Google Chrome now lets you delete the local AI models that power the "Enhanced Protection" feature, which was upgraded with AI capabilities last year. [...]
Il lancio della versione Beta negli Stati Uniti introduce la possibilità di connettere l’assistente AI a servizi come Gmail, Foto e Drive, puntando su una personalizzazione contestuale e su nuovi standard di privacy. L’evoluzione degli assistenti basati sull’intelligenza artificiale segna […]
Direct navigation — the act of visiting a website by manually typing a domain name in a web browser — has never been riskier: A new study finds the vast majority of “parked” domains — mostly expired or dormant domain names, or common misspellings of popular websites — are now configured to redirect visitors to sites that foist scams and malware.
A lookalike domain to the FBI Internet Crime Complaint Center website, returned a non-threatening parking page (left) whereas a mobile user was instantly directed to deceptive content in October 2025 (right). Image: Infoblox.
When Internet users try to visit expired domain names or accidentally navigate to a lookalike “typosquatting” domain, they are typically brought to a placeholder page at a domain parking company that tries to monetize the wayward traffic by displaying links to a number of third-party websites that have paid to have their links shown.
A decade ago, ending up at one of these parked domains came with a relatively small chance of being redirected to a malicious destination: In 2014, researchers found (PDF) that parked domains redirected users to malicious sites less than five percent of the time — regardless of whether the visitor clicked on any links at the parked page.
But in a series of experiments over the past few months, researchers at the security firm Infoblox say they discovered the situation is now reversed, and that malicious content is by far the norm now for parked websites.
“In large scale experiments, we found that over 90% of the time, visitors to a parked domain would be directed to illegal content, scams, scareware and anti-virus software subscriptions, or malware, as the ‘click’ was sold from the parking company to advertisers, who often resold that traffic to yet another party,” Infoblox researchers wrote in a paper published today.
Infoblox found parked websites are benign if the visitor arrives at the site using a virtual private network (VPN), or else via a non-residential Internet address. For example, Scotiabank.com customers who accidentally mistype the domain as scotaibank[.]com will see a normal parking page if they’re using a VPN, but will be redirected to a site that tries to foist scams, malware or other unwanted content if coming from a residential IP address. Again, this redirect happens just by visiting the misspelled domain with a mobile device or desktop computer that is using a residential IP address.
According to Infoblox, the person or entity that owns scotaibank[.]com has a portfolio of nearly 3,000 lookalike domains, including gmai[.]com, which demonstrably has been configured with its own mail server for accepting incoming email messages. Meaning, if you send an email to a Gmail user and accidentally omit the “l” from “gmail.com,” that missive doesn’t just disappear into the ether or produce a bounce reply: It goes straight to these scammers. The report notices this domain also has been leveraged in multiple recent business email compromise campaigns, using a lure indicating a failed payment with trojan malware attached.
Infoblox found this particular domain holder (betrayed by a common DNS server — torresdns[.]com) has set up typosquatting domains targeting dozens of top Internet destinations, including Craigslist, YouTube, Google, Wikipedia, Netflix, TripAdvisor, Yahoo, eBay, and Microsoft. A defanged list of these typosquatting domains is available here (the dots in the listed domains have been replaced with commas).
David Brunsdon, a threat researcher at Infoblox, said the parked pages send visitors through a chain of redirects, all while profiling the visitor’s system using IP geolocation, device fingerprinting, and cookies to determine where to redirect domain visitors.
“It was often a chain of redirects — one or two domains outside the parking company — before threat arrives,” Brunsdon said. “Each time in the handoff the device is profiled again and again, before being passed off to a malicious domain or else a decoy page like Amazon.com or Alibaba.com if they decide it’s not worth targeting.”
Brunsdon said domain parking services claim the search results they return on parked pages are designed to be relevant to their parked domains, but that almost none of this displayed content was related to the lookalike domain names they tested.
Samples of redirection paths when visiting scotaibank dot com. Each branch includes a series of domains observed, including the color-coded landing page. Image: Infoblox.
Infoblox said a different threat actor who owns domaincntrol[.]com — a domain that differs from GoDaddy’s name servers by a single character — has long taken advantage of typos in DNS configurations to drive users to malicious websites. In recent months, however, Infoblox discovered the malicious redirect only happens when the query for the misconfigured domain comes from a visitor who is using Cloudflare’s DNS resolvers (1.1.1.1), and that all other visitors will get a page that refuses to load.
The researchers found that even variations on well-known government domains are being targeted by malicious ad networks.
“When one of our researchers tried to report a crime to the FBI’s Internet Crime Complaint Center (IC3), they accidentally visited ic3[.]org instead of ic3[.]gov,” the report notes. “Their phone was quickly redirected to a false ‘Drive Subscription Expired’ page. They were lucky to receive a scam; based on what we’ve learnt, they could just as easily receive an information stealer or trojan malware.”
The Infoblox report emphasizes that the malicious activity they tracked is not attributed to any known party, noting that the domain parking or advertising platforms named in the study were not implicated in the malvertising they documented.
However, the report concludes that while the parking companies claim to only work with top advertisers, the traffic to these domains was frequently sold to affiliate networks, who often resold the traffic to the point where the final advertiser had no business relationship with the parking companies.
Infoblox also pointed out that recent policy changes by Google may have inadvertently increased the risk to users from direct search abuse. Brunsdon said Google Adsense previously defaulted to allowing their ads to be placed on parked pages, but that in early 2025 Google implemented a default setting that had their customers opt-out by default on presenting ads on parked domains — requiring the person running the ad to voluntarily go into their settings and turn on parking as a location.
A quasi due anni dall’introduzione della famiglia Gemini, Google entra in una nuova fase del suo percorso nell’intelligenza artificiale con il debutto di Gemini 3.
Nel corso degli anni, ogni generazione di Gemini ha ampliato le capacità del modello precedente, fino ad arrivare oggi a un punto di svolta con Gemini 3, progettato per combinare tutte le funzioni della piattaforma in un modello più intelligente, più naturale da guidare e soprattutto più capace nel ragionamento avanzato.
Le novità principali riguardano la capacità di Gemini 3 di cogliere sfumature, intenti e indizi sottili nelle richieste dell’utente. Il modello è stato progettato per comprendere meglio il contesto, riducendo la necessità di prompt complessi e interazioni ripetitive e Google sottolinea come, in soli due anni, l’AI sia passata dal semplice riconoscimento di testi e immagini alla comprensione dell’ambiente circostante, con un livello di percezione molto più vicino a quello umano.
Gemini 3 debutta fin da subito in prodotti come AI Mode nella Ricerca, che introduce risultati dinamici e visualizzazioni più interattive generate al volo, e nell’app Gemini, ora potenziata dal modello di nuova generazione. Parallelamente, sviluppatori e aziende possono iniziare a utilizzarlo in AI Studio, Vertex AI e nella nuova piattaforma Google Antigravity, pensata per il paradigma degli agenti AI.
Le novità tecniche: Pro, Deep Think e i benchmark
Gemini 3 rappresenta un passo significativo verso l’AGI (Artificial General Intelligence) grazie alla sua capacità di ragionare, pianificare e interagire in modo coerente attraverso più modalità: testo, immagini, video, audio e codice.
Sul fronte dei benchmark, Gemini 3 Pro registra risultati superiori rispetto a Gemini 2.5 Pro in ogni categoria. Tra i punteggi più rilevanti troviamo:
1501 Elo su LMArena, primo al mondo
91,9% in GPQA Diamond
23,4% in MathArena Apex, nuovo stato dell’arte
81% su MMMU-Pro e 87,6% su Video-MMMU per il ragionamento multimodale
72,1% su SimpleQA Verified, con un miglioramento sostanziale nell’accuratezza dei fatti
Le risposte risultano più concise, meno ridondanti e più orientate a un ragionamento autentico, un approccio che Google descrive come la volontà di dire ciò che serve sapere, non ciò che l’utente vuole sentirsi dire.
