA sta per rivoluzionare l'esperienza multimediale su Linux. Si tratta di un passo avanti tecnologico atteso da anni. Se utilizzi una scheda grafica NVIDIA sul sistema operativo del pinguino, questa è una notizia di fondamentale importanza. Mozilla sta infatti integrando il supporto a Vulkan Video, una tecnologia che promette di risolvere i problemi legati all'accelerazione hardware dei video.
In parole semplici, questo significa dire addio a configurazioni complesse. Si dà il benvenuto a una riproduzione video più fluida, efficiente e stabile. Sei pronto a scoprire come cambierà il tuo modo di guardare contenuti online?
Il vecchio problema: perché va-api non bastava?
Per capire l'importanza di questa novità, è necessario fare un passo indietro. Fino a oggi, Firefox si è affidato a un'interfaccia chiamata VA-API per la decodifica video hardware. Lo scopo è semplice: delegare il pesante lavoro di elaborazione dalla CPU alla GPU, liberando così risorse e riducendo i consumi energetici.
Questa soluzione ha sempre funzionato bene con le schede grafiche Intel e AMD. Il problema, però, ha sempre riguardato NVIDIA. L'azienda ha storicamente seguito un percorso tecnologico differente, basato su standard proprietari come NVDEC e NVENC. Di conseguenza, per far dialogare Firefox con una GPU NVIDIA su Linux, gli utenti erano costretti a usare "traduttori" software. Un esempio noto è il `nvidia-vaapi-driver`. Questa catena di passaggi aggiuntivi introduceva spesso instabilità, bug e una complessità non necessaria.
Cosa cambia con l'integrazione di vulkan video?
L'arrivo di Vulkan Video cambia completamente le carte in tavola. Questa tecnologia, sviluppata dal Khronos Group, è un'estensione delle API grafiche Vulkan, pensata appositamente per la codifica e decodifica video. Vediamo i vantaggi principali.
Un ponte diretto tra browser e gpu
Il beneficio più grande è l'adozione di uno standard unico e multipiattaforma. Invece di gestire interfacce diverse per ogni produttore, Firefox potrà comunicare direttamente con la GPU attraverso un unico linguaggio condiviso. Questo non significa che tecnologie hardware come NVDEC di NVIDIA verranno abbandonate. Al contrario, Vulkan Video crea un ponte software moderno e ottimizzato per accedervi, eliminando la necessità di strati di compatibilità esterni. Per gli sviluppatori, questo si traduce in un codice più pulito e facile da mantenere.
Prestazioni migliori e consumi ridotti
Per l'utente finale, i vantaggi sono ancora più concreti. La decodifica hardware diretta si traduce in:
Meno carico sulla CPU: la riproduzione di video in 4K, specialmente con codec pesanti come AV1, non metterà più in difficoltà il processore.
Maggiore efficienza energetica: un aspetto cruciale per i portatili, perché garantisce una maggiore autonomia della batteria.
Riproduzione più stabile: eliminando i passaggi intermedi, si riducono drasticamente le possibilità di errori o interruzioni.
In breve, potrai finalmente goderti i contenuti multimediali con la massima qualità possibile, senza compromessi.
Quando arriverà questa novità?
Il lavoro di integrazione è in fase avanzata, frutto della collaborazione tra ingegneri di Mozilla, Red Hat e della stessa NVIDIA. Salvo imprevisti, il supporto a Vulkan Video dovrebbe essere introdotto ufficialmente con il rilascio di Firefox 133, previsto entro la fine del 2024.
L'attesa è breve e testimonia l'impegno verso una soluzione solida e ben testata. È un segnale forte di come l'industria si stia muovendo verso standard aperti e condivisi, a tutto vantaggio dell'esperienza utente.
In conclusione: un futuro più fluido per linux
L'integrazione di Vulkan Video in Firefox rappresenta molto più di un semplice aggiornamento tecnico. È la chiusura di un cerchio per gli utenti Linux che, per anni, hanno cercato di ottenere un'esperienza multimediale impeccabile con il proprio hardware NVIDIA. Questa mossa non solo semplifica la vita agli utenti e agli sviluppatori, ma rafforza anche la posizione di Linux come sistema operativo maturo e performante per l'uso desktop quotidiano.
GitHub has been struggling with service availability in recent months as traffic on the platform has surged, driven in large part by AI-assisted coding and agentic development workflows. The code-sharing site has been trying to address those issues by expanding capacity and migrating more workloads to Azure infrastructure, but reliability remains uneven. In the May 2026 GitHub Availability Report, GitHub acknowledges nine incidents that degraded performance, one fewer than its April report. That's something. But Jakub Oleksy, SVP of software engineering at GitHub, says there's more to be done. "We are making structural changes that permanently remove failure modes," he said in the report. "We acknowledge that we have work to do, but we’re committed to getting it done and making GitHub reliable when and where you need it." Microsoft’s code hosting site also briefly halted new Copilot subscriptions to reduce the cost impact of its AI services and to adjust its Copilot pricing to account for shifting model provider policies. As noted in an April post, GitHub had planned to increase its capacity by 10x back in October 2025, but by February 2026 it had become evident that a 30x expansion would be needed to accommodate the surge of pull requests, commits, and new repos. Last year, GitHub reportedly handled 1 billion commits for the entire year. Now it receives 1.4 billion commits every month. “We’re now serving 40 percent of monolith traffic from Azure (up from 8 percent in February), with Git traffic at 30 percent and repository replication at 99 percent,” said Oleksy. “We’ve more than doubled our effective capacity in four months.” Oleksy notes that efforts to isolate GitHub’s primary database cluster by moving users, authentication, and authorization into separate domains should prevent failures that cascade across the system. That hasn’t quite solved GitHub’s ongoing availability challenges, in part because Azure has also confronted capacity problems recently. There were nine incidents in May compared to 10 incidents in April. And June is on pace for a similar number. The Missing GitHub Status Page, an unofficial project to track GitHub service problems, counts 12 incidents in May and reports uptime over the past 90 days at 87.26 percent. By month, the project puts GitHub availability at 78.33 percent in April, 93.86 percent in May, and 88.39 percent for June so far. GitHub's Official Status Page presents a far more flattering view of availability, with uptime figures mostly around 99.9 percent for the listed services. These figures depend upon what gets counted and the duration of the disruption. GitHub’s own incident history page cites 26 incidents in April, 23 in May, and 12 to date in June. ®
MX Linux 25.2 is here, now with kernel 7.0 if you choose – although the Raspberry Pi edition still needs some work. MX Linux has been quietly turning into one of the Reg FOSS desk’s favorite distros for a few years now. It has a number of desirable attributes, and with version 25.2 released late last month, some of the slightly bumpier parts of the major upgrade to version 25 are getting smoothed out. We looked at MX Linux 25 in November last year, and reported that one of the niftiest features in previous versions had been lost. In MX 23 and before, you could choose which init system the OS used every time it booted up: so, for instance, you could normally run with the classic sysvinit, but if you needed to install something which demanded systemd, you could temporarily boot up with systemd as the init, install your app, and then switch back. In our testing, we’ve found that some things require Agent P’s Swiss Army Knife of a “System and Service Manager” to install, but once they’re in place on your computer, they will run quite happily without it. Alternatively, if it’s something you only occasionally run, you can start up with systemd only when you need it. The way that MX Linux did this no longer works on kernel 6.12 or above. So, in order to continue to offer a choice of inits at all, MX 25.0 made you choose at install time: either pick the systemd version, or the sysvinit version. (And if you wanted KDE Plasma, it was only available in systemd form.) MX Linux 25.1 fixed that with a new, different, switchable-init system. However, that made upgrading from 23 to 25 tricky, and after we tried it, the OS still worked, but the handy suite of MX Tools didn’t. These aren’t essential, but they significantly facilitate common adjustments and tweaks such as installing extra external apps, switching repositories and mirrors, managing kernel versions, installing additional device drivers such as the eternally problematic Nvidia drivers, and much more. They’re one of the distro’s key advantages, and well worth having. We dug out the machine in our test fleet, which runs MX, and tried the option in the installation program that installs over the top of an existing copy of MX. It worked fine, with some caveats: it’s not quite as capable as Ubuntu’s in-place reinstall, which spares your home directory while reinstalling the OS around it. MX simply overwrites the old OS; it doesn’t pick up any config from it – but it’s quicker and easier than custom partitioning. We had to re-enable our swap partition, and add a user account that matched the old one, but everything worked fine. With the MX Tools, it was fast and easy to choose local repositories for updates, and reinstall some handy proprietary apps such as Google Chrome and Slack. The distro comes with Flatpak preinstalled, and we used that to install Gear Lever to make it easier to reinstall Panwriter. The new MX Linux version 25.2 optionally includes the new kernel 7.0, from the Liquorix project that we looked at in 2022. For the Xfce edition, you can choose the normal edition, with a Debian kernel, or the AHS edition with the newer kernel. The KDE edition only comes in AHS form, and the lightweight Fluxbox edition for low-end kit only offers the Debian kernel. There are any number of Debian and Ubuntu based remixes and meta-distributions out there, but MX Linux is perhaps the single most user-friendly distro we’ve seen that isn’t based on systemd. It’s fast, lightweight, and much easier to get configured and installed than Devuan, or even than Debian itself. It also has better tools for adjustment and customization than any member of the Ubuntu or Debian family, and rivals the best Arch Linux-based distros such as Garuda Linux. As we reported from the Ubuntu Summit, Canonical is beginning a push into AI. Since then, the roadmap for Ubuntu 26.10 “Stonking Stingray” has been published, including what it calls a Context-aware desktop – powered by LLMs. Similar changes have already come to Linux Lite 8.0, which is based on Ubuntu 26.04. This too bundles a local LLM for all your error-filled artificial-plagiarism needs. We suspect that such developments may yet drive a small exodus of Ubuntu users – and if you also want to get away from systemd at the same time, then MX Linux is an excellent place to start. Bootnote: MX Linux on the Raspberry Pi Finally, version 25.2 sees the Raspberry Pi respin updated to the new base OS. Until 25.2, the Pi version was still on MX version 22. As this rather outdated description says, this is a separate edition of MX Linux with Xfce, but built in part from the packages in the Raspberry Pi OS rather than directly from Debian – so it looks and works like MX, but is compatible with most Pis and most apps for PiOS. For instance, the Pi configuration commands, and EEPROM updater, work fine on MX on the Pi, but they don’t on (for instance) Alpine Linux. We tried MX Linux 24.2 for the Raspberry Pi on both 4 GB and 8 GB Pi 5 machines and on a Pi 4, but it wouldn’t get past the splash screen for us – but the previous release worked very well, so once it’s received a little more TLC, this could turn out to be a good option for Pi users wanting a more configurable desktop OS. ®
Per accedere alle build di anteprima di Windows non è più obbligatorio utilizzare un Windows 11 Insider account collegato a Microsoft. Se per anni questa è stata una regola ferrea, oggi le cose sono cambiate.
Esiste infatti un metodo efficace per testare le novità del sistema operativo in anteprima, tutelando la propria privacy e mantenendo il pieno controllo del dispositivo. In questa guida ti mostreremo come fare, passo dopo passo.
Perché l'account Microsoft non è (davvero) obbligatorio?
Molti credono che il programma Insider si basi su una complessa infrastruttura cloud per verificare l'identità del PC. In realtà, il meccanismo è molto più semplice. Il funzionamento di Windows Update dipende da parametri impostati a livello locale. Una volta configurato, il sistema si "autodichiara" parte di un canale Insider e richiede gli aggiornamenti specifici, senza che le verifiche online siano così stringenti. È proprio sfruttando questo principio che la soluzione che stiamo per analizzare riesce ad aggirare l'obbligo dell'account.
OfflineInsiderEnroll: la soluzione a portata di script
La chiave per sbloccare l'accesso alle build di anteprima si chiama OfflineInsiderEnroll. Si tratta di un semplice ma potente script disponibile su GitHub che automatizza le modifiche necessarie al registro di sistema. È uno strumento pulito: non installa driver, servizi permanenti o componenti che restano attivi in memoria. Esegue il suo compito e nient'altro.
Come funziona nel dettaglio?
Il cuore del meccanismo risiede in un valore del registro di sistema chiamato TestFlags. Impostando questo valore su un codice specifico (0x20), lo script comunica a Windows di interrompere le verifiche con i server Microsoft per la validazione dell'iscrizione.
Di conseguenza, le impostazioni locali prendono il sopravvento e Windows Update distribuisce le build sperimentali senza ulteriori controlli. Per rendere l'operazione credibile, lo script imposta anche altre chiavi fondamentali, come BranchName e RingId, simulando in tutto e per tutto un'iscrizione legittima a uno dei canali Insider.
Non solo un windows 11 insider account: i vantaggi nascosti
Uno degli aspetti più interessanti di questo strumento è la sua capacità di andare oltre la semplice iscrizione. Analizzando il codice, si scopre che lo script imposta in automatico anche le chiavi di registro per bypassare i famosi controlli hardware di Windows 11. Questo significa che potrai ricevere le build Insider anche su computer che non soddisfano pienamente i requisiti ufficiali, come la presenza del chip TPM 2.0 o di una CPU recente, garantendo una flessibilità notevole.
Guida pratica: come usare lo script passo-passo
L'utilizzo dello script è incredibilmente intuitivo e non richiede competenze tecniche avanzate. Segui questi semplici passaggi: Scarica l'ultima versione di OfflineInsiderEnroll dalla pagina ufficiale su GitHub. Fai clic con il tasto destro sul file .cmd scaricato e seleziona "Esegui come amministratore".
Si aprirà una finestra del prompt dei comandi con l'elenco dei canali Insider disponibili (Canary, Dev, Beta, Release Preview). Digita il numero corrispondente al canale desiderato e premi Invio. A questo punto, lo script applicherà le modifiche e ti chiederà di riavviare il computer. Al riavvio, vai su Impostazioni > Windows Update: troverai la nuova build di anteprima pronta per essere scaricata.
Ci sono rischi? Cosa devi sapere prima di iniziare
È importante essere trasparenti: ogni modifica non ufficiale al sistema operativo richiede consapevolezza. Sebbene lo script sia ritenuto sicuro dalla community, la sua funzione di ripristino potrebbe non annullare completamente tutte le modifiche apportate. Se in futuro decidessi di tornare a una versione stabile (retail) di Windows, la strada più sicura potrebbe essere un aggiornamento in-place tramite un file ISO ufficiale o, nei casi più complessi, una reinstallazione pulita del sistema operativo.
In conclusione, questo metodo non forza il sistema, ma sblocca semplicemente una via d'accesso già prevista. Dimostra che molte limitazioni sono spesso frutto di scelte strategiche e non di insormontabili vincoli tecnici, offrendoti un nuovo strumento per esplorare il futuro di Windows alle tue condizioni.
Nuove vette per la discriminazione degli utenti Linux. Se infatti eravamo abituati alla poca considerazione, cosa dire di questa nuova frontiera in cui, apparentemente, gli utenti sono talmente pochi (il 30%) che se vogliono la versione Basic del software la devono pagare...
Un vero inedito!
OSM non è semplicemente una mappa online libera e gratuita ma un ricchissimo database geografico attorno al quale ruota un’infinità di progetti, App e iniziative.
Se si parla di mappe nella maggior parte dei casi si pensa alla mappa del navigatore, ad una cartina stradale oppure a un Atlante ma in realtà ci sono mappe di tipo diversissimo: carte nautiche, stradali, da escursionismo, turistiche, quelle che mostrano le caratteristiche fisiche di un territorio, quelle che ne mostrano i confini amministrativi e molte altre ancora. Tanta varietà dipende tal fatto che ognuna di queste mappe è concepita per un certo utilizzo specifico ed ha dunque interesse a evidenziare solo alcuni degli aspetti del territorio che prende in considerazione. Le mappe dei navigatori per automobili ad esempio non mostrano i sentieri su cui non è possibile andare in automobile mentre le mappe da escursionismo, al contrario, non riportano informazioni sui semafori. E’ giusto che sia così: una mappa che mostrasse tutti, ma proprio tutti gli elementi presenti su un dato territorio risulterebbe completamente inutile ed illeggibile: proviamo solo ad immaginare quanto sarebbe difficile pianificare un percorso tra Roma e Firenze su una mappa che indicasse ogni singolo semaforo, cartello stradale, idrante, cancello, sentiero, panchina, fontanella, cartellone pubblicitario, attraversamento pedonale, rivolo d’acqua, spartitraffico, tombino, numero civico, ringhiera, ecc…
Una mappa delle linee ferroviarie italiane.