Accanto al modello principale, Google introduce anche Gemini 3 Deep Think, una modalità progettata per spingere ulteriormente il ragionamento complesso. Nei test interni supera perfino Gemini 3 Pro, con risultati come:
41% in Humanity’s Last Exam
93,8% in GPQA Diamond
45,1% in ARC-AGI, ad oggi uno dei punteggi più alti mai registrati
Questa modalità, dedicata alle attività più difficili, sarà resa disponibile inizialmente ai tester di sicurezza e successivamente agli abbonati Google AI Ultra.
Un assistente per imparare, creare e programmare
Uno degli aspetti più rilevanti della nuova generazione è la capacità di Gemini 3 di aiutare l’utente a imparare in modo personalizzato. Il modello può sintetizzare informazioni provenienti da fonti diverse, come documenti manoscritti, video didattici o articoli scientifici, trasformandole in flashcard, visualizzazioni, spiegazioni guidate o interi percorsi di studio.
L’integrazione con la Ricerca Google consente ora di generare layout interattivi, simulazioni e contenuti dinamici direttamente dalla query, sfruttando la multimodalità nativa del modello.
Sul fronte dello sviluppo, Gemini 3 si conferma come uno dei modelli più potenti per il vibe coding e la programmazione agentica superando i precedenti record su benchmark come WebDev Arena e SWE-bench Verified e supporta nuovi ambienti di sviluppo come Google Antigravity, una piattaforma che trasforma l’AI da semplice assistente a vero co-sviluppatore.
Gli agenti di Antigravity possono accedere direttamente all’editor, al terminale e al browser, pianificando e realizzando interi flussi software in autonomia, convalidando il codice durante il processo. Il sistema è integrato anche con Gemini 2.5 Computer Use per il controllo del browser e con il modello di editing visivo Nano Banana.
Rispetto ai modelli precedenti, Gemini 3 migliora anche la capacità di pianificare attività complesse in più passaggi. Il modello guida ora workflow di lungo periodo in modo più coerente, come dimostrato dai risultati su Vending-Bench 2, benchmark dedicato alla pianificazione a orizzonte esteso.
Questo permette a Gemini 3 di gestire autonomamente operazioni come la pulizia della casella Gmail, l’organizzazione di itinerari di viaggio o la coordinazione di attività multi-step, sempre con supervisione dell’utente.
Google afferma inoltre che Gemini 3 è il modello più sicuro mai realizzato dall’azienda, grazie a un numero record di valutazioni interne ed esterne. Il modello riduce l’inclinazione a seguire ciecamente richieste rischiose e presenta maggiore resistenza alle tecniche di prompt injection e agli abusi tramite strumenti informatici.
Diverse organizzazioni indipendenti — tra cui Apollo, Vaultis e Dreadnode — hanno condotto test autonomi, mentre enti pubblici come l’AISI britannica hanno partecipato alle verifiche preliminari.
Disponibilità
A partire da oggi, Gemini 3 è disponibile da ora nell’app Gemini, per gli abbonati AI Pro e AI Ultra in AI Mode nella Ricerca, per gli sviluppatori tramite API Gemini, AI Studio, Google Antigravity e Gemini CLI e per le aziende tramite Vertex AI e Gemini Enterprise
La modalità Deep Think, dopo i test di sicurezza, sarà disponibile nelle prossime settimane agli abbonati Ultra.
Impostiamo Google Traduttore offline in modo corretto, così da tradurre anche senza connessione. Ecco passaggi, limiti, trucchi e una checklist pronta all’uso.
Negli ultimi due anni, Google ha infuso l’intelligenza artificiale di Gemini in ogni aspetto dei suoi dispositivi e servizi. Ora, secondo le ultime notizie provenienti proprio dal colosso americano, anche la più famosa app di navigazione, Google Maps, riceverà numerosi funzioni legate all’intelligenza artificiale.
Tra le funzioni più amate c’è il controllo vocale di Maps tramite Assistant, che consente di avere le mani libere e di pianificare e modificare i percorsi al volo. Ora però con Gemini, Google promette di portare questa esperienza ad un livello superiore.
Se non si sa esattamente dove si vuole andare, si potrà semplicemente descrivere il tipo di posto e lasciare che Gemini faccia tutto il lavoro sporco. Un’altra novità molto interessante riguarda l’integrazione con Lens: si potrà infatti usare la fotocamera del proprio dispositivo e far sì che Maps risponda alle domande sui luoghi che vede, ottenendo maggiori informazioni su ciò che offrono, proprio come una vera e propria guida turistica.
Alcune di queste novità sono già attive da ieri, mentre l’integrazione con Lens sarà disponibile poco più avanti nel corso del mese e la stessa tempistica sembra valere per la navigazione basata su Gemini, prevista entro le prossime settimane.
Da oggi AI Mode, la modalità di Ricerca Google basata su intelligenza artificiale, è disponibile in 36 nuove lingue, tra cui l’italiano, e in quasi 50 nuovi Paesi e territori, per un totale di oltre 200 aree coperte in tutto il mondo. L’espansione include gran parte dell’Europa e segna il debutto ufficiale di questa funzione anche in Italia, sia nella pagina dei risultati di ricerca sia nell’app Google per Android e iOS.
AI Mode rappresenta la forma più avanzata di ricerca mai proposta da Google: una modalità progettata per gestire domande complesse, articolate e multidimensionali, grazie a una versione personalizzata dei modelli Gemini ottimizzati per la Ricerca.
Rispetto alla ricerca tradizionale, AI Mode consente di formulare richieste più lunghe e dettagliate, che in passato avrebbero richiesto più interrogazioni separate. Gli utenti che l’hanno provata per primi, spiega Google, tendono a porre query due o tre volte più estese rispetto alla media.
Un esempio pratico? È possibile chiedere:
“Vorrei capire i diversi metodi di preparazione del caffè. Crea una tabella che confronti gusto, facilità d’uso e attrezzatura necessaria.” A questo punto, l’utente può continuare con una seconda domanda, ad esempio: “Qual è la macinatura migliore per ciascun metodo?”
Dietro le quinte, AI Mode sfrutta una tecnologia definita query fan-out, che scompone la domanda in sottotemi ed esegue ricerche parallele per ciascuno. In questo modo, la piattaforma è in grado di esplorare il web più in profondità e proporre contenuti più ricchi, pertinenti e aggiornati.
Un altro aspetto distintivo di AI Mode è la multimodalità: l’utente può porre domande non solo tramite testo, ma anche con la voce o con un’immagine. Basta toccare l’icona del microfono per chiedere qualcosa a voce, oppure scattare o caricare una foto per ottenere informazioni visive contestuali — una funzione utile, ad esempio, per riconoscere oggetti, prodotti o monumenti.
Nonostante la crescente integrazione dell’IA, Google ribadisce che l’obiettivo di AI Mode resta quello di facilitare la scoperta di contenuti provenienti dal web, fornendo sempre link diretti alle fonti.
Secondo l’azienda, strumenti come AI Overview (la panoramica automatica di risultati basata su IA) stanno già mostrando che, dopo aver visualizzato i suggerimenti dell’IA, le persone visitano una varietà più ampia di siti web e trattano i contenuti con maggiore attenzione, trascorrendo più tempo sulle pagine visitate.
AI Mode si basa inoltre sugli stessi sistemi di ranking e qualità usati per la Ricerca classica, ma introduce nuovi approcci per valutare l’affidabilità delle informazioni. Quando il sistema non è sufficientemente sicuro della risposta, vengono mostrati i risultati web tradizionali, garantendo trasparenza e controllo.
Come quasi tutti i chatbot basati sull’intelligenza artificiale, Gemini ha coltivato fin dall’inizio un aspetto minimalista. All’apertura dell’app, si presenta una schermata iniziale ordinata e, negli ultimi mesi, Google ha testato piccole modifiche all’interfaccia utente. Tuttavia, secondo le ultime indiscrezioni sembra che Google stia considerando un cambio più radicale del modo in cui gli utenti interagiscono con l’app.