Anche le mappe solitamente utilizzate dai principali navigatori per automobili, difatti, per quanto ci possano sembrare complete in realtà sono concepite per un utilizzo generalista e riportano solo una selezione di elementi. Difatti sono in grado di calcolare il percorso per raggiungere una città che sta a 200km di distanza ma nella maggior parte dei casi non sanno dirci se nei dintorni c’è una fontanella a cui abbeverarci. O ancora: sulle mappe digitali maggiormente utilizzate, zommando all’indietro per far stare l’intera penisola italiana nello schermo vedremmo comunque ben evidenziate le autostrade, ma a ben vedere se osservassimo davvero l’Italia da quell’altezza, ad esempio dall’ISS, le autostrade non si noterebbero affatto. Si tratta ovviamente di una rappresentazione grafica artificiosa, voluta perché quelle mappe sono state concepite per un uso stradale e dunque è stato scelto di enfatizzare quel dato. Le mappe digitali più note, essendo realizzate dalle big tech americane, sono principalmente interessate a fornire un servizio buono per un uso generico e con una caratterizzazione fortemente commerciale: Google Maps difatti ci può dire a che ora apre un centro commerciale di un’altra città ma non ci sa dire se nei dintorni c’è una panchina. Il carattere commerciale di un servizio di mappe online, dunque, è un elemento determinante nel tipo di informazioni che la mappa stessa riporterà.
Una mappa catastale contiene un sacco di informazioni utili, ma se vuoi recarti di persona sul lotto 582bis ti conviene usare una mappa stradale per orientarti
Che si tratti di mappe commerciali o meno tuttavia appare subito evidente un primo problema: per farsi un’immagine completa di un certo territorio è necessario utilizzare più tipi di mappe, ognuna delle quali ha una propria funzione specifica, una grafica distinta, utilizza simbologie diverse dalle altre, una diversa scala e presentare incompatibilità con le altre. Se si volesse fare un’escursione orientandosi con Google Maps per raggiungere in auto il punto di partenza ed un navigatore escursionistico Garmin per l’escursione a piedi, uno dei due potrebbe segnalare un parcheggio che l’altro non riporta o nomi di vie di campagna non corrispondenti.
L’Istituto Geografico Militare Italiano realizza mappe estremamente precise ma concepite per un tipo d’utilizzo che le rende inadatte ad esser usate come semplice stradario
Vi sono anche infinite esigenze particolari solitamente non considerate da chi realizza mappe commerciali: chi vola in deltaplano, ad esempio, spesso deve barcamenarsi tra mappe escursionistiche che indicano correttamente rilievi ed altitudini e mappe di diverso tipo ove invece è indicata la presenza di pali elettrici e cavi dell’alta tensione (dai quali i deltaplanisti voglion comprensibilmente stare alla larga). Riassumendo: se da un lato ricorriamo costantemente all’uso di mappe, dall’altro il panorama offerto dal ben vasto mondo della cartografia presenta diversi problemi:
Un’unica mappa completissima uguale per chiunque risulterebbe inutile ed illeggibile.
Ricorrere costantemente a mappe differenti può esser problematico ed a volte genera più interrogativi che risposte.
Le mappe commerciali, per loro stessa natura, non sono adatte ad esser impiegate per esigenze specifiche.
OPENSTREETMAP
Ecco dunque arrivare in nostro aiuto OpenStreetMap (abbreviato: OSM), che è qualcosa di estremamente più potente e completo di qualsiasi altra mappa digitale conosciuta. Prima di spiegare cosa la rende tanto unica vediamo velocemente quali sono le origini e la natura del progetto.
Nata nel 2004 da un’idea di Steve Coast, OSM cresce rapidamente per strutturarsi come una fondazione non a scopo di lucro con sede in Inghilterra e che ha come fine la creazione di un gigantesco database di dati geografici liberamente ed accessibili a chiunque gratuitamente. OSM difatti sposa in toto le filosofie del software libero e della libera circolazione delle informazioni (anche il software con cui OSM viene realizzato è a sua volta open source). Il progetto di OSM dunque consiste nel raccogliere ed elaborare costantemente un grandissimo numero di informazioni geografiche possibili facendole analizzare da una vastissima comunità di volontari ed armonizzarli in un unico database aperto. Tutti quegli elementi che, come detto prima, se mostrati tutti assieme renderebbero una mappa illeggibile (i singoli tombini, i tre gradini sul marciapiede, ecc), possono essere inseriti nel database OSM. Sotto molti aspetti il progetto OSM può esser definito come una sorta di “Wikipedia cartografica” anche se però vi sono delle differenze sostanziali: Wikipedia difatti è nota per esser spesso caratterizzata da problemi derivanti dal mito del “punto di vista neutrale” e dal fatto che le regole interne di Wikipedia sono spesso aggirate da gruppi che si organizzano appositamente per imporre le proprie posizioni politiche. OSM, al contrario, trattando dati geografici è molto meno soggetta a questo tipo di problematiche che tuttavia, anche se in forma più circoscritta, non mancano nemmeno qui (pensiamo ad esempio ai confini contesi tra nazioni in conflitto). In linea generale però le divergenze che possono verificarsi all’interno della comunità OSM sono più che altro di tipo tecnico e concettuale.
COME SI FINANZIA? OSM viene finanziata da donazioni da parte dei membri e di diversi enti, università ed aziende che, come vedremo, sono perfettamente conscie dei vantaggi che derivano dal poter utilizzare liberamente un corpus di informazioni geografiche vastissimo e sempre più preciso. Vigili del fuoco, protezione civile, pronto soccorso, associazioni umanitarie, università ma anche aziende come Amazon e Facebook utilizzano i dati di OSM a proprio vantaggio e dunque hanno un forte interesse a collaborare alla sua realizzazione o finanziarla.
DA DOVE OTTIENE I DATI E COME LI GESTISCE? Le fonti da cui OSM pesca i dati sono estremamente variegate: usa le mappe digitali fornite da diversi enti pubblici sparsi sul globo, mappe catastali, si fa consegnare i tracciati dei sentieri dai club alpinistici, raccoglie dati forniti volontariamente dagli utenti di alcune App, ottiene la concessione di dati satellitari e così via.
OSM raccoglie e unifica una moltitudine di dati di natura diversissima spesso provenienti da enti diversi: informazioni sui terreni, sui percorsi d’acqua, strade, segnaletica, numeri civici, informazioni commerciali ecc.
Tutti questi dati di natura e formato diversi vengono costantemente elaborati ed armonizzati nell’immenso database OSM da volontari che ne verificano la correttezza tramite strumenti software ed apportano manualmente correzioni e aggiunte. Si tratta, insomma, di un lavoro continuo e minuzioso estremamente complesso gestito con metodo e costante revisione: volontari esperti verificano la correttezza dei dati aggiunti dai meno esperti, ci sono forum di discussione, workshop periodici ecc.
DATI GEOGRAFICI VS. MAPPE
OSM come si è detto, non è banalmente una mappa bensì un database geografico. Che cosa vuol dire esattamente? Analogamente a quanto già esposto parlando dei Feed RSS e dei Frontend alternativi anche qui è necessario tener bene a mente la differenza tra un DATO e la sua RAPPRESENTAZIONE GRAFICA. Un dato è semplicemente un’informazione cruda, una stringa di testo nel database OSM in cui c’è scritto un valore. Per esempio “fontanella pubblica”. La sua rappresentazione grafica è il modo in cui questo dato viene mostrato sulla mappa. In questo caso l’icona di una fontanella che può essere grande, piccola, blu, rossa ecc. Ebbene, il concetto principale da tenere sempre a mente per capire cos’è OSM è che i dati e la loro rappresentazione grafica sono sempre separati. Che cosa comporta questo? Questa separazione permette di poter prendere esattamente gli stessi identici dati ma selezionarli e rappresentarli in modi diversi e, trattandosi di un database liberamente accessibile, ciò coinvolge innumerevoli siti ed App.
A sinistra i dati puri e a destra uno dei tanti possibili modi di rappresentarli
Facciamo l’esempio di due App o due siti di navigazione altamente specializzati: uno per vigili del fuoco ed uno per persone che si muovono in sedia a rotelle (come Wheelmap). Entrambe possono usufruire del database OSM ma la prima evidenzierà gli idranti, i sentieri, le altezze dei rilievi, le centraline elettriche, mentre la seconda evidenzierà marciapiedi, scalini, ostacoli e così via. Certi elementi presenti su una non verranno nemmeno mostrati nella seconda ed allo stesso modo certi elementi comuni possono esser rappresentati con diversa enfasi: dei gradini invalicabili per chi è in carrozzina potrebbero essere evidenziati con un grosso bollino rosso nella mappa pensata per gli spostamenti in sedia a rotelle ma senza particolare enfasi nella mappa per i vigili del fuoco che invece potrebbe segnalare con un colore diverso viottoli e stradine in cui non è possibile passare con i mezzi in dotazione. In sostanza, grazie al database OSM è possibile realizzare un numero infinito di mappe diversissime ed altamente personalizzate in base alle diverse esigenze ma i dati di tutte queste sarebbero sempre coerenti tra loro: non sarà mai possibile, consultando due mappe aggiornate e basate su OSM, che in una venga mostrata una nuova rotonda stradale appena creata e nell’altra no.
La stessa città vista nelle quattro visualizzazioni offerte da openstreetmap.org. Ognuna evidenzia i vari elementi in modo diverso e riporta informazioni assenti nelle altre
Le maggiori mappe digitali offrono al loro interno la possibilità di essere visualizzate in tre, quattro modalità diverse (anche su openstreetmap.org è possibile visualizzare la mappa in quattro modalità: standard, ciclabile, trasporti ed umanitaria) ma il database OSM permette di fare molto di più e realizzare un numero sconfinato di progetti impensabili per qualsiasi altra mappa esistente. Qualsiasi sito o App che utilizzi mappe commerciali come quelle di Google o di Apple mostrerà sempre e solo quella mappa lì, con quelle due-tre modalità grafiche che permette, coi suoi colori ed il logo sempre in evidenza.
Al contrario, poiché il database di OSM è scollegato dalla grafica usata, le mappe che ne utilizzano i dati hanno una grandissima varietà di aspetti ed è assai probabile che molte persone abbiano usato più volte mappe OSM senza nemmeno mai rendersene conto (in diversi casi si viene a sapere che la mappa è basata sul database OSM solo se si entra nelle preferenze).
Vorresti andare a piedi da Messina a Copenhagen? Waymarkedtrails usa i dati OSM per rendere maggiormente fruibili i percorsi che fanno per te! Nella mappa è mostrato solo l’indispensabile per orientarsi durante i tragitti.
Un ulteriore esempio per far comprender il meccanismo può esser questo: un’associazione interessata a promuovere escursioni di tipo storico può facilmente mettere sul proprio sito una mappa basata su OSM scegliendo di dargli un colore in scala di grigi, mostrare le linee isoipse (quelle che fan capire l’altitudine dei rilievi), far visualizzare i terreni ed i centri abitati rimuovendo le strade asfaltate, mostrare tutti gli edifici di carattere storico con un colore giallo ed i siti archeologici con un colore rosso. Sarebbe una mappa decisamente particolare che per esser realizzata da zero impiegherebbe un certo dispendio di energie ma OSM permette di realizzarla con relativa semplicità: basta selezionare il tipo di dati che interessano e poi decidere come mostrarli.
TheWeatherChannel usa mappe realizzate da MapBox basate sui dati OSM
Ma non finisce qui! Diversi enti ed aziende che realizzano autonomamente mappe proprie, spesso utilizzano parte dei dati di OSM. Le mappe di Apple, ad esempio, si avvalgono di molti dati OSM. Esri, e Mapbox, un importante fornitore di tecnologie cartografiche ed un’azienda che realizza mappe personalizzate, sono donatori OSM che ne utilizzano i dati ed anche per le proprie mappe.
NON C’E’ UNA “MAPPA OSM UFFICIALE”
Poiché solitamente v’è l’abitudine di considerare i dati e la loro rappresentazione come un tutt’uno, anche nel caso delle mappe vien spontaneo considerare il suo aspetto visivo come l’informazione in sè. Di conseguenza un errore comune in cui si può cadere è quello di ritenere che l’aspetto grafico delle mappe presenti su openstreetmap.org siano “LA mappa di OSM” Ma anche la mappa su openstreetmap.org, pur essendo realizzata da OSM stesso, non mostra tutte le informazioni geografiche del suo stesso database (come già detto, una mappa che mostrasse tutto-tutto-tutto sarebbe inguardabile) e pure i colori, le icone e i font che OSM ha scelto di mostrare su openstreetmap.org non sono un qualcosa di “fisso” (dati e rappresentazione sono due cose distinte).
Le diverse App Android che usano mappe basate sul database OSM. Molte di queste usano grafica, colori e icone proprie e diverse mostrano informazioni assenti nelle mappe visibili su openstreetmap.org
Su openstreetmap.org é stato deciso di rappresentare gli edifici con un colore grigio-marroncino, di rendere molto evidenti i binari ferroviari e le strade hanno colori diversi a seconda della tipologia. Ma se si osserva lo stesso territorio dall’App Maps.me, che utilizza a sua volta lo stesso database OSM, la grafica ed i colori son talmente diversi da farci credere che si tratti di tutta un’altra mappa: i binari ferroviari manco si vedono, le aree verdi sono molto marcate,le strade son tutte bianche ad eccezione delle Autostrade, gli edifici appaiono leggermente in 3D. I dati delle due mappe sono gli stessi ma Maps.me ha semplicemente scelto di usare quegli stessi dati in modo diverso, rappresentarli con un’altra grafica e usare informazioni che OSM ha scelto di non mostrare su openstreetmap.org (l’altezza degli edifici). Non c’è nulla di strano nel fatto che vi siano siti ed App che mostrano cose che sulla mappa openstreetmap.org non appaiono e può benissimo essere che si consideri migliore la mappa basata su OSM presente sul sito taldeitali perchè i quattro tipi di mappe visualizzabili su openstreetmap.org non sono “le mappe ufficiali di OSM” ma solo quattro delle migliaia di modi possibili di usare il database OSM. Siamo di fronte ad un concetto ben noto nel mondo del software libero a cui però il software commerciale ha disabituato: mastodon.social, l’Istanza Mastodon creata dall’inventore di Mastodon stesso, non è “l’Istanza ufficiale”; matrix.org non è l’istanza ufficiale di Matrix, non esiste una distribuzione Linux ufficiale e le quattro mappe di openstreetmao.org non sono le mappe ufficiali di OpenStreetMap.
UN GRANDE, RICCHISSIMO DATABASE GEOGRAFICO
A questo punto abbiamo diversi elementi per iniziare a comprendere meglio la ricchezza di OSM: ogni persona, ente o associazione che ha interesse ad avere delle mappe precise, tarate apposta per le proprie esigenze, coerenti con informazioni geografiche di diversa natura ed arricchite da osservazioni di migliaia di altri utenti può trarne vantaggio collaborando al database di OSM aggiungendovi i dati di proprio interesse. Il tutto viene integrato nel database OSM classificando i vari elementi per tipologia e secondo tutta una serie di criteri, andando così a formare diversi livelli gestibili autonomamente. E’ il principio seguito dai GIS (Geographic Information system), sigla con cui si identificano i principali servizi di mappatura digitale.
Manhattan su Google Maps
Manhattan sulla mappa standard di openstreetmaps.org. Appare immediatamente evidente la differenza in termini di ricchezza di informazioni e precisione
Qui Manhattan su Maps.me (App che usa i dati OSM). Maps.me è interessante perché sfrutta la qualità dei dati OSM ma la restituisce con la leggerezza visiva di Google Maps
All’interno del database si può segnalare veramente di tutto: le piazzole per i camper, i distributori pubblici di sacchetti per cani, sentieri non tracciati, WiFi pubblici, cancelli, inferriate, vicoli strettissimi che solitamente non vengono segnalati, i nomi locali delle campagne, tombini, capitelli, muretti diroccati, ruderi, sentieri abbandonati, gabinetti pubblici e mille altre cose ancora. Il tutto senza doversi preoccupare del fatto che tale informazione possa interessare solo a poche persone o che possa appesantire la mappa. Giusto per dare un’idea, qui e qui è possibile vedere alcune statistiche aggiornate sulla quantità di dati che contiene, qui e qui informazioni sull’hardware usato.
Una zona in Vietnam di cui OSM ne conosce solamente la rete stradale ed i fiumi principali.
Ci sono associazioni che inseriscono in OSM la posizione dei singoli alberi nei parchi pubblici, ciclisti che segnalano ogni singola fontanella o sbarra che impedisce il passaggio, c’è chi segnala i luoghi in cui si posizionano i banchetti di cibo da strada o i cantieri apparsi all’improvviso e così via. Il database di conseguenza accumula sempre più dati la cui ricchezza, va però notato, come per tutte le mappe online è distribuita a macchia di leopardo: se le zone più note, frequentate e di maggior interesse possono avere un grado di precisione elevatissimo ce ne sono altre che invece si limitano a mostrare giusto le strade e poco più.
UN ECOSISTEMA
Il database di OSM, essendo liberamente accessibile, è quindi il perno di tutto un ecosistema di App, siti e strumenti diversissimi che collaborano alla sua diffusione ed in alcuni casi anche al suo miglioramento: certe App, ad esempio, permettono a qualsiasi utente anche privo di esperienza di fornire segnalazioni minute come la presenza di un cantiere, o la rimozione di una panchina e così via. Una di queste, molto carina, che si chiama StreetComplete, gestisce questo processo con una forma di gamification sfruttata per una volta in modo positivo: una volta avviata mostra all’utente tutti gli elementi nelle sue vicinanze riguardo ai quali mancano alcuni dati, chiedendogli di completarli con semplici domande: come si chiama questo ristorante? Quanti piani ha questa casa? E così via… Ci sono anche siti ed App indipendenti che offrono servizi basati su mappe generate dal database OSM.
Mapillary offre un servizio simile a quello di GoogleStreetView. Nell’immagine si possono veder evidenziate in verde le strade già coperte
Una di queste, Mapillary, sta creando un database fotografico simile a quello di Google Street View ma prodotto dai singoli utenti che riprendono le strade coi propri smartphone. Queste fotografie non vanno a far parte del database OSM ma vengono tuttavia rilasciate con licenza Creative Commons CC-BY-SA, dando così la possibilità a chiunque di farne libero uso. I progetti autonomi sviluppati attorno ad OSM sono moltissimi: diverse mappe metereologiche e sulla pandemia Covid sono state fatte con le mappe OSM, le usano i dispositivi Garmin, pure le mappe di Apple son state realizzate attingendo al database OSM.
CentralineDalBasso riporta i dati sulla qualità dell’aria su mappe OSM
OSM è usato pure da numerose associazioni umanitarie per vari progetti e iniziative, tanto che esiste pure un team specializzato (HOT – Humanitarian OpenStreetMap Team) che coinvolge, da solo, oltre 170 mila partecipanti.
Healthsites usa il database OSM per tracciare una mappa di tutti gli ospedali, ambulatori e centri di cura.
…i progetti sono tantissimi e questi sono solo una selezione fatta al volo!
Su https://osm-analytics.org/ vengono visualizzate le informazioni immesse dall’ Humanitarian OpenStreetMap Team. In questo caso gli edifici di due villaggi del Mali, del tutto assenti nelle mappe digitali commerciali
LA GESTIONE DEL DATABASE
Come facilmente intuibile il database OSM, ricevendo aggiornamenti ogni minuto, non sta mai fermo. Ciononostante se visualizzi la mappa di una App o un sito basato su OSM non accadono situazioni tipo “Ops! E’comparsa una panchina all’improvviso!” e questo, giustamente, per diverse ragioni. Quando viene inserito un nuovo dato il database ha bisogno di qualche tempo per elaborarlo e verificare che sia una modifica coerente e non una castroneria tipo “Una montagna di 400 metri comparsa all’improvviso davanti al Duomo di Milano”. Dopodichè vengono fatte delle verifiche da parte dei volontari che controllano la sensatezza della modifica ecc. A seconda del tipo di modifica e della zona interessata questo processo può esser più o meno lungo: se si inserisce un “cancello con sbarra” su un sentiero di campagna in una zona poco frequentata questo verrà elaborato molto velocemente, ma se si correggesse ad esempio il tracciato di una strada stadale di grande percorrenza presso una località importante, la verifica ed eventuale discussione sulla correttezza di questa modifica potrebbe durare anche qualche giorno. In ogni caso, una volta accolta la modifica, il primo luogo in cui questa potrebbe esser visibile è ovviamente la mappa di openstreetmap.org (sempre a patto che sia un tipo di dato che tale mappa mostra). Dopodichè vengono gli altri siti ed App. Questi però non pescano subito i dati dal database principale ma hanno metodi e tempi molto diversi fra loro. Alcuni difatti utilizzano dei propri server in cui copiano il database OSM a cadenza periodica (ad esempio settimanale, mensile, trimestrale o come più gli va).
OsmAnd permette di scaricare offline le mappe OSM più aggiornate. Molte App commerciali invece tendono ad essere più lente nel recepire gli ultimi aggiornamenti
Questo gli permette di essere operativi ed avere mappe funzionanti anche nel caso in cui il server di OSM avesse qualche problema. Quando effettuano questa copia sui propri server in realtà non copiano davvero tutto ma solo la porzione di dati che gli interessa. Per esempio, una App per ciclisti britannici copierà solo i dati relativi alla Gran Bretagna che effettivamente usa. Acquisirà dunque gli aggiornamenti sui negozi di biciclette e sulle nuove piste ciclabili ma snobberà quelli su idranti, centraline elettriche, uffici postali, autovelox ed altre cose che tanto, nell’App, non segnala. Allo stesso modo questi siti ed App spesso evitano di copiare le modifiche più recenti seguendo il principio che i dati troppo “freschi” son stati visualizzati e verificati meno rispetto a quelli presenti da più tempo. Il risultato è che se oggi viene inserita una certa modifica, le App che si appoggiano direttamente al server di OSM la riceveranno istantaneamente mentre per le App che effettuano copie periodiche dei dati sui propri server potrebbe volerci addirittura qualche mese. Anche qui è una questione di scelte personali: meglio avere i dati più aggiornati col rischio di qualche incorrettezza o meglio dati meno aggiornati ma più certi?
MAPPE OFFLINE E SICUREZZA
Quando si consultano le mappe digitali di Google ed Apple, le rispettive App dialogano costantemente col server per comunicare istantaneamente la tua posizione e fornendoti la versione più aggiornata delle loro mappe. Pur esistendo la possibilità di salvare sul telefono alcune porzioni di mappa questo meccanismo è inevitabile: non si può usare le App di mappe commerciali se non si comunica la propria posizione e senza dialogare costantemente col server. Alcune App basate su OSM (non tutte) hanno invece un approccio diverso: al loro interno hanno solo una mappa-base del pianeta e lasciano all’utente la possibilità di scaricare sullo smartphone la porzione di mondo di cui vogliono avere la mappa dettagliata.
Alcune App “conoscono” solo le porzioni di territorio che hai scaricato sullo smartphone
In alcuni casi questo processo è manuale e bisogna selezionare la mappa del paese, regione o città che interessa da una lista, mentre in altri casi quest’operazione è semi-automatica (se zoommi sull’Abruzzo parte il download della mappa dell’Abruzzo). In altri casi ancora v’è un sistema misto (le mappe visualizzate sono quelle del server a meno che non le scarichi). In alcune App, ad esempio, si può scaricare una mappa generale dell’Italia che contiene solamente le strade principali e poi scaricarsi la mappa dettagliata di singole regioni o città che interessano. Ad esempio è possibile salvarsi offline la mappa delle strade dell’intera Italia, la mappa dettagliata della Sicilia e quella dettagliata di Roma. Su queste App gli aggiornamenti delle mappe scaricate oggline funzionano allo stesso modo: semi-automatico per alcune, manuale per altre e misto per altre ancora. Poter scaricare le mappe sul proprio dispositivo porta co sè diversi vantaggi, i primi dei quali sono l’essere accessibili anche se non c’è campo e non consumare costantemente banda per ri-scaricare sempre e solo le stesse strade. Poichè lo spazio su smartphone è quello che è non si avrà mai l’intero database OSM salvato, ma le App basate su mappe offline solitamente sanno gestire la cosa a dovere e se per il tuo viaggio hai necessità di salvarti la mappa dell’intera Romania ma non hai più spazio è del tutto indolore liberarne un po cancellando quelle di territori che non ti serve consultare al momento. Tra i vantaggi delle mappe offline v’è anche il fatto che sono solitamente più scattanti e possono essere consultate, navigate, si possono fare ricerche su di essa senza trasmettere mai a nessuno la propria posizione o informazioni su cosa stai cercando (se cerchi “Ascoli” su Google Maps la richiesta viene inviata ai server di Google che innanzitutto registrano che hai “cercato Ascoli alle 17.34” e solo dopo di ciò inviano la posizione di Ascoli al tuo smartphone). Con questo tipo di App invece si possono pure registrare i propri tracciati GPS nella certezza che questi saranno presenti solo e soltanto sul proprio telefono.
La preferenza per soluzioni offline però porta con sè anche qualche piccolo inghippo. Il primo è che gli aggiornamenti delle mappe scaricabili offline non sono sempre automatiche o ben segnalate ed ovviamente è un qualcosa a cui bisogna prestare una certa attenzione.
Il secondo riguarda il tempo che l’App può impiegare a calcolare i percorsi. Se si chiede a Google Maps di calcolare il percorso da Milano a Napoli, fondamentalmente l’App manda la richiesta ai server di Google i quali innanzitutto registrano che hai “cercato il percorso da Milano a Napoli alle 18.42”, poi effettuano il calcolo e restituiscono all’App il percorso consigliato. Il tutto in pochissimi secondi. Al contrario se si usa una App indipendente che fa fare questo calcolo allo smartphone senza comunicare nulla al server, da un lato non si regalano i propri dati in giro ma dall’altro questo ci metterà molto più tempo (il processore di uno smartphone è niente rispetto a quello di un grosso server). Su certe App, ad esempio, calcolare un percorso di 400Km può impiegare anche tre minuti. Anche qui è una questione di scelte: preferire una App scattante ma che comunica le proprie ricerche ad un server cui dobbiamo fidarci o una più solida ma lenta? Bisogna però considerare che una App che sa fare questi calcoli in proprio sarà autonoma anche nel bel mezzo di una grotta in fondo a un burrone in una valle sperduta in cui non c’è campo.
Il terzo inghippo riguarda la funzione “cerca” delle App, ma lo vedremo meglio più avanti.
IL GPS DI PER SE’ NON CI “TRACCIA”
Una domanda comune a questo punto riguarda il sistema GPS a causa di una certa confusione su come funziona questo sistema e vale dunque la pena spendere due parole per spiegare mooooolto grossolanamente come funziona. Il sistema GPS si basa su una trentina di satelliti geostazionari che circondano l’intero globo da una distanza di circa ventimila chilometri dalla superficie terrestre. Per geostazionario si intende un satellite che “staziona”, ossia che sta sempre fisso sopra lo stesso punto della Terra: se un satellite GPS fosse stato posizionato, per esempio, esattamente sopra la verticale di casa tua, questo resterebbe sempre lì, di notte e di giorno. Questi satelliti si trovano ad un’altezza tale che da ogni punto del globo sia sempre possibile “vederne” almeno tre, per esempio, osservando il cielo dall’Italia potresti vedere quello sopra casa tua, uno che sta sopra la casa di un tizio di Mosca ed uno che sta sopra un cinema in Islanda. Questi satelliti trasmettono costantemente dei segnali radio contenenti alcuni dati, i più importanti dei quali sono la sua posizione e l’ora esatta, con una precisione al microsecondo.
Laura, Mario e Andrea all’opera
Quando ti perdi nel bel mezzo della campagna ed apri una App per capire cove cavolo sei, questa riceve i segnali radio trasmessi dai satelliti esattamente come la radiolina da quattro soldi che becca sempre Radio Maria. L’App, quindi, riceve una roba tipo questa:
SATELLITE LAURA “Ciao! Sono Laura! La mia posizione esatta è XYZ e sono le ore 16:04:07…e 6 millisecondi“
SATELLITE MARIO “Ciao! Sono Mario! La mia posizione esatta è XYZ e sono le ore 16:04:07…e 23 millisecondi“
SATELLITE ANDREA “Ciao! Sono Andrea! La mia posizione esatta è XYZ e sono le ore 16:04:07…e 49 millisecondi“
L’App riceve tutti questi segnali contemporaneamente ma… il suo orologio interno indica le 16:04:07… e 52 millisecondi! Questa differenze di orario dipendono dal fatto che il segnale inviato da satelliti tanto lontani ci mette un po ad arrivare allo stesso punto. Non serve molto per capire che più il satellite è lontano e più ci mette. A questo punto l’App calcola molto velocemente la differenza microscopica tra gli orari e capisce di essere molto vicino ad Andrea, un po meno vicino da Mario e molto lontano da Laura. Di conseguenza, conoscendo le loro posizioni esatte (che han trasmesso) e la velocità di trasmissione delle onde radio, riesce a calcolare le proprie coordinate e mostrarle sulla mappa. Si tratta di un processo chiamato triangolazione.
Per chi volesse saperne di più, online ci sono diverse mappe live come questa che mostrano la posizione in orbita di migliaia di satelliti artificiali di tutti i tipi. Su F-Droid è pure possibile scaricare GPStest, una curiosa App che elenca tutti i satelliti che il tuo smartphone sta rilevando in questo momento (e si, quello sopra casa tua lo becca SEMPRE).
Capito il meccanismo appare chiaro che un ricevitore GPS, in questo caso il tuo smartphone, per funzionare non ha bisogno di trasmettere niente a nessuno riguardo alla tua posizione! Quando si parla di localizzare qualcuno tramite il suo GPS non si intende certo che il suo smartphone comunichi la propria posizione ai satelliti (A Laura, Mario ed Andrea non gliene frega una cippa di dove tu sia) ma significa che lo smartphone sta inviando -via Internet- quelle coordinate che ha calcolato grazie ai segnali che ha ricevuto dai satelliti GPS. I navigatori da auto stand-alone tipo i TomTom o i Garmin da escursionismo difatti sono anch’essi ricevitori GPS eppure non si è mai sentito dire che si possa “rilevare la posizione” di un TomTom o di un Garmin. Questo può essere verificato facilmente anche provando ad utilizzare una App che funziona con mappe offline e verificare la propria posizione GPS con la modalità aereo attivata.
MANCANZE e “MEH”
A parte le valutazioni su pregi e difetti delle App che usano mappe e calcoli di percorso offline (che non sono dei difetti ma osservazioni su pro e contro di certe caratteristiche), al’ecosistema stesso di OSM è caratterizzato da alcune mancanze che fanno particolarmente sentire, soprattutto nel fare un paragone con gli strumenti commerciali.
I MODULI DI RICERCA La prima mancanza che si riscontra quella di un ricerca interno efficiente. openstreetmap.org usa un certo software di ricerca e le App basate su OSM ne usano degli altri ma tuttavia il problema è abbastanza comune: è estremamente facile NON trovare quel che si cerca. In linea generale si può dire che più l’App è specializzata (per esempio una App dedicata solo agli spostamenti in automobili) e migliori sono i risultati, ma non è una regola che vale sempre. Giusto per fare due esempi, L’App Maps.me, pensata principalmente per viaggi turistici, ha un modulo di ricerca abbastanza intuitivo e veloce mentre al contrario, OsmAnd, che è una eccezionale App multifuzione opensource, ha un modulo di ricerca che necessita un po di pratica per esser appreso. In nessun caso però si arriva all’immediatezza del modulo di ricerca di Google Maps. Le capacità predittive di Google nel capire che se digiti “Parigi” è più probabile tu stia cercando la capitale francese che non una oscura “via Parigi” di una città vicina, da questo punto di vista è decisamente più efficiente rispetto alle altre soluzioni disponibili.
openstreetmap.org elabora in pochi secondi tragitti intercontinentali, ma se sbagli e scrivi Vladivostock col “ck” finale, è convinto tu voglia visitare uno stagno a qualche km. da Parigi
Le varie App rispondono a questa mancanza con diverse strategie: quelle specialistiche riescono a starci dentro perché gestiscono una quantità di informazioni minori e sono usate per scopi mirati; quelle più complesse, come OsmAnd, dovendo gestire una quantità di informazioni elevata utilizzano dei moduli di ricerca in cui l’utente deve compilare diversi passaggi. Per fare un esempio: su Google Maps, digitando anche malamente “via cavur roma”, il modulo di ricerca comprende comunque che si sta cercando Via Cavour a Roma e lo propone come prima soluzione. Per trovare la stessa via su OsmAnd è necessario:
saltare il modulo di ricerca base
selezionare “indirizzo”
selezionare “prima specifica la città”
digitando correttamente “Roma” le prime soluzioni proposte sono le località più vicine alla propria posizione che contengono “Roma” nel nome (Campagnano di Roma, Casa Roma, Chiarano Roma). La città di Roma, nel mio caso, è in quarta posizione
tornare indietro su “indirizzo”
digitare correttamente “via Cavour”
Dopo un po che ci si fa l’abitudine a fare tutti questi passaggi ci si mette un nonnulla ma resta il fatto che non c’è paragone con la semplicità del modulo di ricerca di Google.