[ad#ad-celli]
Nella versione 16.38.62.sa.arm64 dell’app Google è stata individuata una schermata iniziale Gemini riprogettata durante i test. Il layout attuale accoglie l’utente con un messaggio di benvenuto e scorciatoie per gli strumenti principali, come “Crea immagine” e “Ricerca approfondita“. Nel nuovo design, questi pulsanti si spostano verso l’alto per far spazio a un feed scorrevole di suggerimenti.
I suggerimenti visualizzati fungono da spunti di conversazione con un solo tocco. Alcuni evidenziano le capacità di Gemini in fatto di immagini, come “Datemi un look vintage”. Altri mettono in risalto abilità diverse, come l’invio di un notiziario quotidiano, un quiz di biologia di base o la programmazione di un piccolo gioco. Ovviamente essendo queste versioni ancora beta e non pensate per il pubblico, non si sa ancora quando e se questa nuova interfaccia farà capolinea su tutti gli smartphone nella versione stabile.
Hai dei file a cui vuoi poter accedere facilmente da qualsiasi device? Li puoi caricare su NextCloud! Devi scrivere un testo assieme ad un’altra persona che vive lontano? C’é Etherpad! Vuoi inviare un file in modo riservato? Puoi usare Lufi! Ti serve una mappa online? Ma c’é OpenStreetMap! Vuoi condividere uno status ma solo con alcuni amici intimi? Puoi farlo con Friendica! Devi cercare qualcosa sul web? C’é SearX!
Insomma: chi te lo fa fare di usare servizi centralizzati il cui solo scopo é carpire informazioni su di te, se ci sono provider online che mettono a disposizione i migliori software open source?
SIAM PASSATI DALL’ESSER PERSONE CHE UTILIZZANO STRUMENTI AD ESSER CLIENTI DI SERVIZI CHE CI USANO
La maggior parte degli utenti possiede dei device (smartphone, tablet, computer fisso o portatile…) ma non ha in casa un proprio server personale con cui gestisce ed archivia i propri contenuti. Questo perché esistono dei fornitori commerciali di servizi online (provider come Google, Apple o Facebook) che mettono comodamente e spesso “gratuitamente” a disposizione tutta quella serie di servizi che altrimenti bisognerebbe installare/impostare/aggiornare/riparare da sé. Affidarsi a provider esterni, dunque, a primo acchito risulta comodo perché libera dall’onere di imparare a gestire gli strumenti su cui si regge la propria vita digitale.
E’soprattutto nella seconda metà degli anni 2000 che si affermano i principali provider di servizi online. É in quel momento che si sviluppano aziende e strumenti come Dropbox, Evernote, Facebook, Google Docs, iCloud, Twitter, Whatsapp, YouTube ecc. Nel giro di pochi anni però, tramite acquisizioni e battaglie commerciali, la situazione che si é venuta a creare é che i principali servizi online sono proprietà di soli cinque colossi americani: Amazon, Apple, Facebook, Google, Microsoft.
Cinque aziende commerciali che hanno nelle proprie mani la vita digitale di ogni individuo del pianeta, alcune delle quali sono state fondate con l’esplicito scopo di raccogliere, analizzare e vendere tutte le informazioni che possono sui propri utenti.
Non tutti ci han fatto caso, ma mentre questi provider nascevano e si facevano ogni giorno più forti é avvenuto nelle nostre vite un importantissimo doppio cambio di paradigma. Il tutto é avvenuto in maniera esplicita, alla luce del sole e nient’affatto misteriosa, solo che é avvenuto tanto in fretta e con un tale hype nei confronti della “tecnologia del futuro” che la maggior parte delle persone non se n’é curata: 1) si é passati dallo “strumento come strumento” allo “strumento come servizio” ed alla 2) cessione volontaria dei propri dati sensibili in cambio dell’utilizzo di tali servizi.
Il concetto, insomma, é che si é passati dal “possiedo carta e penna su cui scrivo quel che mi pare e poi se voglio lo tengo chiuso in un cassetto oppure lo consegno a chi mi pare ma sempre senza dover render conto a nessuno della mia scelta” al “Posso usare la fantastica penna di lusso e la fantastica carta della ditta X per scrivere tutto quel che mi pare, alla sola condizione che la ditta X leggerà tutto ciò che scrivo e ne farà quel che vorrà”.
Tu, utente, non “hai” Whatsapp. Quando dici che “hai Whatsapp” stai dicendo una stronzata.
Non hai idea di quali informazioni su di te il software di Whatsapp trasmette ai server di Facebook(i millisecondi che sei stato fermo su una foto? se ne hai allargato un dettaglio? se l’hai salvata? se hai salvato una schermata con quella porzione di chat? quanti errori grammaticali fai? in quali ore dormi? quali sono le persone di cui cancelli le chat?).
Non sai in che modo questi dati vengono interpretati (il numero di emoji usati in relazione alle volte in cui usi certe parole? quali sono le parole che usi solo con certe persone? i tuoi riferimenti culturali più comuni in relazione con la mappa dei tuoi spostamenti? le opinioni che hanno su di te i tuoi “amici” e che si scambiano nei messaggi privati?).
Non sai in che modo Whatsapp ti profila (ha intuito che forse tra te e una certa persona c’é una tresca in base all’analisi dei vostri tracciati GPS ed ai messaggi fasulli che avete inviato? ha dedotto le tue debolezze emotive utilizzabili come grimaldello propagandistico da una forza politica che avversi per confonderti le idee?)
L’ultimo punto probabilmente é il più importante. Si sa, che spesso il problema non é in chi trasmette informazioni (tu), ma in chi le legge (Facebook). Se Facebook interpretasse dalla tua attività online che sei potenzialmente una minaccia per il governo in carica e questa informazione fosse venduta proprio a qualcuno che lavora per il governo in carica beh, a seconda della natura di tale governo potresti passare decisamente dei brutti momenti.
LA SOLUZIONE IDEALE É AVERE IL PROPRIO SERVER A CASA
Possiamo girarci attorno finché si vuole, ma la verità é che l’unico software su cui puoi avere la massima fiducia é software FLOSS installato da te su un tuo device di proprietà, a cui solo tu hai accesso.
Idealmente, dunque, un web veramente libero dovrebbe essere composto da innumerevoli device e server personali su cui sono installati gli strumenti software che ognuno preferisce e per far sì che questo non porti ad una eccessiva frammentazione delle piattaforme, idealmente e pur mantenendo la propria indipendenza, queste dovrebbero comunque possedere un certo grado di interoperabilità (ad essempio costituendo una rete federata). Si tratta di uno scenario tecnicamente realistico, molto vicino a quello delle prime reti BBS all’alba di Internet e che qualcuno sta effettivamente cercando di far prender nuovamente piede. Gli strumenti ci sono e funzionano già a dovere. Quel che gli manca é solamente un’adozione massiccia.
Certo é pur vero che l’idea di fare self-hosting (ossia il possedere un proprio server personalizzato) può spaventare molte persone, nonostante gli strumenti per realizzarlo siano sempre più alla portata di chiunque (come ad esempio YuNoHost un sistema operativo pensato proprio per server casalinghi gestiti da un utente inesperto, già predisposto per ospitare un’Istanza Nextcloud, Matrix, Mastodon, XMPP, WordPress, SearX, Tiny Tiny RSS, Wallabag e praticamente tutto quel che riguarda la vita digitale di ognuno).
Capiamoci: siamo nel 2019; i computer esistono ormai da eoni, ma anche a voler restare stretti e concentrarci solo sul periodo in cui questi sono entrati in massa nelle case, stiam parlando comunque di 25-30 annima la conoscenza media di questi strumenti é perlopiù limitata all’utilizzo più superficiale. La situazione può essere paragonata allo scenario in cui milioni di automobilisti che, pur sapendo guidare, ignorassero totalmente cosa siano il motore, le pastiglie dei freni o la batteria, ma si accontentassero di sapere che girare il volante a sinistra fa girare a sinistra anche le ruote, credendo così di sapere come funziona un’automobile.
Il fatto é che, come già detto, siamo nel 2019: non si pretende certo che tutti diventino dei provetti meccanici-hacker, ma almeno che si diffonda una conoscenza generale giusto un minimo più accorta. Insomma: basterebbe che si sapesse che sotto il cofano c’é una cosa chiamata motore e più o meno in base a quali princìpi funziona.
La cosa ancor più drammatica é che le conoscenze base per potersi muovere in campo informatico (una spolverata di teoria, imparare ad installare un sistema operativo, compiere operazioni di maintenance, usare motori di ricerca come si deve ed alcuni concetto-base di sicurezza informatica) possono essere apprese con un corso di sette giorni, meno che per la patente, ma nonostante l’utilizzo dei device informatici sia una costante su base quotidiana per milioni di persone, ancora troppo poche hanno “fatto il corso di sette giorni”.
STRUMENTI FLOSS
Come già esposto in altri articoli, esistono da anni diversi strumenti FLOSS (ossia software aperto, gratuito e liberamente utilizzabile) che non hanno nulla da invidiare ai loro corrispettivi commerciali. Anzi, in molti casi gli strumenti FLOSS sono pure tecnicamente più avanzati delle loro controparti, tanto che moltissimo software che utilizziamo quotidianamente (come Chrome o Whatsapp) non é che una versione modificata di software FLOSS. L’unica pecca del software FLOSS, semmai, deriva dal fatto che essendo utilizzao da meno utenti, spesso ha una quantità minore di contenuti: la quantità di roba che vien pubblicata sui social open durante una giornata equivale forse a quella che su Facebook vien pubblicato in un minuto. Di conseguenza vi é anche minor spinta a venir incontro agli interessi di un pubblico che si trova altrove. Si tratta della classica situazione del gatto che cerca di mordersi la coda: gli utenti non adottano un sistema se non ci son gran quantità di contenuti, ma non possono esserci gran quantità di contenuti se non ci sono utenti.
Per dirla in altro modo, tornando alla metafora automobilistica: finché tutti continueranno a voler usare ruote di legno, quel tizio strano che ha avuto l’idea di fare ruote di gomma resterà confinato nella sua bottega a fare le ruote di gomma una-ad-una per i suoi clienti affezionati, ma non riuscirà mai a metter su una fabbrica per produrle in serie. Questo a meno che non ci sia una forte spinta ad adottare in massa tali ruote di gomma, ma si tratta di una spinta che non verrà mai dalle grandi aziende produttrici di ruote di legno.
Una selezione di strumenti e piattaforme commerciali libere e la loro controparte commerciale
SERVIZI VISIBILI vs. VANTAGGI INVISIBILI
Una delle difficoltà maggiori riguardanti il software FLOSS é il riuscir a far capire il loro valore ad una popolazione che, come già detto, ha giusto delle vaghe conoscenze informatiche. Spiegare i vantaggi degli strumenti FLOSS a chi é privo di ogni base informatica spesso suona difficile come cercar di spiegare com’é possibile che gli aerei si librino nell’aria ad una popolazione vive nel terrore che la Luna caschi dal cielo.
Per esempio: quando si parla di privacy e protezione dei dati personali sul web, solitamente l’immagine che viene evocata dall’utente comune é quella del tizio parte-hacker-parte-007-parte-esattore-di-Equitalia che traffica sul web per carpire informazioni piccanti o spiacevoli sulla tua persona, ossia uno scenario da film complottista che, pur non essendo impossibile, nella maggior parte dei casi risulta alquanto improbabile: a chi mai interessa cosa faccia nella vita privata il signor Gino del quinto piano? Certo però che quelle stesse informazioni diventano estremamente interessanti se acquisibili in massa assieme a quelle di milioni di altre persone…
In realtà ciò che avviene nella maggior parte dei casi é che le informazioni dettagliatissime che hai fornito su di te vengono utilizzate all’interno dei cosiddetti big data per impostare argomentazioni politiche, saggiare il terreno su certi argomenti senza tener conto dello scarto fra vita reale e vita sul web e soprattutto, per modificare il discorso pubblico prevalente su determinate questioni.
Il tuo profilo, il tuo singolo profilo utente, di per sé ha scarso valore (a meno che tu non sia un VIP o un noto criminale). Ma se il tuo profilo fa parte di un bouquet di milioni di profili allora la cosa cambia!
Quel che avviene é che i committenti hanno modo di influenzare quali e quante informazioni riceverai, facendo sì che sui social certe notizie appaiano nella tua Timeline ma non in quella del tuo vicino o che ti venga suggerito si seguire certi contatti e non altri. Le informazioni che hai fornito su di te sono uno strumento impagabile affinché queste modifiche riescano ad essere cucite proprio apposta per te.
Non é un caso se milioni di persone vengono portate a credere a cose del tutto false o a consolidare idee che, se non ci fosse controllo sui contenuti che ricevono, non sarebbero difese con tanta irrazionalità. Chi manipola quel ti vien detto, non fa altro che indirizzare il tuo modo di pensare.
In poche parole, scegliere di utilizzare le grosse piattaforme centralizzate del data-mining (letteralmente “estrazione dati”, ossia ciò che fanno Facebook, Google ecc) equivale a buttarsi nel mare in cui viene effettuata la più imponente e specialistica pesca a strascico del mondo: una pesca a strascico smart che se da un lato coinvolge tutti i pesci nel mare, nessuno escluso, dall’altro non uccide i pesci, ma li lascia in acqua, studiandoli tanto a fondo da capire come fare a far sì che ogni singolo pesce poi nuoti nella direzione che il pescatore desidera.
In sostanza più informazioni personali forniamo alle grandi compagnie di data mining e più aiutiamo chi manipola le informazioni sui media mainstream; più aiutiamo chi vuole seminare odio in maniera mirata; più aiutiamo le società di marketing a renderci dipendenti dai loro prodotti. Un esempio su tutti? In Italia, da anni, il numero di crimini violenti é in calo costante. Non é una novità: ogni anno i quotidiani pubblicano i nuovi dati e da anni, appunto, si annuncia che sono calati rispetto all’anno prima. Eppure la percezione diffusa é che invece siano in aumento. Stessa cosa per il numero di stranieri residenti in Italia: oltre il 73% degli italiani ne sovrastima il numero. Certo, la percezione pubblica non viene modificata dai soli social, anche i media hanno un ruolo fondamentale in questo, ma é innegabile che oggi il grosso di questo lavoro avvenga proprio sui social.
I recenti scandali legati a Facebook, Cambridge Analytica, la Brexit,il Russiagate ed i sospetti di intervento esterno sui social durante diverse campagne elettorali non sono che l’aspetto più macroscopico e noto dell’intreccio fra big data, politica e manipolazione dell’opinione pubblica.
Ecco, tutto questo fa parte di ciò che l’utente medio fa fatica a vedere e tra un’app per mandare immagini di gattini con musichette carine ed un’app che fa lo stesso ma meno pubblicizzata e usata da meno utenti, sceglierà la prima, anche se la seconda ha caratteristiche migliori ed é più adatta a proteggerne le informazioni personali.
Socialità quantitativa e strumenti che necessitano apprendimento raso-zero sono, purtroppo, i fattori determinanti per la scelta delle piattaforme da utilizzare. Restando all’esempio automobilistico, é come dire che il mondo preferisce le auto senza specchietti, frecce, cinture di sicurezza ed altri dispositivi di protezione “perché é roba da nerd maniaci” e si é adattato a ritenere che beh, é normale che ogni automobilisca faccia qualche incidente e perda qualche arto.