In altre App e siti le ricerche funzionano benissimo a patto che nomi ed indirizzi siano indicati esattamente come vogliono loro (p.es. prima il nome della via, poi una virgola ed invine il nome della città. O il contrario). Insomma: effettuare le ricerche sulle proprie App non è proprio immediato ed è un campo che necessita certamente di miglioramenti.
A questa difficoltà va a sommarsi nuovamente la questione delle mappe offline: se sul tuo smartphone hai scaricato solo la mappa d’Italia e cerchi una via di Londra, l’App magari conoscerà Londra ma non troverà la via se prima non ne scarichi la mappa. Pare scontato, ma se si ha l’abitudine di usare le mappe di Google può non essere così immediato. Tutto ciò può risultare anche abbastanza antipatico perché se si dovesse ad esempio fare una ricerca sulla località chiamata Fauske senza sapere se sta in Svezia, Norvegia, Finlandia o Islanda non si potrebbe ottenere quest’informazione dall’App di mappe, ma bisognerebbe cercarsela sul web e solo dopo aver scoperto che sta in Norvegia si potrà tornare sull’App e scaricare la mappa corretta in modo che l’App stessa la possa trovare.
NIENTE TRAFFICO La seconda mancanza riguarda le indicazioni del traffico live. Semplicemente non ci sono, ne su openstreetmap.org nè sulle App per OSM. Aggiungere questo tipo di dati non è tecnicamente difficile ma l’ostacolo principale è che le informazioni sul traffico perlopiù devono essere acquistate, non sono di libero accesso ed in alcuni casi vengono ottenute dalle big tech anche carpendo dati dalla posizione degli smartphone degli utenti. Insomma: non se ne fa niente.
3D La terza ed ultima mancanza è quella di una mappa in rilievo paragonabile a quella di Google Earth. Il database OSM contiene i dati altimetrici di terreni e rilievi così come le altezze di numerosi edifici, ma solo alcune App proprietarie, al momento, li sfruttano in modo utile. Diversi sviluppatori stan portando avanti progetti collaterali ad OSM per renderne le mappe in 3D e l’argomento è “caldo” ma attualmente non v’è ancora nulla di utilizzabile da semplici utenti.
Uno dei tanti progetti intesi a dare tridimensionalità alle mappe OSM
“MEH” Non proprio un punto debole ma piuttosto un “meh” da rilevare è che le informazioni sugli esercizi commerciali sono tendenzialmente più complete sulle mappe di Google. Non è solitamente un problema ma in alcuni casi può risultar antipatico dover uscire da OSM, fare una ricerca altrove e poi rientrare in OSM. Ovviamente non c’è nulla che impedisca di aggiornare i dati di tutte le attività commerciali su OSM ma poichè il mercato è Google-oriented è lì che i mercanti vanno a parare.
Un secondo, debolissimo “meh” è che in alcuni casi sarebbe apprezzabile veder convergere su openstreetmap.org alcune funzioni offerte dai progetti che gli ruotano attorno. Un esempio tra questi è Mapillary, il servizio simile a Street View. Se si naviga una mappa su openstreetmap.org e si volessero vedere le immagini a livello strada di una certa zona bisogna andare su mapillary.com, tornare nuovamente sulla stessa zona e lì si potrebbero vedere queste immagini. Questa convergenza tuttavia viene ottenuta da alcune App. Sulla già citata OsmAnd, per esempio, basta un comando per visualizzare le foto di Mapillary.
VOGLIO CONTRIBUIRE!
Se a questo punto, ci si sentisse dentro un irrefrenabile impulso di contribuire ad OSM mappando a più non posso è sufficiente iscriversi su openstreetmap.org ed iniziare a frequentarne i forum, leggere la wiki, prendere dimestichezza col suo funzionamento e chiedere consigli alla sua community.
Un editor di OSM
Questo articolo è giusto una panoramica su cos’è OpenStreetMap e sulle sue potenzialità ma per quanto riguarda il lavoro che c’è dietro è decisamente meglio chiedere direttamente a chi si occupa attivamente della sua gestione. L’unico consiglio che si può dare qui, semmai, è di farci un po un giro prima di modificare la mappa di Milano e indicare che è apparsa una montagna davanti al Duomo, ecco.
LE APP BASATE SU OSM
E per finire non si poteva che segnalare le App che usano mappe basate sul database OSM. Ce ne sono diverse decine tra cui scegliere ed alcune sono abbastanza particolari e molto specifiche. Essendoci quindi un po di tutto, prima di pigliare App a caso forse è meglio fare una prima breve riflessione sull’utilizzo che se ne vuol fare e delle situazioni in cui ci capita di aver bisogno di una mappa: spostamenti in auto? Viaggi all’estero? Escursionismo? Ciclismo? Deve poter registrare i tracciati GPS, esportarli ecc? Deve poter permettere di segnalare modifiche ad OSM? Che tipo di dati si preferisce visualizzare? Meglio una App che fa di tutto ma complessa o una che fa poche cose ma che sia chiara e semplice? Può valer la pena usare due App per due tipi di utilizzo distinti? In ogni caso, sia per Android che iOS le due App più note sono le già segnalate OsmAnd e Maps.me
OsmAnd è un vero e proprio coltellino svizzero: fa TUTTO! Navigatore vocale per auto, modalità escursionismo, registra i tracciati con le statistiche altimetriche, integra Mapillary, permette di visualizzate le mappe in innumerevoli modi e tantissime altre cose. Tanta ricchezza ovviamente significa alto grado di complessità e di conseguenza richiede un certo “addestramento” per esser usato al meglio, ma una volta fatto proprio diventa uno strumento insostituibile! E’disponibile anche su F-Droid.
Maps.me è pensata per viaggi turistici. E’molto leggera e le mappe che usa hanno una grafica leggera che ricorda quella di Google Maps ed è adatta a chi ha bisogno di un navigatore facile da usare e senza fronzoli. Su F-Droid è presente un suo fork (una “versione modificata”) chiamata semplicemente Maps.
Navit è concepito puramente come navigatore automobilistico e può essere installato su diversi dispositivi.
OsmAnd e Navit sono software completamente liberi ed open source mentre Maps.me, pur essendo open source, è collegato ad una azienda che si occupa di viaggi. La versione su F-Droid chiamapa Maps invece è “pulita”.
Le altre App, come detto, sono diverse decine e ve n’è di tutti i tipi. Questi due link portano a pagine della wiki di OSM in cui vengono descritte una ad una e confrontate fra loro (in inglese):
OsmAnd ed altre App permettono di fare piccole segnalazioni ad OSM, ad esempio per indicare che una certa strada è stata chiusa, ma se si volesse fare qualcosa di più anche da smartphone esiste Vespucci, una App pensata appositamente per i volontari di OSM. E’però consigliabile usarla solo se si ha già un minimo di esperienza nel modificare i dati OSM da desktop.
Chi volesse dare una mano ad aggiornare i dati OSM ma senza dover imparare a modificare le mappe ed aggiornarle può contrinuire usando StreetComplete! Si tratta di un’App carinissima che, una volta avviata, pone delle semplici domande riguardo alla zona in cui ti trovi e su cui OSM ha informazioni incomplete. E’ un modo molto intelligente ed utile di sfruttare alcuni elementi della gamification per realizzare un progetto da cui ne trae vantaggio il mondo intero!
Accedere a YouTube, Twitter, Instagram o altri siti ancora attraverso App non ufficiali o coi cosiddetti Frontend alternativi permette di avere funzioni aggiuntive e di fruire dei contenuti in forme meno gamificate e stressanti.
Per capire cosa sia un Frontend basta aver ben chiari un paio di concetti, il primo dei quali è la distinzione tra la forma (design) ed il contenuto di un qualsiasi sito, piattaforma o applicazione. Prendiamo l’esempio di YouTube. Sostanzialmente YouTube è un archivio digitale di video ad ognuno dei quali è abbinata una serie di dati accessori (i like ricevuti, il conteggio visualizzazioni), oltre ad una componente social ed alcune funzioni di riproduzione (la barra di avanzamento, i sottotitoli, ecc.). Tutto questo ci viene mostrato con un certo DESIGN a cui siamo comunemente abituati, ossia questo:
Schermata di YouTube
Il suo aspetto ci è tanto familiare che lo identifichiamo immediatamente con il look di YouTube: il pulsante play al centro del video, la barra di scorrimento rossa in basso, i video suggeriti in quella certa posizione dello schermo, i colori bianco rosso e nero… Sono tutte caratteristiche estetiche distintive di YouTube.
Tuttavia, se un domani il team di Google decidesse di apportare piccoli cambiamenti come spostare la barra di scorrimento sulla parte superiore del video o cambiarne il colore dal rosso al blu, nella sostanza YouTube resterebbe YouTube ed il suo ricco archivio video non sarebbe intaccato da questi cambiamenti estetici. YouTube resterebbe tale anche se le modifiche fossero più profonde o se il design venisse completamente ridisegnato: il cambiamento della forma difatti non ha direttamente a che fare coi contenuti. E’ la stessa cosa che avviene in quelle applicazione e piattaforme che permettono di “cambiare il tema” anche se di solito questo cambiamento consiste solo nel passaggio da un certo design in versione chiara allo stesso design in versione scura. Concettualmente tutto ciò non è troppo diverso dal cambiare cover al telefono: l’aspetto cambia ma il telefono ovviamente resta lo stesso. Bisogna però osservare che certi tipi di cover hanno caratteristiche che le rendono qualcosa di più che un mero gingillo estetico: ci sono le cover antiurto, quelle con batteria di supporto incorporata, quelle con scomparto-portafoglio e quelle con lo stand integrato per tenere lo smartphone in verticale. Insomma: un cambio di cover è sempre un cambiamento di design ma alcuni design portano con sè anche funzionalità che cambiano l’approccio al dispositivo stesso.
A seconda del tipo di cover usata, lo smartphone può esser usato in modi diversi
Chi muoveva i propri passi sul web tra la fine degli anni ’90 ed i primi anni ‘2000 ricorderà Winamp, un lettore di file audio paragonabile a VLC che offriva la possibilità di personalizzare in maniera profonda il proprio design proponendo delle “skin” talmente diverse l’una dall’altra da non farla più sembrare la stessa applicazione. Con una skin minimalista si potevano avere a disposizione solo i comandi base lasciando che quelli più avanzati fossero sepolti nei menù interni. Oppure si poteva preferire una skin che metteva in primo piano le funzioni più tecniche come l’equalizzatore, la navigazione tra le tracce e così via.
Quattro diverse skin di Winamp. Design completamente diversi, ma è sempre la stessa applicazione
Quel che risultava maggiormente interessante é che alla modifica di design corrispondeva anche un profondo cambiamento nell’approccio allo strumento stesso da parte di chi lo utilizzava.
Ciononostante, soprattutto per via di scelte commerciali, nelle applicazioni si è sempre più imposto l’utilizzo di design rigidi e non personalizzabili dove tuttalpiù viene concessa la scelta tra tema chiaro e tema scuro di cui si è detto prima. Questa rigidità porta in effetti alcuni vantaggi (un certo pulsante appare a chiunque in quella stessa posizione, quella voce di menù si trova sempre lì e l’applicazione rimane sempre riconoscibile a chiunque indifferentemente dal device utilizzato). Al tempo stesso però questa rigidità impone un unico modo di fruizione dei contenuti stabilito da chi detiene la proprietà della piattaforma stessa. Al tempo stesso questa rigidità contribuisce a impedire che gli utenti possano compiere alcune azioni malviste dalle company che detengono la proprietà del sito.
Per fare qualche esempio: YouTube non permette di scaricare i suoi video e chi volesse farlo dovrà usare strumenti esterni; YouTube ha una funzione che permette di modificare la velocità di riproduzione dei video e che in certi casi può esser molto comoda m il pulsante per regolarla è all’interno del menù Preferenze e questo fa sì che molte persone nemmeno sappiano che esiste. Se il design di YouTube fosse diverso e mettesse più in evidenza questa funzione, questa sarebbe certamente più utilizzata. YouTube impone che prima della visione di un video ci si debba beccare la pubblicità ed impone che il pulsante “salta” appaia solo dopo un certo numero di secondi. Al contrario, se il design di YouTube fosse diverso, il pulsante “salta” potrebbe essere disponibile sempre o, addirittura, si potrebbe accedere direttamente al video che ci interessa senza doversi sorbire la pubblicità (ok, ok, ci sono dietro ragioni economiche, si, ma qui il discorso è puramente tecnico).
Giusto per rimarcare ulteriormente il fatto che i contenuti sono distinti dal design, si può osservare come potrebbe apparire YouTube se fosse “nudo” ossia dati puri senza alcun fronzolo grafico. Apparirebbe più o meno così:
Se si accede a YouTube da Terminale, il suo archivio appare come una enorme ma semplicissima playlist testuale i cui video vanno visti con un player installato sul proprio computer
Sarebbe solo un archivio testuale navigabile da linea di comando a cui si avrebbe un accesso diretto, senza commenti, pubblicità, suggerimenti di Google ecc. Pulito e preciso, si, ma di certo non molto comodo…
Frontend alternativi
Se si volesse accedere ai contenuti di un sito con un’interfaccia diversa da quella standard capace di offrire anche funzioni in più o in meno rispetto al solito (e senza arrivare al punto da accederci da linea di comando), quel che fa per noi è un Frontend alternativo!
I Frontend alternativi non sono altro che delle piattaforme con un design tutto loro che visualizzano e gestiscono i contenuti che stanno su un server/sito/database gestito da qualcun’altro. Si tratta di un qualcosa con cui abbiamo a che fare tutti i giorni: chi usa aggregatori di notizie, ad esempio, riceve contenuti realizzati dai maggiori quotidiani e blog ma su una applicazione che li parifica applicando a tutti lo stesso font, gli stessi sfondi, dimensione dei titoli ecc. Chi usa Media Center come Kodi ha accesso ai contenuti di YouTube ma sul Media Center non vede i commenti, i comandi sono un po diversi ecc. In sostanza tutte le volte in cui si accede a dei contenuti da una piattaforma diversa da quella standard, siamo dinnanzi allo stesso concetto. Tuttavia quando si parla di “Frontend” solitamente si intende un tipo di piattaforma ben precisa ovvero un sito web specializzato nel gestire i dati provenienti da un altro sito web. In pratica: per accedere ai contenuti del [SITO ORIGINALE] si andrà invece sul [SITO FRONTEND] che mostra gli stessi contenuti del [SITO ORIGINALE] ma in forma diversa.
Video visto su YouTube
Lo stesso video di prima visto su Invidious
Frontend alternativi per ogni cosa?
Dunque possono esistere Frontend alternativi per ogni tipo di piattaforma? Frontend per Instagram, Facebook, Skype e così via?
NO
E’possibile realizzare un frontend solo a patto che i contenuti ‘pubblici’ della piattaforma che ci interessa siano veramente pubblici: più il sito originale è aperto ed accessibile e più è facile realizzarne un Frontend. Per questo motivo ci si può scordare di frontend per Facebook, che è una gabbia dorata/drogata ermetica e chiusa perlopiù inaccessibile a chi non accetta di consegnare tutti i propri dati personali. Per alcune piattaforme commerciali invece é possibile creare dei Frontend alternativi che se da un lato offrono alcune funzioni in più, al tempo stesso non possono svolgere tutte le funzioni base. Al contrario è facile elaborare Frontend alternativi per tutte le piattaforme libere, aperte ed open source, allo stesso modo con cui è facile realizzare applicazioni alternative per le stesse.