PROVIDER OPEN SOURCE
Se proprio non si ha modo o voglia di self-hostare i propri strumenti software, un buon compromesso fra self-hosting ed il ricorso ai provider di servizi commerciali come Facebook o Google é quello di rivolgersi a dei provider online di software open source. In pratica, se Google mette a disposizione i suoi strumenti (Google Calendari, Contatti, Drive, Mail, Ricerca, Documenti, Fogli, Presentazioni, ecc…) ed anche Apple fa altrettanto con i propri (iCloud, Contatti, Pages, Numbers, ecc…), così come fa Facebook (Facebook, Messenger, Instagram, Whatsapp) e tutti quei provider che mettono a disposizione il proprio unico strumento (L’azienda Evernote mette a disposizione lo strumento Evernote, l’azienda Twitter mette a disposizione lo strumento Twitter ecc.) esistono anche diversi provider che invece mettono a disposizione applicazioni FLOSS che, se l’utente volesse, potrebbe tranquillamente scaricarsi e installare su un tuo server personale, essendo tutto software aperto e liberamente scaricabile (quindi, chiunque abbia le necessarie competenze tecniche, può verificare cosa fa davvero il software “sotto il cofano” e come).
La comodità di questa soluzione é indubbia: hai un server sempre attivo accessibile 24/24 che viene mantenuto efficiente, aggiornato e riparato da qualcun’altro cosicché tu possa accedervi senza problemi.
L’idea alla base dei provider di applicazioni FLOSS é che anziché esserci solo 4 o 5 colossali provider cui si rivolgono tutti, possano invece esserci centinaia, migliaia, milioni di server che offrono una vastità di strumenti che però siano compatibili tra loro o addirittura federati.
Una piccola digressione: Framasoft é un provider che fornisce una propria Istanza Mastodon, mentre Bida é un altro provider che fa altrettanto. Pur essendo due provider distinti (sotto un certo punto di vista é come dire Apple e Facebook) entrambi mettono a disposizione lo stesso strumento, Mastodon, che ha la peculiarità di essere federato. Ciò significa che gli utenti che usano l’Istanza Mastodon di Framasoft e quelli che usano l’Istanza Mastodon di Bida potranno interagire fra loro come se fossero su un’unica grande chat. Volendo fare un paragone, sia iChat che Whatsapp, i software di chat di Apple e Facebook, sono stati entrambisviluppati in base ad XMPP, che é software FLOSS. Questo vuol dire che tecnicamente sarebbe semplicissimo far dialogare tra loro Whatsapp ed iMessage, ma ciò non avviene puramente a causa di bagarre commerciali.
A questo punto però sorge spontanea una domanda: perché non fidarsi di Facebook e Google ma fidarsi di un provider open source? Si tratta pur sempre di dover riporre fiducia in qualcuno che (presumibilmente) non si conosce ed a cui si affidano i propri dati personali. L’osservazione é in effetti corretta e l’unica risposta sensata é che così come non ci si può fidare dell’uno non ci si dovrebbe fidare nemmeno dell’altro.
Ma ci sono dei “ma”.
Innanzitutto i maggiori provider di servizi commerciali come Facebook e Google sono ESPLICITAMENTE basati sulla lettura, analisi e compravendita dei contenuti che noi forniamo. Da cosa guadagnano Facebook e Google? Qualcosina sì dalla pubblicità, ma il grosso dei guadagni, quello che ha rende Mark Zuckerberg uno degli uomini più ricchi del mondo, é la vendita delle informazioni degli utenti.
ETICA DICHIARATA: Dall’altra, la maggior parte dei provider open source é realizzata e mantenuta da persone, comunità e collettivi che esplicitamente combattono l’utilizzo a fini commerciali delle informazioni degli utenti. Ci si può fidare o meno, ma rivolgersi ai big equivale alla certezza che la vendita dei propri dati avvenga.
SOFTWARE NON TRACCIANTE: Il software utilizzato é caratterizzato dal fatto di chiedere solo i dati strettamente necessari per funzionare (talvolta non chiedono proprio nulla) in modo da ridurre al minimo le possibilità di profilazione dell’utente. Certo, un provider potrebbe aver modificato il software sul suo server senza dichiararlo, ma come vedremo nei prossimi punti, potrebbe essere un’opzione poco interessante per il provider stesso.
FRAMMENTAZIONE INTERNA: I vari servizi offerti dai provider di software open source sono spesso scollegati fra loro. Questo significa che di solito non c’é un’unico nome utente e password per tutti i servizi. In questo modo se anche usassi in contemporanea l’Istanza Mastodon ed i fogli di calcolo dello stesso provider, lui potrebbe credere che ciò venga fatto da due utenti diversi.
FRAMMENTAZIONE PERSONALE: Nulla t’impedisce di rivolgerti a più provider contemporaneamente, frammentando le tue informazioni personali un pò qua ed un po là. Se due o più profider forniscono gli stessi software (per esempio NextCloud), usare l’uno o l’altro non comporterà alcuna difficoltà di apprendimento. Ad esempio puoi usare l’Istanza Mastodon del provider A, il server Matrix del provider B e gli strumenti office del provider C e gestirli come se fossero di tre utenti differenti, in modo che nessuno di questi abbia la totalità delle informazioni sul tuo conto.
FRAMMENTAZIONE GLOBALE: Se le informazioni di tutti stanno su Facebook e Google, é sufficiente acquistare informazioni da quei due provider per avere un database su milioni di persone. Se invece questi milioni di utenti fossero sparpagliati su migliaia di server interconnessi da poche migliaia di utenti l’uno, chi volesse farsi un database altrettanto massiccio dovrebbe contattare (o hackerare) uno-ad-uno migliaia di server. Lo sforzo sarebbe di per sé immane. Se poi si considera che, come visto, le informazioni che si troverebbero in mano sarebbero molto meno dettagliate ed interessanti di quelle fornite da Facebook, é chiaro che i server di servizi FLOSS risultano strutturalmente poco utili per chi vuol commerciare informazioni personali.
CHE STRUMENTI VENGONO MESSI A DISPOSIZIONE?
Gli strumenti messi a disposizione dai provider sono un’infinità e spaziano dagli strumenti per ufficio (scrittura collaborativa, fogli di calcolo, mappe mentali), web hosting (tipo Dropbox, iCloud, Google Drive ecc.), social, chat personali, strumenti per programmatori… Per farla breve: pensa ad un servizio online che usi comunemente ed e sappi che ne esiste anche la versione libera e aperta, fatta eccezione giusto per i fornitori di media mainstream coperti da copyright come Spotify o Netflix e iTunes, ecco, ma se pensi a Evernote, Dropbox, Twitter, Facebook, Google Maps, Gmail, Whatsapp, le ricerche su Google, iWork e tutti quegli strumenti che usi quotidianamente online beh, ognuno di questi ha la sua controparte libera!
Alcuni di questi strumenti sono parzialmente sovrapponibili; un esempio é l’applicazione Turtl che é sia un gestore appunti (Notebook) che uno strumento per archiviare link interessanti (Bookmark manager) che fa dunque un pò quello che fa Evernote ed un pò quello che fa Pocket. Questo per dire che in alcuni casi la definizione usata per classificare questi strumenti può essere poco esaustiva.
Altra cosa interessare é che uno stesso provider può mettere a disposizione più strumenti che fanno la stessa cosa (ad esempio due diversi tipi di calendario o di strumenti di scrittura). La cosa può confondere un attimo chi non é abituato a dover scegliere tra opzioni diverse con uno stesso provider, ma va tutta a favore della personalizzazione (ti trovi scomodo ad usare EtherPad? Nessun problema: abbiamo anche PadLand!)
Certi strumenti software sono molto popolari e vengono messi a disposizione da diversi provider (per esempio, chi offre un servizio di data hosting nel 99% dei casi utilizza NextCloud), che però ne personalizzano un pò l’estetica, a volte alcune funzioni e spesso anche il nome (per esempio, il server Nextcloud messo a disposizione da Framapiaf viene chiamato “Framadrive”). Altri invece, sono più rari.
ELENCO PROVIDER OPEN SOURCE
Questo post non é incentrato sulle funzionalità dei singoli strumenti software e qui si vuol solo elencare una serie di provider di strumenti FLOSS che, volendo, un utente potrebbe anche installarsi su un proprio server. Pertanto l’elenco non comprende siti che mettono a disposizione un unico strumento software (tipo mastodon.social che mette a disposizione solamente la propria Istanza Mastodon) e/o strumenti software non hostabili privatamente (tipo DuckDuckgo)
A/I é il principale riferimento italiano per quanto riguarda collettivi antagonisti e anticapitalisti impegnati per i diritti digitali. Offre tutta una serie di strumenti con un fortissimo occhio di riguardo a sicurezza e protezione dati.
Disroot é un’organizzazione di hacktivisti di impronta libertaria impegnata a far conoscere le tecnologie aperte ed a diffondere una maggior cultura della privacy informatica.
Framasoft é un’importante associazione francese il cui scopo é quello di diffondere l’uso di tecnologia FLOSS. Framasoft organizza incontri, corsi ed un gran numero di attività diverse. In particolare sta portando avanti il progetto di de-googleizzare il web, facendo conoscere tutti gli strumenti già esistenti ed utilizzabili anche senza dover per forza rivolgersi alle big company dell’informatica. Gli strumenti che offre Framasoft sono davvero tantissimi e non sarà possibile elencarli tutti, ma ci si prova. Una caratteristica particolare é che Framasoft ribattezza gran parte degli strumenti offerti “Frama(qualcosa)”. Il sito é in francese ma gran parte é tradotto in inglese e sempre più pagine sono tradotte anche in italiano.
Librem é il marchio dei prodotti e servizi open dell’azienda Purism. Purism produce computer desktop e smartphone di alta fascia che promettono una alta attenzione al rispetto della privacy e della sicurezza informatica. I servizi della linea Librem derivano da strumenti FLOSS che però vengono fortemente personalizzati e rinominati “Librem(qualcosa)”; per esempio, il server Mastodon offerto da Framasoft si chiama FramaPiaf.
Nixnet é creato e gestito apparentemente da una sola persona, Amolith, che mette a disposizione gli stessi strumenti che lui utilizza. Molto servizi sono utilizzabili anche attraverso TOR e c’é forte attenzione su sicurezza e criptatura dei messaggi.
RiseUp é un collettivo di Seattle ma con membri sparsi in tutto il mondo. É attivo dal 1999 e si adopera per una società libera ed una lete altrettanto libera.
Google é indiscutibilmente il principale motore di ricerca online, tanto che l’atto di cercare qualcosa sul web viene espresso col suo nome (“non sai nulla di questo argomento? Googolalo!”).
Uno dei motivi del successo di Google é che si tratta di un ottimo motore di ricerca, effettivamente capace di trovare quel che cerchi nella stragrande maggioranza dei casi.
D’altro canto Google é anche un’azienda imponente e ramificata che vive di raccolta e vendita dati, che si ricorda cos’hai cercato, quando e quante volte e che collega queste informazioni ad altre che ha raccolto su di te attraverso una miriade di servizi che affiancano quello di ricerca web. E questo é un grosso problema! Un grosso problema che é sotto gli occhi di chiunque ma che al tempo stesso viene raramente affrontato.
Ciò che é poco noto, invece, é che la maggior parte dei suoi servizi può benissimo esser sostituita con altri meno invasivi, compreso il motore di ricerca.
Google é utilizzato per oltre il 90% delle ricerche online
Sostituire il motore di ricerca di Google é certamente un passo importante per arginare il pericolo di avere un’unica azienda a controllo di tutti i dati che forniamo ogni volta che facciamo una ricerca online. Dati che vengono spiati, raccolti, classificati e venduti.
Oltre a Google difatti esistono diversi motori di ricerca validi. Parte di questi in realtà sono assai specifici ed utilizzabili solo per ricerche assai specifiche (ad esempio TinEye per il reverse search di immagini), ma la maggior parte consente di fare ricerche generiche e funziona in modo molto simile Google.
Per proseguire é però necessario comprendere alcuni concetti base su cui si poggia un motore di ricerca. Uno dei componenti base di un motore é il suo CRAWLER(può essere reso con “ispezionatore”), ossia un programma che naviga in automatico nel web, saltando di link in link e registrando nei database del motore di ricerca ogni parola, immagine, file che trova (creando quella che viene chiamata “copia CACHE”). Una volta che il crawler ha scoperto e registrato i contenuti, il motore di ricerca classifica ogni contenuto attraverso un proprio ALGORITMO.
Un buon crawler idealmente trova il 100% dei contenuti di un sito ed un buon algoritmo é in grado di classificare come si deve ogni contenuto. Al contrario un cattivo crawler potrebbe non scoprire mai l’esistenza del tuo sito o scoprirne solo una parte ed un cattivo algoritmo, quando cerchi informazioni su “spaghetti” potrebbe mettere nei primi risultati pagine che non parlano della pastasciutta ma i post di un tizio che si firma “Mr. Spaghetti” (chi si ricorda i primi motori di ricerca degli anni ’90 conosce bene questo tipo di situazioni). Ogni motore di ricerca usa un proprio crawler ed un proprio algoritmo, diversi da quelli degli altri motori.
Non va poi sottovalutato l’intervento umano: é per scelta degli amministratori di Google ad esempio che certi siti compaiono sempre in testa ai risultati (come Wikipedia quando si cerca il nome di una persona nota o Booking quando si cercano località turistiche). É sempre per una scelta voluta che i suggerimenti di ricerca di Google non contengano mai termini volgari o riferimenti a contenuti per adulti.
PRINCIPALI DIFFERENZE CON GOOGLE
Chi utilizza per la prima volta un motore di ricerca diverso dal onnipresente Google non può non notare che questi restituiscono risultati diversi.
SERP DIFFERENTI: Ognuno di questi motori genera per ogni ricerca dei risultati un pò diversi (tecnicamente S.E.R.P.: Search Engine Results Page): quello che per Google é il primo risultato, per un altro motore di ricerca può essere il decimo. Questo può dipendere da principalmente dal crawler e dall’algoritmo usati.
IMMAGINI, NEWS ECC: Molti motori di ricerca sono focalizzati sulla ricerca di pagine web e dunque peccano dal lato di ricerca news e immagini
RICERCA AVANZATA: Google offre diversi strumenti di ricerca avanzata che spesso mancano agli altri motori di ricerca, per esempio Google Trends o la possibilità di visionare la pagina cache.
Un paio di motori di ricerca alternativi a Google sono ad esempio:
É più o meno riconosciuto come il principale motore alternativo a Google. I risultati di ricerca sono ottimi, anche per la ricerca immagini, ma pecca riguardo alle news. L’azienda proprietaria, statunitense, si pubblicizza come molto focalizzata su privacy e sicurezza e parte del software é open source. Si finanzia pubblicando inserzioni pubblicitarie e tramite affiliazioni.
Motore di ricerca realizzato in Francia. Anch’esso si promuove come fortemente incentrato sulla privacy degli utenti. I risultati sono molto buoni anche per quanto riguarda immagini e news. Si finanzia in parte ricevendo commissioni da alcuni grossi portali a cui indirizza il traffico e in parte tramite finanziamenti pubblici.
L’elenco completo sarebbe lunghissimo e includerebbe Bing, Yahoo, Lycos, WebCrawler e molti altri (un elenco dettagliato é disponibile in questa pagina Wikipedia). Quel che però appare già evidente é un che motore di ricerca per esistere ha necessità di molti fondi per poter reggere economicamente (basta solo vedere le dimensioni delle serverfarm di Google per rendersi conto dei costi spaventosi che genera) e ciò causa immancabilmente una situazione da gatto che si morde la coda, con i motori di ricerca che alterano i propri risultati per favorire gli sponsor e vendono i dati di navigazione dei propri utenti (data mining) per poter garantire a quegli stessi utenti un servizio costante e sempre aggiornato.