Giusto per fare due esempi, sia Matrix che Mastodon sono accessibili tramite un certo numero di Frontend alternativi,App e software per PC. Questo tipo di varietà è abbastanza comune tra le piattaforme libere, così come la contaminazione vicendevole, poiché le idee vincenti di un Frontend possono esser poi riprese da un altro ecc. Al contrario, chi utilizza piattaforme commerciali spesso non è nemmeno a conoscenza del fatto che è possibile utilizzare lo stesso ‘motore’ ma con una carrozzeria diversa e con funzioni aggiuntive.
URL e codice
Oltre alla distinzione tra design e contenuto v’è un secondo ed ultimo concetto da aver bene in mente per capire il funzionamento dei Frontend alternativi: la differenza tra URL e codice. Chi va sull’URL www.youtube.com non trova una banale paginetta statica con del testo e delle immagini fisse, ma un sito complesso che FA diverse cose. Sull’URL www.youtube.com difatti è presente del codice che permette di vedere un video, avviarlo, mandarlo avanti, metterlo in pausa, aggiungere i sottotitoli, regolare il volume ecc… Dire ‘codice’, quindi, non è troppo diverso che dire ‘software’.
Aprendo l’URL http://www.youtube.com quel che si carica sono centinaia di righe di codice
Il fatto che una pagina web contenga del codice che fa molte cose è forse scontato, ma proprio per questo troppo spesso si tende a non farci caso. Giusto a termine di paragone, chi ha potuto vedere l’evoluzione del web ricorderà forse che i primissimi video pubblicati online erano perlopiù dei file su una pagina statica che andavano scaricati sul computer e solo a quel punto potevano essere visti, offline, con un mediaplayer. Solo col tempo e l’avvento della banda larga chi realizzava siti web ha potuto inserire nelle pagine stesse il codice che permetteva di vedere il video direttamente nella pagina.
NB: le cose non stanno esattamente così e qui si sta semplificando moooolto grossolanamente giusto per far capire alcuni concetti base sperando che il dio-gattino degli hacker non lanci una delle sue solite maledizioni ;-P
Ogniqualvolta si va su un sito web, dunque, bisogna tenere bene a mente che aprendo un certo URL si caricherà sì una pagina che ha una certa grafica e colore ma anche tanto codice. Un Frontend alternativo, quindi, è un “pacchetto” che include design e codice e che non si limita ad apparire diverso da quello originale e a disporre in modo diverso le sue stesse funzioni ma permette addirittura di gestire i contenuti in modo del tutto diverso aggiungendo funzionalità inedite. Una cosa che i Frontend alternativi potrebbero fare ma non sempre ne sono in grado è porsi da filtro tra te ed il sito originale per limitare la raccolta di metadati della tua navigazione. Per questioni strettamente tecniche questa cosa non è sempre possibile. Se uno dei motivi per cui si ricorre ai Frontend alternativi è quello di limitare la raccolta dati su di sè, in linea generale si consideri che comunque il sito originale qualche dato personale se lo piglia.
Invidious
Di Frontend alternativi ne esistono di diversi tipi e per diverse piattaforme. Qui ne osserveremo dettagliatamente uno che funge abbastanza bene da modello per spiegarli un po tutti. Si tratta di Invidious, che è probabilmente il più noto dei Frontend alternativi per YouTube. Se un Frontend alternativo è un “pacchetto” di design e codice diverso da quello presente sul sito di riferimento, Invidious è un “pacchetto” diverso da quello che troviamo su youtube.com, ma… su che sito possiamo trovarlo?
Su più d’uno!
Invidious difatti è un progetto libero ed open source che viene messo a disposizione di chiunque lo voglia utilizzare per sè, mettere sul proprio sito, modificarlo, migliorarlo ecc. (il “pacchetto” contenente codice e design si trova qui ). Dunque non c’è UN sito Invidious ufficiale, ma diversi siti, ognuno dei quali ha il proprio URL e la propria versione personalizzata del “pacchetto” di Invidious. Ognuno di questi siti può esser definito un’ “Istanza Invidious”
Esistono diverse Istanze Invidious e non esiste un elenco completo. Qui ce n’è uno parziale. La più nota Istanza Invidious è la prima ad esser stata creata https://invidio.us/ , ma attualmente sembra un po lenta. Un’Istanza che risulta decisamente più scattante è invece https://invidious.fdn.fr/Il “pacchetto” di Invidious è liberamente personalizzabile e viene costantemente aggiornato e poichè ogni Istanza è libera di modificarlo è possibile che alcune abbiano rimosso alcune funzioni o che ne abbian sostituito la grafica con una tutta loro. E’anche possibile che un’Istanza usi una versione non aggiornata di Invidious e che certe Istanze siano più veloci e scattanti di altre. Insomma: è un panorama variegato.
Che cosa offre Invidious più di YouTube.com?
Uno dei principali vantaggi di quasi tutti i Frontend ed App alternative è che limitano o addirittura permettono di rimuovere molti elementi gamificanti. Invidious ad esempio permette di rimuovere tutti i commenti ai video e di impedire la riproduzione automatica così come nascondere i video suggeriti da Google. Oltre a questo rimuove tutta la pubblicità, permette di scaricare direttamente i video in diversi formati e qualità (anche .mp3) e permette di mettere in play solo l’audio in modo da poter ascoltare il video come fosse un podcast consumando pure meno banda.
Frontend ed App suggerite
I Frontend alternativi, ormai si sarà ben capito, non sono poi molto diversi da una App non ufficiale. Qui di seguito si segnalano sia Frontend che App cui vale la pena dare un’occhiata. Non sono tutte quelle disponibili ma una selezione di quelle più note e interessanti. Altre App possono esser trovate su F-Droid. Qui quelle per Instagram, quelle per Twitter e quelle per YouTube.
Per quanto riguarda altri Frontend alternativi la cosa è un po più complessa perché non sempre vengono chiamati in questo modo e per cercarli bisogna utilizzare termini alternativi come “hook”, “alternative url”, “web viewer”, “web client”. Per Instagram ad esempio ce ne sono tantissimi ma spesso si tratta di siti zeppi di pubblicità e che a differenza di quelli qui segnalati, non sono Istanze che utilizzano codice open source, per cui è meglio evitarli.
– Download dei contenuti in diversi formati e qualità
– Rimozione pubblicità
– Rimozione commenti
– Rimozione autoplay
– Rimozione suggerimenti di Google
– Possibile riprodurre anche solo l’audio
– Download dei contenuti appoggiandosi a siti terzi
– Rimozione pubblicità
– Di default i commenti non son mostrati
– Rimozione autoplay
– Rimozione suggerimenti di Google
– E’un player fighetto ancora in fase di sviluppo. E’ un po pesante ma ha il pregio di mostrare solamente i video senza commenti, voti, suggerimenti ecc.
– E’forse la più nota App open per YouTube
– Download dei contenuti in diversi formati e qualità
– Rimozione pubblicità
– Rimozione commenti
– Rimozione autoplay
– Possibile riprodurre anche solo l’audio
– Rimuove la pubblicità
– Non usa JavaScript ed impedisce a twitter.com di registrare i tuoi dati di navigazione
– E’molto più leggero e scattante di twitter.com
– Permette di usare Twitter con diversi temi, ad esempio quello di Mastodon
– Permette di salvare immagini, video e .gif
– Può generare il feed RSS di ogni account
– Permette anche a chi non ha un account di accedere a profili e post Instagram
– E’ più veloce di Instagram
– Permette di scaricare le immagini
– Rimuove la pubblicità
– Può generare il feed RSS di ogni account
– Accesso ai contenuti tramite nome account o URL di un post
La magia di Nitter: il design è quello di Mastodon ma è un account Twitter
UN “TRUCCHETTO”
Un semplice “trucchetto”. Di solito i Frontend alternativi usano gli stessi percorsi di dominio dei siti originali.
Per intenderci, se l’URL di un certo video di YouTube è:
La stessa cosa si dovrebbe ripetere anche per gli URL di Twitter ed Instagram nei relativi Frontend alternativi, sia che si parli dell’URL di un post che di quello di un account utente.
INTERAGIRE CON CHI SVILUPPA QUESTI FRONTEND
Chi avesse interesse ad interagire con chi si occupa dello sviluppo di alcuni di questi Frontend alternativi, sono disponibili alcune stanze Matrixdi discussione:
Per la maggioranza delle persone leggere le news su Internet significa due cose: apprenderle sui social o saltare di sito in sito per legger cosa v’é scritto. Nel primo caso l’approccio alla notizia é legato a doppio filo a commenti, boost e strategie social mentre nel secondo caso si tratta di un modo valido ma spesso altamente inefficiente perché ci si riduce a leggere uno o due siti di fiducia e poi basta.
Eppure da oltre vent’anni, esiste uno strumento presente in quasi tutti i siti che permette di ricevere sempre gli aggiornamenti dalle proprie fonti preferite in modo estremamente efficiente: i FEED RSS!
CONTENUTI ED ASPETTO SON COSE SEPARATE
Un sito di news, un blog o un profilo social sono fondamentalmente delle pagine web all’interno dei quali vengono pubblicati dei post.
A seconda della piattaforma questi post possono essere composti da materiali molto diversi: in un social come PixelFed ed Instagram un post contiene solo un’immagine; in PeerTube e YouTubeun post equivale a un video; in Mastodon e Twitter un testo breve. In un sito di news o in un blog ogni post é invece composto da una quantità di testo ed immagini che può essere anche molto corposa.
Quello che qui c’interessa però é il fatto che in tutti questi casi, ogni post é un elemento indipendente che può essere gestito singolarmente.
Non ci facciamo tanto caso, ma ogni singolo giorno facciamo esperienza di questo poter gestire indipendentemente i singoli post: se si vuol condividere un certo post non dici ai tuoi contatti di andare su un certo sito/profilo e cercarselo, ma gli dai il link diretto a quel post.
Ogni post, insomma, ha un suo indirizzo unico: un proprio link diretto.
Ma non c’é solo il link. Ogni singolo post può esser composto da più elementi (non necessariamente tutti):
1) Il proprio link
2) Data e ora della pubblicazione
3) Un titolo
4) Una breve introduzione o degli hashtag
5) Il contenuto testuale
6) Il contenuto multimediale (immagini, filmati, file audio)
Qui é necessario fare un piccolo sforzo per comprendere un concetto non proprio immediato, ossia che gli elementi che compongono il post sono indipendenti dal modo in cui vengono mostrati.
Cosa vuol dire?
Facciamo un esempio: se pubblichi un post su Mastodon o qualsiasi altro social, chi lo legge dal suo PC vedrà il post scritto con un certo tipo di caratteri bianchi su uno sfondo nero, all’interno di una celletta con sotto i pulsanti per rispondere, sopra ad un certo altro post e sotto a un altro ecc.
Chi invece lo leggesse da uno smartphone con una App magari lo vedrebbe con tutto un altro tipo di carattere, con dei pulsanti un pò più piccoli e diversi, con altri colori ecc. Magari nel post avevi pure aggiunto una foto ma chi lo legge da PC la vedrà sopra il testo mentre su certe App si vedrà sotto di esso!
Eppure il tuo testo é sempre lo stesso e tu non hai specificato né che caratteri dovesse apparire né la posizione della foto!
Una notizia del Sole24Ore così come si presenta nel suo feed
La stessa notizia dell’immagine precedente così come viene mostrata sul sito del Sole 24 Ore
Ciò avviene perché la piattaforma a cui hai inviato il post (in questo esempio un’Istanza Mastodon) non si limita a prendere il tuo post e mostrarlo sul proprio sito con quella grafica, quei caratteri, quell’impaginazione ma ne trasmette pure il contenuto “puro”, così com’é, solo testo e a parte i file multimediali, permettendo ad altri strumenti (App, browser) di ricevere quel che tu hai inviato e personalizzare a loro volta il modo in cui mostrarlo.
Questo permette di far sì che un articolo che sul tuo PC appare di 30 lunghissime righe, sul piccolo schermo verticale del tuo smartphone venga automaticamente reimpaginato in 80 righe molto più corte, che le immagini vengano riposizionate, ecc.
Dunque, se si é ben compreso che il contenuto é scollegato dall’aspetto con cui viene mostrato possiamo entrare nel vivo di questo post e parlare di quella tecnologia fantastica che é l’ RSS!!!
I FEED RSS
Come abbiamo detto, le piattaforme TRASMETTONO i contenuti. I modi e le tecnologie per farlo sono diversi (per esempio, le reti libere che compongono il Fediverso utilizzano una tecnologia di trasmissione chiamata ActivityPub) ma di fatto la quasi totalità dei siti web d’informazione utilizza uno standard chiamato RSS.
Logo RSS
Di fatto si tratta di un collegamento (può apparire come link, pulsante o file) in cui appaiono tutti i singoli contenuti di quel sito/blog/profilo, ma senza fronzoli né grafica, in un unico flusso di dati detto FEED.
Quasi ogni sito utilizza gli RSS ma non sempre lo dice con chiarezza. In alcuni siti é presente da qualche parte l’Icona RSS, oppure tra i menù é indicata la voce RSS o FEED. Alcuni siti d’informazione hanno delle intere pagine in cui forniscono decine e decine di feed (un buon esempio in questo senso é il Sole 24 Ore: il quotidiano presenta in una pagina specifica tantissimi contenuti diversi fra loro e dunque permette di pescare feed contenenti gli articoli specifici su un certo argomento). In altri casi il feed é proprio nascosto e bisognerà utilizzare diversi trucchi per scoprirlo. Certi browser mostrano nella barra dell’indirizzo l’icona RSS se rilevano un FEED, ma non li individuano sempre. Ogni browser comunque permette di installare al suo interno dei Plugin/AddOn/Estensioni (Qui quelli per Firefox) che eseguono questa ricerca in modo più approfondito.
Esistono decine e decine di Addon per gestire RSS su Firefox: molti servono per trovare i feed all’interno di un sito e molti altri servono ad usare lo stesso Firefox com un aggregatore (vedi sotto)
I FEED RSS messi a disposizione del pubblico a volte sono completi e contengono tutto il contenuto dei post, ma in molti casi, specie quando si parla di quotidiani, contengono tutto tranne il testo completo.
Qui però sorge spontanea una domanda: ma una volta che si é trovato ‘sto FEED uno che se ne fa?
Beh, con un FEED RSS si possono fare tantissime cose, in particolare inserirli in un Aggregatore RSS!
I FEED READERS: GLI AGGREGATORI DI NOTIZIE PERSONALIZZABILI
Un Aggregatore RSS (in inglese “RSS Reader”) é un programma dedicato alla gestione di questi flussi. All’interno di un Aggregatore ad esempio puoi inserire i FEED di tutti i blog che ritieni interessanti, ma anche dei quotidiani, siti, profili social, podcast ecc, suddividendoli in cartelle nel modo che ti pare più consono ed ogni volta che in uno di questi FEED apparirà un nuovo post, l’Aggregatore te lo notificherà.
In questo modo riceverai sempre tutti gli aggiornamenti diretti dai canali che t’interessano senza dover saltare da una piattaforma all’altra, passare di sito in sito…
Con un click puoi passare da un quotidiano all’altro e tutto ti verrà mostrato con uno stile unitario e senza i commenti, i likes e le stelline in modo da poter leggere i contenuti senza distrazioni o ansie social.
La tipica impostazione di un Aggregatore riprende quella dei client email: a sinistra (colonna grigia) i singoli feed suddivisi in cartelle, al centro l’elenco dei post del Feed selezionato ed a destra il contenuto del singolo post
Ogni Aggregatore ha stile e funzionalità proprie: alcuni permettono di salvarti i post preferiti, postarli direttamente dall’Aggregatore ai tuoi profili social ecc. Certi sono dei software da installare ed altri funzionano come servizi cloud. Certi possono esser fatti sincronizzare su più dispositivi. Certi trattano i feed come se fossero delle email, salvandoli tutti per la lettura offline, mentre altri li presentano come post di un social. Certi hanno al proprio interno dei motori di ricerca per andare a ritrovare quella certa notizia memtre altri non hanno alcun motore. Certi hanno già al loro interno i feed dei canali d’informazione più importanti. Certi si aggiornano di continuo e certi solo quando gli si dice di farlo.
Di Aggregatori, insomma, ne esistono dei più disparati! Qui di seguito un elenco di quelli più noti, in ordine sparso. NB: La maggior parte di queste applicazioni NON sono state testate da chi scrive e le descrizioni spesso riassumono solo quel che vien riportato da altre fonti.
Il tuo client email può gestire anche gli RSS. Qui Thunderbird
SU LINUX
FeedReader
Applicazione open source esteticamente piacevolissima con diversi collegamenti a Wallabag, Instapaper ed altri servizi di Bookmarking, ma soprattutto é perfettamente compatibile con altri Aggregatori per estendere le proprie funzioni.
Thunderbird
Poiché gli aggregatori gestiscono i FEED RSS come fossero email é naturale che i client email sappiano gestirli, no?
Akregator
E’un potente aggregatore open source per KDE che contiene al proprio interno un browser e dunque anche nel caso in cui di feed che non contengono il testo completo di un post, anziché esser mandati dall’Aggregatore al proprio browser, si potrà leggere tutto su Akregator
Liferea
Open source e web-based. E’considerato uno dei migliori e più utilizzati aggregatori su Ubuntu. Ha un’impostazione vecchio stile tipo email ma supporta podcast, lettura dei post offline ed altro ancora.
Selfoss
Aggregatore open source molto leggero e minimale ma dotato di diverse funzioni
TinyTinyRSS
TinyTiny é un aggregatore web-based open source. In pratica non é solamente una App ma un vero e proprio piccolo serverRSS installabile sul proprio PC o server. Un pò come per SearX ci sono diversi siti che mettono a disposizione il proprio servizio TinyTinyRSS
FreshRSS
Altro aggregatore open source web-based come TinyTinyRSS, con diverse estensioni disponibili.
OpenTICKR
A differenza degli altri aggregatori, OpenTICKR si presenta come una banda di news che scorrono sullo schermo un pò come quelle che spesso si vedono sotto la pancia dei conduttori nei telegiornali.
Sui device portatili molti Aggregatori cercano di offrire un’esperienza di lettura più “pulita” e uniforme rispetto a social e siti di news
SU ANDROID
(Su F-Droid sono tantissimi gli aggregatori disponibili! Perlopiù si tratta di versioni differenti di client per TinyTiny.
TinyTinyRSS
Client TinyTiny
TinyTinyRSS Reader
Altro client TinyTiny
Tiny Tiny Feed
Altro client TinyTiny
TTRSS-Reader
Altro client TinyTiny
NextCloud News
Interesante Aggregatore che si connette al proprio server NextCloud
OCReader
Altro aggregatore che si connette a NextCloud
Feeder
Aggregatore molto snello ed elegante ma con funzioni basiche
Sparse RSS
spaRSS DecSync
Equipe RSS
FreshRSS
Handy News RSS
NewsBlur
Reader for Selfoss
Another-RSS
Munch
MULTIPIATTAFORMA
Feedly
Aggregatore Freemium su cloud proprietario (i servizi base sono gratuiti e quelli avanzati a pagamento) che già nella versione gratis si presenta molto completo.
QuiteRSS
Altro aggregatore open source molto solido e dotato di diverse funzioni, tra cui browser interno, modulo di ricerca, possibilità di mostrare o nascondere sempre le immagini, adblocker.
CREARE BOT
I più smanettoni possono anche prendere un FEED RSS ed utilizzarlo per creare un BOT, ossia un account social che pubblica automaticamente i contenuti di quel FEED. Su Matrix ad esempio é semplicissimo: ogni utente può creare un BOT utilizzando un Widget fornito dalla piattaforma stessa!.
Logo OPML
ALTRE INFO UTILI SUI FEED RSS
ESISTONO PIU’ VERSIONI DI RSS
L’RSS é uno standard composto da diversi “dialetti” (ben nove!). Questo significa che a volte un sito potrebbe utilizzare un tipo di RSS che il proprio Aggregatore non interpreta bene, ad esempio potrebbe credere che la data ed ora di pubblicazione del post siano il titolo o altri errori simili. In realtà la maggior parte degli Aggregatori riescono a distinguere e gestire questi dialetti ma ogni tanto qualche errore lo si incontra ancora
ATOM
Altra cosa da conoscere é ATOM, che può essere descritto come uno dei “dialetti” dell’RSS che però si é evoluto molto. Anche per quanto riguarda Atom la maggior parte degli Aggregatori sa gestirlo senza problemi.
XML
Nota tecnica: RSS ed ATOM si basano entrambi su un’altro standard chiamato XML. Ecco perché spesso si incontrano FEED il cui indirizzo termina per .xml
OPML
Inserire tanti FEED uno ad uno in un aggregatore può essere un lavoraccio! Ciò comporta che se un bel giorno volessi cambiare aggregatore dovresti rifare tutto daccapo? No: per fortuna sulla maggior parte degli Aggregatori é possibile esportare ed importare diversi feed in un unico file. L’OPML é di fatto il formato standard con cui questa operazione viene svolta. Per questo motivo é sempre bene assicurarsi che l’Aggregatore che si sta adottando sia in grado di gestire questo tipo di files.
IN CONCLUSIONE
Un Aggregatore RSS ben organizzato e con diverse fonti si rivela uno strumento efficacissimo per riuscire a navigare nel flusso oceanico di notizie tagliando fuori tutto ciò che non é necessario, dai fronzoli grafici ai commenti social, permettendo di confrontare rapidamente diverse fonti su una stessa notizia e di approcciarsi ad essa senza aver addosso tutto il “rumore” generato dai social. L’importante é trovare l’aggregatore più adatto a sé e, soprattutto all’inizio, impostarlo con feed diversi provenienti da fonti diverse.
Mastodon continua a crescere. Alle soglie dei 3 milioni e mezzo di utenti si aggiungono continuamente nuove Istanze le quali, connettendosi o meno tra loro, contribuiscono a creare reti sempre più articolate all’interno del Fediverso. Le nuove Istanze (ossia server Mastodon indipendenti, ognuno dei quali con le proprie regole, caratteristiche e policy) sono per forza di cose diversissime tra loro ed hanno esigenze, approcci e idee su “come dovrebbe essere un social” spesso assai distanti tra loro, per non parlare dei temi che trattano. Di questi “nuovi arrivi” su Mastodon, due in particolare hanno fatto discutere molto negli ultimi mesi.
Il secondo, più serio, riguarda invece Gab, sul quale é necessario spendere qualche parola. Gab é un social network per nazifascisti nato negli Stati Uniti nel 2016 e che fin dalla nascita é stato raggiungibile oltre che dal proprio sito web anche da apposite App per iOS ed Android. Data la sua natura, i contenuti che diffonde, il suo utilizzo da parte degli organizzatori di Charlottesville ed altri disgustosi personaggi, Gab é stato fin da subito al centro di diverse polemiche che si son protratte fino al punto che qualche mese fa le sue App sono state rimosse dal Play Store e dall’App Store ed é stato rescisso unilateralmente il contratto che Gab aveva col suo fornitore di hosting (colui che affittava il server che reggeva il social).
Gli amministratori del social neonazista, dunque, lasciati a piedi e banditi da ogni piattaforma, si son trovati in condizione di dover trovare una soluzione alternativa che li rendesse indipendenti dai ban dei provider tecnologici. Ed hanno adottato Mastodon.
GAB E’ORA UN’ISTANZA MASTODON
Questa scelta, dal punto di vista degli amministratori del social neonazista, presenta soprattutto due enormi vantaggi:
1: anziché dover creare, aggiornare ed ottimizzare un proprio software da zero, gli admin di Gab possono avvantaggiarsi del lavoro open source degli sviluppatori e contributors di Mastodon. Questo perché essendo software aperto é liberamente utilizzabile e modificabile da chiunque.
2: invece di dover sviluppare e far approvare delle App specifiche per il proprio social, possono appoggiarsi a diverse altre App per Mastodon già esistenti e presenti negli App Store. App che non vengono bannate perché non specifiche per Gab: bannarle sarebbe come bannare un browser perché ti permette di accedere a siti neonazisti.
Al solito, come abituale strategia dei nazifascisti, il tutto é avvenuto negando la loro natura di nazifascisti e mascherando il loro desiderio di seminare odio e falsità invocando “libertà d’espressione”.
La nuova Istanza Gab é grossa; i suoi amministratori affermano addirittura di avere già oltre un milione di account anche se esiste il forte sospetto che molti di questi possano essere account fasulli creati per far apparire il network molto più grande di quanto effettivamente sia. Ma veri o falsi che siano i suoi account, in ogni caso Gab resta un’Istanza di dimensioni considerevoli.
Va pure ricordato che non si tratta della prima istanza neonazista che ha adottato Mastodon ma di certo é la più grossa, nota ed aggressiva.
GRIDI D’ALLARME
L’arrivo di Gab su Mastodon non poteva che generare scompiglio e curiosità: Mastodon si é caratterizzato fin da subito come uno strumento utile a creare ambienti molto favorevoli alle comunità LGBT, anarchiche e libertarie, per cui l’arrivo di Gab é stato visto soprattutto dal di fuori del Fediverso un po come una sorta di “fine dei giochi” per il progetto Mastodon (il che é un po’una costante: é da quando Mastodon esiste che alcuni commentatori colgono ogni occasione per dire che il progetto “é finito” nonostante in realtà continui a crescere costantemente)
In effetti, sapere che una certa piattaforma social é usata da un gran numero di nazifascisti suona decisamente allarmante e se non sai come funziona una rete federata il primo pensiero che viene a chiunque é star lontano da quel social. Da questo punto di vista la notizia dell’arrivo dei nazisti su ha portato indubbiamente cattiva pubblicità a Mastodon.
C’é però qualcosa che non torna in questo grido d’allarme (e chi già sa come funzionano Mastodon ed il Fediverso lo sa bene): giusto per fare un esempio, chi scrive, pur utilizzando Mastodon su base quotidiana, di Gab ed i suoi contenuti non ha mai visto manco l’ombra.
Per capire come ciò sia possibile é necessario fare un passo indietro.
NON ESISTE -UN- SOCIAL CHIAMATO MASTODON: CI SONO TANTE ISTANZE MASTODON CHE INTERAGISCONO FRA LORO
Qui bisogna ricordare nuovamente un concetto base su come Mastodon é strutturato e funziona:
Ogni Istanza Mastodon é un social network indipendente che funziona indifferentemente dalle altre Istanze: é installato su un proprio server, ha i suoi admin, i suoi utenti e le sue regole e potrebbe benissimo funzionare anche se tutte le altre Istanze del mondo non esistessero.
Dopodiché, ognuna di queste Istanze, se lo vuole, é in grado di dialogare con le altre ma é altrettanto libera di bloccare o limitare i contatti con le Istanze che non gli son gradite.
Per fare un esempio: non ne abbiamo la certezza, ma possiamo scommettere un nichelino che rcsocial.net, un’Istanza Mastodon che si propone come spazio di discussione per utenti cattolici, abbia bloccato le Istanze porno-erotiche citate sopra. Questo vuol dire che gli utenti di rcsocial.net potranno interagire tra loro e magari con utenti di altre Istanze Mastodon ma non entreranno mai in contatto con gli utenti ed i contenuti erotici di sinblr.com o humblr.social.
Il punto é che:
“Mastodon” non é un social network ma una tecnologia condivisa da diversi social autonomi e indipendenti chiamati “Istanze” che possono essere in contatto a vicenda o meno.
Parlare di “Mastodon” come di un’unica entità é assurdo così come descrivere la tecnologia chiamata “email” come se fosse un social network.
DIVERSI LIVELLI DI INTERAZIONE E BLOCCO
Il modo migliore per capire come funziona Mastodon é ragionare sempre partendo dal punto di vista della tua Istanza (quella che hai scelto o che hai creato personalmente). Nel caso più comune tu sei un utente che si é iscritto ad una Istanza di tuo gradimento, le cui policy (regole) sono sostanzialmente in linea con quelle che ti saresti dato tu.
Nei confronti delle altre Istanze con cui c’é un rapporto paritario ed amichevole, la connessione con la tua Istanza é bilaterale: utenti e contenuti delle due Istanze possono interagire liberamente tra loro.
Ci sono però anche delle Istanze che la tua Istanza ritiene inaccettabili, vuoi perché spammano o sono popolate da troll, perché sono Istanze nazistoidi che diffondono contenuti d’odio o contenuti contrari alle policy che la tua Istanza s’é data. In questo caso gli admin della tua Istanza la possono bloccare cosicché nessuno degli utenti della tua Istanza entrerà mai in contatto con utenti e contenuti dell’Istanza inaccettabile.
C’é poi il caso delle Istanze discutibili: quelle i cui contenuti non sono ben visti/tollerati dalla tua Istanza, ma non sono tanto gravi da necessitare di un vero e proprio blocco. In questo caso gli admin possono silenziarle, ossia impostarne l’interazione in modo tale tu utente possa tranquillamente interagire con utenti e contenuti di queste Istanze discutibili, ma tali interazioni non saranno visibili agli altri utenti della tua Istanza. Per intenderci: se rispondi o boosti (“retwitti” / “riposti” / “condividi” ) contenuti di queste Istanze, questi non saranno visibili da tutti i membri della tua Istanza ma solo da quelli che già seguono chi hai boostato.
Con le Istanze amiche c’é interazione bidirezionale pura; le Istanze discutibili possono essere silenziate in modo da non dare visibilità condivisa all’interazione ma senza impedirla; le Istanze discutibili possono essere bloccate in modo tale che per gli utenti della tua Istanza é come se non esistezzero più
Non solo: ogni singolo utente é libero di decidere di bloccare solo per sé singoli utenti o intere Istanze. C’é un’Istanza che gli admin della tua Istanza ritengono amica ma che tu non sopporti? Puoi tranquillamente bloccarla e non vederne mai più alcun contenuto!
L’unica cosa che tu come utente non puoi decidere autonomamente fare é interagire con Istanze che gli admin della tua Istanza hanno bloccato.
OGNI ISTANZA CREA LA PROPRIA RETE CON CHI VUOLE E LASCIA FUORI CHI NON VUOLE.
Il risultato é che se sei utente di un’Istanza come sinblr.com, probabilmente avrai tantissime interazioni con altre Istanze in cui viene pubblicato materiale erotico-pornografico, con le quali interagirai bilateralmente senza problemi, mentre al contrario se sei membro di un’Istanza di ultracattolici tradizionalisti avrai rapporti con diverse altre Istanze ma coi contenuti di sinblr.com non avrai alcun contatto. Ogni Istanza, dunque, crea una propria rete personalizzata lasciando fuori coloro con cui proprio non vuole entrare in contatto.
Questo vuol dire che potrebbe perfettamente esserci una rete Mastodon di Istanze incentrate sul porno che non ha alcun contatto con una seconda rete di Istanze Mastodon di stampo tradizionalista. La logica conseguenza di questo meccanismo é che non esiste necessariamente UNA rete Mastodon:
Possono esistere molte reti Mastodon separate che non hanno alcuna interazione fra loro
Su Bida (mastodon.bida.im) i contenuti erotici-pornografici di per sé non sono vietati a patto che vengano postati con la maschera CW (“Content Warning”: avviso sul contenuto).
Toot con immagine coperta da maschera CW ed il messaggio d’avviso “Materiale sensibile”
In pratica i contenuti sensibili vengono postati con una “maschera” che oscura le immagini in questione e per vederle l’utente deve cliccarci appositamente sopra. Se un utente di Bida postasse ripetutamente contenuti senza maschera CW verrebbe ripreso dalla comunità, dagli admin ed in caso estremo bannato. Se un utente di Bida venisse in contatto con una diversa Istanza Mastodon in cui questo tipo di contenuti vengono postati senza alcuna maschera CW, con una segnalazione agli admin di Bida questa verrebbe bloccata.
Questo é il tipo di approccio che ha Bida con contenuti sensibili ma altre Istanze potrebbero avere approcci assai diversi. Per esempio una certa Istanza potrebbe pretendere il CW su immagini porno ma non su semplici nudi né su disegni erotici, mente un’altra Istanza potrebbe avere come regola quella di bannare pure i quadri rinascimentali che mostrano nudi.