Inoltre ognuno di questi motori di ricerca appartiene sempre ad una sola azienda, la quale si trova dunque sempre in condizione di poter manipolare i risultati. Insomma, non se ne esce fuori: per quanto possano esser buone le intenzioni e le persone che li gestiscono, i comuni motori di ricerca sono strutturati in modo tale da lasciare in mano ai loro gestori un potere considerevole nei confronti degli utenti. Come se ne esce?
METAMOTORI DI RICERCA
Una prima soluzione é quella di usare un metamotore di ricerca, ossia un motore che non si sbatte a ispezionare il web e classificarne i contenuti (ergo: non fa crawling), ma trasmette la tua ricerca a motori di ricerca veri e propri e ne assembla i risultati. Si tratta, in poche parole, di un “motore di motori di ricerca”.
Un metamotore di ricerca non fa altro che assemblare i risultati di altri motori di ricerca.
Se cerchi “spaghetti” su un metamotore di ricerca (ad esempio SearX), questo cercherà “spaghetti” su dei motori di ricerca veri e propri, come Google, DuckDuckGo e Qwant, e poi restituirà una S.E.R.P. ottenuta assemblando quello che i motori han trovato.
In questo modo, per capirci, tutti gli utenti che utilizzano il metamotore di ricerca, verranno intesi da Google come un unico, gigantesco utente che fa un numero talmente elevato e variegato di ricerche da divenir inclassificabile. Il metamotore di ricerca, tuttavia, potrebbe sempre tener traccia di quel che fai tu. É già qualcosa.
MOTORI COLLABORATIVI (P2P ETC.)
Una seconda soluzione é quella di utilizzare una soluzione collaborativa tra server e/o utenti diversi in modo da formare assieme un grande motore di ricerca. Qui incontriamo nuovamente il concetto di reti decentralizzate e distribuite già descritte nei post sul Fediverso e su Mastodon.
Riassumendo: una rete centralizzata (A) é come Google, in cui tutti gli utenti si rivolgono idealmente ad un unico server chiamato Google che detiene il totale controllo dei dati. Una rete decentralizzata (B) é formata da più server che collaborano fra loro, dando la possibilità ad ogni utente può scegliere a quale server connettersi (il quale può avere delle peculiarità diverse rispetto agli altri) e da qui può interagire con gli altri server della rete. Una rete distribuita (C) invece, é una rete in cui ogni singolo utente funge da server di sé stesso e, in maniera del tutto indipendente, può connettersi ad altri utenti con cui interagire.
Come si traducono questi tipi di rete con i motori di ricerca? Prendiamo ad esempio una rete decentrata ed immaginiamoci l’esistenza di diversi server, su ognuno dei quali é stato installato lo stesso software di motore di ricerca. Ognuno di questi server ha il suo crawler che ispeziona il web e si crea il proprio database con le informazioni sulla porzione di Internet che ha ispezionato (“porzione” perché si parte dal presupposto che ognuno di questi server sia di per sé troppo piccolo perché possa ispezionarlo tutto). Ognuno di essi é un piccolo motore di ricerca che magari conosce perfettamente una certa parte del web (ad esempio, solo i siti in italiano). Ma qui viene il bello: in una rete decentralizzata diversi server possono interagire fra loro, in modo tale che, messi assieme, formino una sorta di mega-motore di ricerca diffuso su scala globale.
Qui la cosa si può già fare molto interessante: i diversi server potrebbero sì condividere e scambiarsi informazioni andando a formare assieme un unico database comune da cui attingere informazioni e tuttavia essere personalizzati per presentare S.E.R.P. personalizzate. Potresti dunque scegliere di fare la stessa ricerca su diversi server specializzati in modo differente. Per esempio, un certo server potrebbe essere impostato per mostrare solamente contenuti adatti ai bambini, un altro potrebbe dare la precedenza ai contenuti più nuovi e un altro ancora potrebbe organizzare i risultati escludendo fonti ritenute inattendibili.
Oltre a tale personalizzazione dei risultati, i server potrebbero scambiarsi anche diverse informazioni tecniche aiutandosi vicendevolmente a mappare meglio porzioni di web e classificarne i contenuti.
A questo punto é facile capire che una rete distribuita funzionarebbe allo stesso modo, ma in questo caso non sarebbero solo i diversi server a partecipare a questo lavoro collaborativo, ma pure i singoli computer dei singoli utenti. Per capirci: su ogni computer si avrebbe installato del software che si occupa di ispezionare il web comunicando al database diffuso quel che ha scoperto ed archiviando una porzione di esso sul proprio disco fisso. Ogni utente inoltre potrebbe personalizzare a proprio piacimento personale il modo ed ordine in cui comparirebbero i risultati di ricerca.
SearX é un metamotore di ricerca open source. Il suo software é liberamente scaricabile, modificabile ed installabile da chiunque sul proprio computer o su un server che può esser anche reso pubblico. In effetti sono già oltre un centinaio i server SearX pubblici noti e molti di questi presentano delle caratteristiche proprie. É un pò come dire che ci sono cento versioni diverse di Google. SearX non é un motore collaborativo e quindi ogni singola macchina con installato SearX funziona in maniera del tutto scollegata dalle altre.
Tra i tanti server SearX pubblici, possiamo ad esempio osservare e fare un paragone tra https://search.disroot.org/, ovvero la versione di SearX installata sui server dell’organizzazione Disroot, e https://framabee.org/, la versione di SearX installata sui server dell’associazione FramaSoft. Oltre alle diversa veste grafica, basta fare una semplice prova per osservare quanto cambino i risultati (PS: search.disroot é impostata decisamente meglio).
Inoltre SearX permette ad ogni utente di personalizzare diversi fattori, anche molto tecnici. Ad esempio é possibile selezionare su quali motori di ricerca deve basarsi SearX, differenziandoli a seconda che si tratti di ricerche generali, di immagini, news, o documenti. Si possono impostare diverse preferenze riguardanti il tracciamento e la modalità di organizzazione dei risultati. Ogni server SearX dunque fornisce risultati diversi a seconda di come é stato impostato e può permettere un certo grado di personalizzazione all’utente. Una caratteristica interessante di SearX é che utilizza come cache i salvataggi pagina su archive.org.
Per quanto riguarda la qualità dei risultati, dunque, molto dipende dal server SearX scelto. La S.E.R.P. principale di https://search.disroot.org/ non é affatto male, tranne che per immagini e notizie, ma questo sembra essere una mancanza dello stesso software SearX e non una caratteristica del server specifico. Oltre alla minor qualità dei risultati su immagini e news mancano diverse comode funzioni presenti in Google: non c’é la ricerca per colore e non é presente alcun aggregatore di notizie.
Yacy invece é un motore di ricerca distribuito e collaborativo basato su P2P. Si tratta di un progetto molto piccolo e, allo stato attuale, troppo complesso per poter esser davvero proposto come alternativa ai più comuni motori di ricerca disponibili online. A livello di usabilità risulta ancora abbastanza macchinoso, in quanto sono più le occasioni in cui non restituisce alcun risultato di quelle in cui trova qualcosa, come é possibile verificare in questa pagina demo.
Tuttavia va segnalato anche a chi non é interessato ad uno strumento ancora in via di sviluppo perché già allo stato attuale permette di far capire come funziona una rete collaborativa che costruisce assieme un database comune distribuito.
Ipoteticamente, una rete distribuita é quasi indistruttibile: in uno scenario in cui tutti i computer del pianeta facessero parte della rete Yacy, anche se la maggior parte di questi fosse improvvisamente tagliata fuori o distrutta da un colossale meteorite, é sufficiente che solo una minima parte resti attiva perché tutto il database comune resti attivo. Progetto interessantissimo dunque, ma che dovrebbe essere reso molto più user-friendly per sperare in una adozione di massa. Chi volesse provare ad installarselo e smanettarci lo trova qui.