Ecco perché é di fondamentale importanza scegliere la propria Istanza (o Istanze) di riferimento: a seconda che ci si iscriva ad un’Istanza o un’altra ci si può trovare con reti, contatti ed approcci lontanissimi tra loro perché, come ribadito sopra, ogni Istanza é sostanzialmente un social network diverso ed a seconda di quale vien scelto ci si può ritrovare in una rete assai ristretta in cui non c’é alcuna apertura e tolleranza verso posizioni distanti oppure in una rete indifferenziata ed indifferente alla presenza di contenuti odio, troll e spam o invece in una rete che si é ritagliata un mix di apertura e chiusura abbastanza vicina alle proprie esigenze.
Gab not Welcome
TORNIAMO A GAB
Ricapitolato il meccanismo su cui é basato Mastodon é ora facile intuire che peso possa avere Gab sulle altre Istanze/community di Mastodon che non vogliono entrare in contatto con i nazifascisti: quasi zero. Praticamente tutte le Istanze antifasciste hanno fin da subito bloccato Gab così come già avevano bloccato altre Istanze dai contenuti simili. Anche gli admin di Bida (mastodon.bida.im) hanno bloccato Gab nonappena si é saputo del suo arrivo su Mastodon e così facendo, su Bida, i contenuti neonazisti di Gab non si son praticamente mai visti. Inoltre diversi utenti si sono mobilitati per presidiare le proprie Istanze da eventuali utenti provocatori di Gab e segnalare eventuali micro-Istanze create solo per diffondere per vie traverse i contenuti di Gab. Le istanze amiche che condividono principi etici comuni si scambiano informazioni sulle Istanze che diffondono messaggi d’odio o materiali sensibili privi di maschere CW, tenendosi sempre aggiornate sull’ecosistema umano delle proprie reti.
In sostanza le reti Mastodon antifasciste hanno retto benissimo alla presenza di nazisti e provocatori, molto meglio di social commerciali e centralizzati come Facebook o Twitter.
Allarmarsi perché dei nazifascisti hanno creato un server social usando Mastodon non é troppo diverso dall’allarmarsi perché un gruppo di neonazisti ha messo su un server mail, IRC, XMPP, o un sito web utilizzando strumenti open source.
Insomma: di per sé non é possibile impedire che si crei una rete Mastodon nera. La si può magari isolare, mettere in un angolo e complicargli la vita in diversi modi (che adesso vedremo) ma impedirne del tutto l’esistenza é impossibile: se fosse possibile impedire l’esistenza di una rete nera attraverso strumenti tecnici, quegli stessi strumenti potrebbero essere altresì usati per impedire l’esistenza di qualsiasi rete o bloccare l’accesso a diversi contenuti che a programmatori o host non sono graditi.
Non ha senso criminalizzare di per sé l’email, il telefono, la stampa o altri sistemi di comunicazione liberi perché sono tecnicamente utilizzabili anche dai nazifascisti e dunque non ha senso criminalizzare la piattaforma tecnologica Mastodon perché viene utilizzata da questi.
Tuttavia seppur questi strumenti tecnologici non sono colpevolizzabili di per sé é anche vero che, volendo, é pur sempre possibile far in modo che quegli stessi strumenti non siano comodamente usufruibili per certi utilizzi, ma la cosa genera diversi problemi di ordine pratico ed etico.
Logo di Fedilab, client Mastodon al centro di polemiche perché non ha bloccato l’accesso a Gab
LA POSIZIONE DELLE APP
Uno strumento software open source é sostanzialmente un attrezzo che chiunque può utilizzare e modificare a piacimento e questo vale sia per il software di Mastodon che per quello di diverse App per utilizzare Mastodon su smartphone.
(NB: queste App sono chiamate in gergo client, termine che identifica applicazioni il cui scopo é quello di mettere l’utente in contatto con un server sul quale stanno effettivamente i contenuti)
Come già visto, le App per accedere a Gab erano state rimosse da App Store di iOS e Play Store di Android, ma si trattava di App specifiche per quel social e quello solamente. Al contrario le principali App per Mastodon non sono specifiche per una certa Istanza, ma sono utilizzabili per accedere a qualsiasi le Istanze che uno vuole, così come un browser può accedere anche a siti neonazisti ed un client Mail può essere usato per accedere ad un mailserver neofascista.
Questo crea un effetto non voluto: dopo che Apple e Google hanno bannato Gab in quanto bubbone seminatore di odio pestilenziale, proprio le le tecnologie open di Mastodon hanno permesso a a Gab di continuare ad essere alla portata di click su qualsiasi smartphone.
Se criminalizzare Mastodon in quanto strumento non ha senso, più discutibile é la posizione delle App. Non esistono App “ufficiali” di Mastodon per Smartphone, bensì diverse App realizzate da programmatori e software house indipendenti tra cui scegliere.
Qui sorge una domanda: é eticamente corretto che i programmatori di una App (magari open source) atta a connettersi ad una piattaforma social (questa certamente sì open source), possano decidere di impedire all’App di connettersi con certe Istanze? Può un browser impedirti di visitare un certo sito? O un software di mail impedirti di scambiarti le mail con certi indirizzi?
La questione é complessa e sul Fediverso, da diversi mesi si susseguono discussioni su questo argomento.
Le posizioni vanno dal “No: lo strumento deve essere liberamente aperto ed utilizzabile” al “E’ perfettamente legittimo che un programmatore crei software open al cui interno vi siano dei blocchi a contenuti fascisti: proprio perché é uno strumento open, se i fascisti vogliono utilizzarlo sono liberi di crearsi il proprio fork(*)”
(*) il fork é la versione modificata di un software.
Quest’ultima posizione é quella che all’atto pratico meglio potrebbe rispondere all’esigenza di isolare contenuti velenosi (o perlomeno renderne un po’ più complicata la diffusione) ma al tempo stesso potrebbe fungere da pericoloso precedente (in base alla stessa logica potrebbe essere realizzato un browser che non accede a siti il cui contenuto non é gradito ai programmatori).
Il fatto é che blocchi di questo tipo già esistono per quanto riguarda contenuti tecnici nocivi: un browser può avere dei filtri che gli impediscono d’accedere a siti che contengono codice malevolo (o perlomeno mostrano una serie di avvisi molto espliciti). Può aver senso applicare questa stessa logica a contenuti tossici?
Il punto é che la logica del blocco (o avviso di sicurezza) può essere applicata solo (1) riconoscendo l’eccezionalità dei contenuti fascisti nel loro non essere “opinione” ma totale negazione del dialogo e con i quali, dunque, non é possibile avere alcuna interazione sana; (2) esponendo con chiarezza le caratteristiche che definiscono i contenuti di questo tipo.
Il contenuto d’odio, insomma, potrebbe essere trattato come un contenuto criminale tout court (ad esempio come i siti per pedofili) o un malware (come per i siti affetti da virus e codice malevolo), magari con filtri a più livelli (finestre d’avviso per i casi discutibili e via via fino al blocco per i casi più gravi)?
In ogni caso va ribadito che l’idea di poter impedire la diffusione di messaggi d’odio solamente grazie a soluzioni software é pura illusione. Tuttalpiù questi possono servire per impedire a tali contenuti di esser diffusi con troppa semplicità.
QUINDI?
Se la gestione di contenuti da parte delle Istanze é intrinsecamente risolta dalla stessa struttura di Mastodon, la questione dei client genera ancora moltissima discussione esponendo approcci legittimi ma spesso contrastanti e che non verranno certo districate da questo post. Quel che però é certo é che su Mastodon, se non vuoi incontrare i nazisti, non ne incontrerai (giusto qualcuno magari, ma a malapena per il tempo necessario a bloccarlo e con lui l’intera Istanza che gli ha permesso di pubblicare i suoi contenuti tossici
Hai dei file a cui vuoi poter accedere facilmente da qualsiasi device? Li puoi caricare su NextCloud! Devi scrivere un testo assieme ad un’altra persona che vive lontano? C’é Etherpad! Vuoi inviare un file in modo riservato? Puoi usare Lufi! Ti serve una mappa online? Ma c’é OpenStreetMap! Vuoi condividere uno status ma solo con alcuni amici intimi? Puoi farlo con Friendica! Devi cercare qualcosa sul web? C’é SearX!
Insomma: chi te lo fa fare di usare servizi centralizzati il cui solo scopo é carpire informazioni su di te, se ci sono provider online che mettono a disposizione i migliori software open source?
SIAM PASSATI DALL’ESSER PERSONE CHE UTILIZZANO STRUMENTI AD ESSER CLIENTI DI SERVIZI CHE CI USANO
La maggior parte degli utenti possiede dei device (smartphone, tablet, computer fisso o portatile…) ma non ha in casa un proprio server personale con cui gestisce ed archivia i propri contenuti. Questo perché esistono dei fornitori commerciali di servizi online (provider come Google, Apple o Facebook) che mettono comodamente e spesso “gratuitamente” a disposizione tutta quella serie di servizi che altrimenti bisognerebbe installare/impostare/aggiornare/riparare da sé. Affidarsi a provider esterni, dunque, a primo acchito risulta comodo perché libera dall’onere di imparare a gestire gli strumenti su cui si regge la propria vita digitale.
E’soprattutto nella seconda metà degli anni 2000 che si affermano i principali provider di servizi online. É in quel momento che si sviluppano aziende e strumenti come Dropbox, Evernote, Facebook, Google Docs, iCloud, Twitter, Whatsapp, YouTube ecc. Nel giro di pochi anni però, tramite acquisizioni e battaglie commerciali, la situazione che si é venuta a creare é che i principali servizi online sono proprietà di soli cinque colossi americani: Amazon, Apple, Facebook, Google, Microsoft.
Cinque aziende commerciali che hanno nelle proprie mani la vita digitale di ogni individuo del pianeta, alcune delle quali sono state fondate con l’esplicito scopo di raccogliere, analizzare e vendere tutte le informazioni che possono sui propri utenti.
Non tutti ci han fatto caso, ma mentre questi provider nascevano e si facevano ogni giorno più forti é avvenuto nelle nostre vite un importantissimo doppio cambio di paradigma. Il tutto é avvenuto in maniera esplicita, alla luce del sole e nient’affatto misteriosa, solo che é avvenuto tanto in fretta e con un tale hype nei confronti della “tecnologia del futuro” che la maggior parte delle persone non se n’é curata: 1) si é passati dallo “strumento come strumento” allo “strumento come servizio” ed alla 2) cessione volontaria dei propri dati sensibili in cambio dell’utilizzo di tali servizi.
Il concetto, insomma, é che si é passati dal “possiedo carta e penna su cui scrivo quel che mi pare e poi se voglio lo tengo chiuso in un cassetto oppure lo consegno a chi mi pare ma sempre senza dover render conto a nessuno della mia scelta” al “Posso usare la fantastica penna di lusso e la fantastica carta della ditta X per scrivere tutto quel che mi pare, alla sola condizione che la ditta X leggerà tutto ciò che scrivo e ne farà quel che vorrà”.
Tu, utente, non “hai” Whatsapp. Quando dici che “hai Whatsapp” stai dicendo una stronzata.
Non hai idea di quali informazioni su di te il software di Whatsapp trasmette ai server di Facebook(i millisecondi che sei stato fermo su una foto? se ne hai allargato un dettaglio? se l’hai salvata? se hai salvato una schermata con quella porzione di chat? quanti errori grammaticali fai? in quali ore dormi? quali sono le persone di cui cancelli le chat?).
Non sai in che modo questi dati vengono interpretati (il numero di emoji usati in relazione alle volte in cui usi certe parole? quali sono le parole che usi solo con certe persone? i tuoi riferimenti culturali più comuni in relazione con la mappa dei tuoi spostamenti? le opinioni che hanno su di te i tuoi “amici” e che si scambiano nei messaggi privati?).
Non sai in che modo Whatsapp ti profila (ha intuito che forse tra te e una certa persona c’é una tresca in base all’analisi dei vostri tracciati GPS ed ai messaggi fasulli che avete inviato? ha dedotto le tue debolezze emotive utilizzabili come grimaldello propagandistico da una forza politica che avversi per confonderti le idee?)
L’ultimo punto probabilmente é il più importante. Si sa, che spesso il problema non é in chi trasmette informazioni (tu), ma in chi le legge (Facebook). Se Facebook interpretasse dalla tua attività online che sei potenzialmente una minaccia per il governo in carica e questa informazione fosse venduta proprio a qualcuno che lavora per il governo in carica beh, a seconda della natura di tale governo potresti passare decisamente dei brutti momenti.
LA SOLUZIONE IDEALE É AVERE IL PROPRIO SERVER A CASA
Possiamo girarci attorno finché si vuole, ma la verità é che l’unico software su cui puoi avere la massima fiducia é software FLOSS installato da te su un tuo device di proprietà, a cui solo tu hai accesso.
Idealmente, dunque, un web veramente libero dovrebbe essere composto da innumerevoli device e server personali su cui sono installati gli strumenti software che ognuno preferisce e per far sì che questo non porti ad una eccessiva frammentazione delle piattaforme, idealmente e pur mantenendo la propria indipendenza, queste dovrebbero comunque possedere un certo grado di interoperabilità (ad essempio costituendo una rete federata). Si tratta di uno scenario tecnicamente realistico, molto vicino a quello delle prime reti BBS all’alba di Internet e che qualcuno sta effettivamente cercando di far prender nuovamente piede. Gli strumenti ci sono e funzionano già a dovere. Quel che gli manca é solamente un’adozione massiccia.
Certo é pur vero che l’idea di fare self-hosting (ossia il possedere un proprio server personalizzato) può spaventare molte persone, nonostante gli strumenti per realizzarlo siano sempre più alla portata di chiunque (come ad esempio YuNoHost un sistema operativo pensato proprio per server casalinghi gestiti da un utente inesperto, già predisposto per ospitare un’Istanza Nextcloud, Matrix, Mastodon, XMPP, WordPress, SearX, Tiny Tiny RSS, Wallabag e praticamente tutto quel che riguarda la vita digitale di ognuno).
Capiamoci: siamo nel 2019; i computer esistono ormai da eoni, ma anche a voler restare stretti e concentrarci solo sul periodo in cui questi sono entrati in massa nelle case, stiam parlando comunque di 25-30 annima la conoscenza media di questi strumenti é perlopiù limitata all’utilizzo più superficiale. La situazione può essere paragonata allo scenario in cui milioni di automobilisti che, pur sapendo guidare, ignorassero totalmente cosa siano il motore, le pastiglie dei freni o la batteria, ma si accontentassero di sapere che girare il volante a sinistra fa girare a sinistra anche le ruote, credendo così di sapere come funziona un’automobile.
Il fatto é che, come già detto, siamo nel 2019: non si pretende certo che tutti diventino dei provetti meccanici-hacker, ma almeno che si diffonda una conoscenza generale giusto un minimo più accorta. Insomma: basterebbe che si sapesse che sotto il cofano c’é una cosa chiamata motore e più o meno in base a quali princìpi funziona.
La cosa ancor più drammatica é che le conoscenze base per potersi muovere in campo informatico (una spolverata di teoria, imparare ad installare un sistema operativo, compiere operazioni di maintenance, usare motori di ricerca come si deve ed alcuni concetto-base di sicurezza informatica) possono essere apprese con un corso di sette giorni, meno che per la patente, ma nonostante l’utilizzo dei device informatici sia una costante su base quotidiana per milioni di persone, ancora troppo poche hanno “fatto il corso di sette giorni”.
STRUMENTI FLOSS
Come già esposto in altri articoli, esistono da anni diversi strumenti FLOSS (ossia software aperto, gratuito e liberamente utilizzabile) che non hanno nulla da invidiare ai loro corrispettivi commerciali. Anzi, in molti casi gli strumenti FLOSS sono pure tecnicamente più avanzati delle loro controparti, tanto che moltissimo software che utilizziamo quotidianamente (come Chrome o Whatsapp) non é che una versione modificata di software FLOSS. L’unica pecca del software FLOSS, semmai, deriva dal fatto che essendo utilizzao da meno utenti, spesso ha una quantità minore di contenuti: la quantità di roba che vien pubblicata sui social open durante una giornata equivale forse a quella che su Facebook vien pubblicato in un minuto. Di conseguenza vi é anche minor spinta a venir incontro agli interessi di un pubblico che si trova altrove. Si tratta della classica situazione del gatto che cerca di mordersi la coda: gli utenti non adottano un sistema se non ci son gran quantità di contenuti, ma non possono esserci gran quantità di contenuti se non ci sono utenti.
Per dirla in altro modo, tornando alla metafora automobilistica: finché tutti continueranno a voler usare ruote di legno, quel tizio strano che ha avuto l’idea di fare ruote di gomma resterà confinato nella sua bottega a fare le ruote di gomma una-ad-una per i suoi clienti affezionati, ma non riuscirà mai a metter su una fabbrica per produrle in serie. Questo a meno che non ci sia una forte spinta ad adottare in massa tali ruote di gomma, ma si tratta di una spinta che non verrà mai dalle grandi aziende produttrici di ruote di legno.
Una selezione di strumenti e piattaforme commerciali libere e la loro controparte commerciale
SERVIZI VISIBILI vs. VANTAGGI INVISIBILI
Una delle difficoltà maggiori riguardanti il software FLOSS é il riuscir a far capire il loro valore ad una popolazione che, come già detto, ha giusto delle vaghe conoscenze informatiche. Spiegare i vantaggi degli strumenti FLOSS a chi é privo di ogni base informatica spesso suona difficile come cercar di spiegare com’é possibile che gli aerei si librino nell’aria ad una popolazione vive nel terrore che la Luna caschi dal cielo.
Per esempio: quando si parla di privacy e protezione dei dati personali sul web, solitamente l’immagine che viene evocata dall’utente comune é quella del tizio parte-hacker-parte-007-parte-esattore-di-Equitalia che traffica sul web per carpire informazioni piccanti o spiacevoli sulla tua persona, ossia uno scenario da film complottista che, pur non essendo impossibile, nella maggior parte dei casi risulta alquanto improbabile: a chi mai interessa cosa faccia nella vita privata il signor Gino del quinto piano? Certo però che quelle stesse informazioni diventano estremamente interessanti se acquisibili in massa assieme a quelle di milioni di altre persone…
In realtà ciò che avviene nella maggior parte dei casi é che le informazioni dettagliatissime che hai fornito su di te vengono utilizzate all’interno dei cosiddetti big data per impostare argomentazioni politiche, saggiare il terreno su certi argomenti senza tener conto dello scarto fra vita reale e vita sul web e soprattutto, per modificare il discorso pubblico prevalente su determinate questioni.
Il tuo profilo, il tuo singolo profilo utente, di per sé ha scarso valore (a meno che tu non sia un VIP o un noto criminale). Ma se il tuo profilo fa parte di un bouquet di milioni di profili allora la cosa cambia!
Quel che avviene é che i committenti hanno modo di influenzare quali e quante informazioni riceverai, facendo sì che sui social certe notizie appaiano nella tua Timeline ma non in quella del tuo vicino o che ti venga suggerito si seguire certi contatti e non altri. Le informazioni che hai fornito su di te sono uno strumento impagabile affinché queste modifiche riescano ad essere cucite proprio apposta per te.
Non é un caso se milioni di persone vengono portate a credere a cose del tutto false o a consolidare idee che, se non ci fosse controllo sui contenuti che ricevono, non sarebbero difese con tanta irrazionalità. Chi manipola quel ti vien detto, non fa altro che indirizzare il tuo modo di pensare.
In poche parole, scegliere di utilizzare le grosse piattaforme centralizzate del data-mining (letteralmente “estrazione dati”, ossia ciò che fanno Facebook, Google ecc) equivale a buttarsi nel mare in cui viene effettuata la più imponente e specialistica pesca a strascico del mondo: una pesca a strascico smart che se da un lato coinvolge tutti i pesci nel mare, nessuno escluso, dall’altro non uccide i pesci, ma li lascia in acqua, studiandoli tanto a fondo da capire come fare a far sì che ogni singolo pesce poi nuoti nella direzione che il pescatore desidera.
In sostanza più informazioni personali forniamo alle grandi compagnie di data mining e più aiutiamo chi manipola le informazioni sui media mainstream; più aiutiamo chi vuole seminare odio in maniera mirata; più aiutiamo le società di marketing a renderci dipendenti dai loro prodotti. Un esempio su tutti? In Italia, da anni, il numero di crimini violenti é in calo costante. Non é una novità: ogni anno i quotidiani pubblicano i nuovi dati e da anni, appunto, si annuncia che sono calati rispetto all’anno prima. Eppure la percezione diffusa é che invece siano in aumento. Stessa cosa per il numero di stranieri residenti in Italia: oltre il 73% degli italiani ne sovrastima il numero. Certo, la percezione pubblica non viene modificata dai soli social, anche i media hanno un ruolo fondamentale in questo, ma é innegabile che oggi il grosso di questo lavoro avvenga proprio sui social.
I recenti scandali legati a Facebook, Cambridge Analytica, la Brexit,il Russiagate ed i sospetti di intervento esterno sui social durante diverse campagne elettorali non sono che l’aspetto più macroscopico e noto dell’intreccio fra big data, politica e manipolazione dell’opinione pubblica.
Ecco, tutto questo fa parte di ciò che l’utente medio fa fatica a vedere e tra un’app per mandare immagini di gattini con musichette carine ed un’app che fa lo stesso ma meno pubblicizzata e usata da meno utenti, sceglierà la prima, anche se la seconda ha caratteristiche migliori ed é più adatta a proteggerne le informazioni personali.
Socialità quantitativa e strumenti che necessitano apprendimento raso-zero sono, purtroppo, i fattori determinanti per la scelta delle piattaforme da utilizzare. Restando all’esempio automobilistico, é come dire che il mondo preferisce le auto senza specchietti, frecce, cinture di sicurezza ed altri dispositivi di protezione “perché é roba da nerd maniaci” e si é adattato a ritenere che beh, é normale che ogni automobilisca faccia qualche incidente e perda qualche arto.
PROVIDER OPEN SOURCE
Se proprio non si ha modo o voglia di self-hostare i propri strumenti software, un buon compromesso fra self-hosting ed il ricorso ai provider di servizi commerciali come Facebook o Google é quello di rivolgersi a dei provider online di software open source. In pratica, se Google mette a disposizione i suoi strumenti (Google Calendari, Contatti, Drive, Mail, Ricerca, Documenti, Fogli, Presentazioni, ecc…) ed anche Apple fa altrettanto con i propri (iCloud, Contatti, Pages, Numbers, ecc…), così come fa Facebook (Facebook, Messenger, Instagram, Whatsapp) e tutti quei provider che mettono a disposizione il proprio unico strumento (L’azienda Evernote mette a disposizione lo strumento Evernote, l’azienda Twitter mette a disposizione lo strumento Twitter ecc.) esistono anche diversi provider che invece mettono a disposizione applicazioni FLOSS che, se l’utente volesse, potrebbe tranquillamente scaricarsi e installare su un tuo server personale, essendo tutto software aperto e liberamente scaricabile (quindi, chiunque abbia le necessarie competenze tecniche, può verificare cosa fa davvero il software “sotto il cofano” e come).
La comodità di questa soluzione é indubbia: hai un server sempre attivo accessibile 24/24 che viene mantenuto efficiente, aggiornato e riparato da qualcun’altro cosicché tu possa accedervi senza problemi.
L’idea alla base dei provider di applicazioni FLOSS é che anziché esserci solo 4 o 5 colossali provider cui si rivolgono tutti, possano invece esserci centinaia, migliaia, milioni di server che offrono una vastità di strumenti che però siano compatibili tra loro o addirittura federati.
Una piccola digressione: Framasoft é un provider che fornisce una propria Istanza Mastodon, mentre Bida é un altro provider che fa altrettanto. Pur essendo due provider distinti (sotto un certo punto di vista é come dire Apple e Facebook) entrambi mettono a disposizione lo stesso strumento, Mastodon, che ha la peculiarità di essere federato. Ciò significa che gli utenti che usano l’Istanza Mastodon di Framasoft e quelli che usano l’Istanza Mastodon di Bida potranno interagire fra loro come se fossero su un’unica grande chat. Volendo fare un paragone, sia iChat che Whatsapp, i software di chat di Apple e Facebook, sono stati entrambisviluppati in base ad XMPP, che é software FLOSS. Questo vuol dire che tecnicamente sarebbe semplicissimo far dialogare tra loro Whatsapp ed iMessage, ma ciò non avviene puramente a causa di bagarre commerciali.
A questo punto però sorge spontanea una domanda: perché non fidarsi di Facebook e Google ma fidarsi di un provider open source? Si tratta pur sempre di dover riporre fiducia in qualcuno che (presumibilmente) non si conosce ed a cui si affidano i propri dati personali. L’osservazione é in effetti corretta e l’unica risposta sensata é che così come non ci si può fidare dell’uno non ci si dovrebbe fidare nemmeno dell’altro.
Ma ci sono dei “ma”.
Innanzitutto i maggiori provider di servizi commerciali come Facebook e Google sono ESPLICITAMENTE basati sulla lettura, analisi e compravendita dei contenuti che noi forniamo. Da cosa guadagnano Facebook e Google? Qualcosina sì dalla pubblicità, ma il grosso dei guadagni, quello che ha rende Mark Zuckerberg uno degli uomini più ricchi del mondo, é la vendita delle informazioni degli utenti.
ETICA DICHIARATA: Dall’altra, la maggior parte dei provider open source é realizzata e mantenuta da persone, comunità e collettivi che esplicitamente combattono l’utilizzo a fini commerciali delle informazioni degli utenti. Ci si può fidare o meno, ma rivolgersi ai big equivale alla certezza che la vendita dei propri dati avvenga.
SOFTWARE NON TRACCIANTE: Il software utilizzato é caratterizzato dal fatto di chiedere solo i dati strettamente necessari per funzionare (talvolta non chiedono proprio nulla) in modo da ridurre al minimo le possibilità di profilazione dell’utente. Certo, un provider potrebbe aver modificato il software sul suo server senza dichiararlo, ma come vedremo nei prossimi punti, potrebbe essere un’opzione poco interessante per il provider stesso.
FRAMMENTAZIONE INTERNA: I vari servizi offerti dai provider di software open source sono spesso scollegati fra loro. Questo significa che di solito non c’é un’unico nome utente e password per tutti i servizi. In questo modo se anche usassi in contemporanea l’Istanza Mastodon ed i fogli di calcolo dello stesso provider, lui potrebbe credere che ciò venga fatto da due utenti diversi.
FRAMMENTAZIONE PERSONALE: Nulla t’impedisce di rivolgerti a più provider contemporaneamente, frammentando le tue informazioni personali un pò qua ed un po là. Se due o più profider forniscono gli stessi software (per esempio NextCloud), usare l’uno o l’altro non comporterà alcuna difficoltà di apprendimento. Ad esempio puoi usare l’Istanza Mastodon del provider A, il server Matrix del provider B e gli strumenti office del provider C e gestirli come se fossero di tre utenti differenti, in modo che nessuno di questi abbia la totalità delle informazioni sul tuo conto.
FRAMMENTAZIONE GLOBALE: Se le informazioni di tutti stanno su Facebook e Google, é sufficiente acquistare informazioni da quei due provider per avere un database su milioni di persone. Se invece questi milioni di utenti fossero sparpagliati su migliaia di server interconnessi da poche migliaia di utenti l’uno, chi volesse farsi un database altrettanto massiccio dovrebbe contattare (o hackerare) uno-ad-uno migliaia di server. Lo sforzo sarebbe di per sé immane. Se poi si considera che, come visto, le informazioni che si troverebbero in mano sarebbero molto meno dettagliate ed interessanti di quelle fornite da Facebook, é chiaro che i server di servizi FLOSS risultano strutturalmente poco utili per chi vuol commerciare informazioni personali.
CHE STRUMENTI VENGONO MESSI A DISPOSIZIONE?
Gli strumenti messi a disposizione dai provider sono un’infinità e spaziano dagli strumenti per ufficio (scrittura collaborativa, fogli di calcolo, mappe mentali), web hosting (tipo Dropbox, iCloud, Google Drive ecc.), social, chat personali, strumenti per programmatori… Per farla breve: pensa ad un servizio online che usi comunemente ed e sappi che ne esiste anche la versione libera e aperta, fatta eccezione giusto per i fornitori di media mainstream coperti da copyright come Spotify o Netflix e iTunes, ecco, ma se pensi a Evernote, Dropbox, Twitter, Facebook, Google Maps, Gmail, Whatsapp, le ricerche su Google, iWork e tutti quegli strumenti che usi quotidianamente online beh, ognuno di questi ha la sua controparte libera!
Alcuni di questi strumenti sono parzialmente sovrapponibili; un esempio é l’applicazione Turtl che é sia un gestore appunti (Notebook) che uno strumento per archiviare link interessanti (Bookmark manager) che fa dunque un pò quello che fa Evernote ed un pò quello che fa Pocket. Questo per dire che in alcuni casi la definizione usata per classificare questi strumenti può essere poco esaustiva.
Altra cosa interessare é che uno stesso provider può mettere a disposizione più strumenti che fanno la stessa cosa (ad esempio due diversi tipi di calendario o di strumenti di scrittura). La cosa può confondere un attimo chi non é abituato a dover scegliere tra opzioni diverse con uno stesso provider, ma va tutta a favore della personalizzazione (ti trovi scomodo ad usare EtherPad? Nessun problema: abbiamo anche PadLand!)
Certi strumenti software sono molto popolari e vengono messi a disposizione da diversi provider (per esempio, chi offre un servizio di data hosting nel 99% dei casi utilizza NextCloud), che però ne personalizzano un pò l’estetica, a volte alcune funzioni e spesso anche il nome (per esempio, il server Nextcloud messo a disposizione da Framapiaf viene chiamato “Framadrive”). Altri invece, sono più rari.
ELENCO PROVIDER OPEN SOURCE
Questo post non é incentrato sulle funzionalità dei singoli strumenti software e qui si vuol solo elencare una serie di provider di strumenti FLOSS che, volendo, un utente potrebbe anche installarsi su un proprio server. Pertanto l’elenco non comprende siti che mettono a disposizione un unico strumento software (tipo mastodon.social che mette a disposizione solamente la propria Istanza Mastodon) e/o strumenti software non hostabili privatamente (tipo DuckDuckgo)
A/I é il principale riferimento italiano per quanto riguarda collettivi antagonisti e anticapitalisti impegnati per i diritti digitali. Offre tutta una serie di strumenti con un fortissimo occhio di riguardo a sicurezza e protezione dati.
Disroot é un’organizzazione di hacktivisti di impronta libertaria impegnata a far conoscere le tecnologie aperte ed a diffondere una maggior cultura della privacy informatica.
Framasoft é un’importante associazione francese il cui scopo é quello di diffondere l’uso di tecnologia FLOSS. Framasoft organizza incontri, corsi ed un gran numero di attività diverse. In particolare sta portando avanti il progetto di de-googleizzare il web, facendo conoscere tutti gli strumenti già esistenti ed utilizzabili anche senza dover per forza rivolgersi alle big company dell’informatica. Gli strumenti che offre Framasoft sono davvero tantissimi e non sarà possibile elencarli tutti, ma ci si prova. Una caratteristica particolare é che Framasoft ribattezza gran parte degli strumenti offerti “Frama(qualcosa)”. Il sito é in francese ma gran parte é tradotto in inglese e sempre più pagine sono tradotte anche in italiano.
Librem é il marchio dei prodotti e servizi open dell’azienda Purism. Purism produce computer desktop e smartphone di alta fascia che promettono una alta attenzione al rispetto della privacy e della sicurezza informatica. I servizi della linea Librem derivano da strumenti FLOSS che però vengono fortemente personalizzati e rinominati “Librem(qualcosa)”; per esempio, il server Mastodon offerto da Framasoft si chiama FramaPiaf.
Nixnet é creato e gestito apparentemente da una sola persona, Amolith, che mette a disposizione gli stessi strumenti che lui utilizza. Molto servizi sono utilizzabili anche attraverso TOR e c’é forte attenzione su sicurezza e criptatura dei messaggi.
RiseUp é un collettivo di Seattle ma con membri sparsi in tutto il mondo. É attivo dal 1999 e si adopera per una società libera ed una lete altrettanto libera.