IN CONCLUSIONE
Esistono diverse alternative al motore di ricerca di Google, alcune molto valide come DuckDuckGo ed altre meno, ma gli strumenti già disponibili permettono a di poter fare tranquillamente a meno delle ricerche su Google.
Anche la prassi di utilizzare diversi motori di ricerca per ricerche di diverso tipo può essere un modo per non diffondere su una sola piattaforma tutte le informazioni che solitamente vengono messe in mano a Google. Esistono poi strumenti come SearX che, nonostante alcuni limiti, possono contribuire ulteriormente a creare una maggior distanza tra sé e le compagnie di data mining come Google e, potenzialmente, qualsiasi grosso motore di ricerca centralizzato. Gettando lo sguardo ancora più avanti, poi, osserviamo strumenti come Yacy che, idealmente, potrebbero davvero contribuire a riportare in mano alle persone il controllo dei propri dati ma questo, a patto che ci sia al tempo stesso uno sforzo da parte degli sviluppatori di semplificare tali strumenti ed uno sforzo da parte degli utenti per imparare a districarsi meglio nelle complessità dell’informatica.
Non sarebbe male arrivare un giorno ad avere un motore di ricerca collaborativo distribuito, magari pure ibridato con un metamotore di ricerca capace di confrontare la propria S.E.R.P. con quella fornita da altri motori che non fanno parte della rete condivisa. Una sorta di fusione tra SearX e Yacy in cui possano partecipare sia server dedicati che i singoli utenti, andando a formare reti federate di ricerca.
La maggior parte delle persone si affida ogni giorno a Google per rispondere a domande e fare delle ricerche, ma non sempre trova quello che cerca. Il motore di ricerca di Google è estremamente potente e dispone di molti operatori di ricerca specializzati che è possibile utilizzare per limitare l’ambito di analisi o per eseguire… Leggi tutto »Utilizzare la ricerca di Google in modo avanzato
OSM non è semplicemente una mappa online libera e gratuita ma un ricchissimo database geografico attorno al quale ruota un’infinità di progetti, App e iniziative.
Se si parla di mappe nella maggior parte dei casi si pensa alla mappa del navigatore, ad una cartina stradale oppure a un Atlante ma in realtà ci sono mappe di tipo diversissimo: carte nautiche, stradali, da escursionismo, turistiche, quelle che mostrano le caratteristiche fisiche di un territorio, quelle che ne mostrano i confini amministrativi e molte altre ancora. Tanta varietà dipende tal fatto che ognuna di queste mappe è concepita per un certo utilizzo specifico ed ha dunque interesse a evidenziare solo alcuni degli aspetti del territorio che prende in considerazione. Le mappe dei navigatori per automobili ad esempio non mostrano i sentieri su cui non è possibile andare in automobile mentre le mappe da escursionismo, al contrario, non riportano informazioni sui semafori. E’ giusto che sia così: una mappa che mostrasse tutti, ma proprio tutti gli elementi presenti su un dato territorio risulterebbe completamente inutile ed illeggibile: proviamo solo ad immaginare quanto sarebbe difficile pianificare un percorso tra Roma e Firenze su una mappa che indicasse ogni singolo semaforo, cartello stradale, idrante, cancello, sentiero, panchina, fontanella, cartellone pubblicitario, attraversamento pedonale, rivolo d’acqua, spartitraffico, tombino, numero civico, ringhiera, ecc…
Una mappa delle linee ferroviarie italiane.
Anche le mappe solitamente utilizzate dai principali navigatori per automobili, difatti, per quanto ci possano sembrare complete in realtà sono concepite per un utilizzo generalista e riportano solo una selezione di elementi. Difatti sono in grado di calcolare il percorso per raggiungere una città che sta a 200km di distanza ma nella maggior parte dei casi non sanno dirci se nei dintorni c’è una fontanella a cui abbeverarci. O ancora: sulle mappe digitali maggiormente utilizzate, zommando all’indietro per far stare l’intera penisola italiana nello schermo vedremmo comunque ben evidenziate le autostrade, ma a ben vedere se osservassimo davvero l’Italia da quell’altezza, ad esempio dall’ISS, le autostrade non si noterebbero affatto. Si tratta ovviamente di una rappresentazione grafica artificiosa, voluta perché quelle mappe sono state concepite per un uso stradale e dunque è stato scelto di enfatizzare quel dato. Le mappe digitali più note, essendo realizzate dalle big tech americane, sono principalmente interessate a fornire un servizio buono per un uso generico e con una caratterizzazione fortemente commerciale: Google Maps difatti ci può dire a che ora apre un centro commerciale di un’altra città ma non ci sa dire se nei dintorni c’è una panchina. Il carattere commerciale di un servizio di mappe online, dunque, è un elemento determinante nel tipo di informazioni che la mappa stessa riporterà.
Una mappa catastale contiene un sacco di informazioni utili, ma se vuoi recarti di persona sul lotto 582bis ti conviene usare una mappa stradale per orientarti
Che si tratti di mappe commerciali o meno tuttavia appare subito evidente un primo problema: per farsi un’immagine completa di un certo territorio è necessario utilizzare più tipi di mappe, ognuna delle quali ha una propria funzione specifica, una grafica distinta, utilizza simbologie diverse dalle altre, una diversa scala e presentare incompatibilità con le altre. Se si volesse fare un’escursione orientandosi con Google Maps per raggiungere in auto il punto di partenza ed un navigatore escursionistico Garmin per l’escursione a piedi, uno dei due potrebbe segnalare un parcheggio che l’altro non riporta o nomi di vie di campagna non corrispondenti.
L’Istituto Geografico Militare Italiano realizza mappe estremamente precise ma concepite per un tipo d’utilizzo che le rende inadatte ad esser usate come semplice stradario
Vi sono anche infinite esigenze particolari solitamente non considerate da chi realizza mappe commerciali: chi vola in deltaplano, ad esempio, spesso deve barcamenarsi tra mappe escursionistiche che indicano correttamente rilievi ed altitudini e mappe di diverso tipo ove invece è indicata la presenza di pali elettrici e cavi dell’alta tensione (dai quali i deltaplanisti voglion comprensibilmente stare alla larga). Riassumendo: se da un lato ricorriamo costantemente all’uso di mappe, dall’altro il panorama offerto dal ben vasto mondo della cartografia presenta diversi problemi:
Un’unica mappa completissima uguale per chiunque risulterebbe inutile ed illeggibile.
Ricorrere costantemente a mappe differenti può esser problematico ed a volte genera più interrogativi che risposte.
Le mappe commerciali, per loro stessa natura, non sono adatte ad esser impiegate per esigenze specifiche.
OPENSTREETMAP
Ecco dunque arrivare in nostro aiuto OpenStreetMap (abbreviato: OSM), che è qualcosa di estremamente più potente e completo di qualsiasi altra mappa digitale conosciuta. Prima di spiegare cosa la rende tanto unica vediamo velocemente quali sono le origini e la natura del progetto.
Nata nel 2004 da un’idea di Steve Coast, OSM cresce rapidamente per strutturarsi come una fondazione non a scopo di lucro con sede in Inghilterra e che ha come fine la creazione di un gigantesco database di dati geografici liberamente ed accessibili a chiunque gratuitamente. OSM difatti sposa in toto le filosofie del software libero e della libera circolazione delle informazioni (anche il software con cui OSM viene realizzato è a sua volta open source). Il progetto di OSM dunque consiste nel raccogliere ed elaborare costantemente un grandissimo numero di informazioni geografiche possibili facendole analizzare da una vastissima comunità di volontari ed armonizzarli in un unico database aperto. Tutti quegli elementi che, come detto prima, se mostrati tutti assieme renderebbero una mappa illeggibile (i singoli tombini, i tre gradini sul marciapiede, ecc), possono essere inseriti nel database OSM. Sotto molti aspetti il progetto OSM può esser definito come una sorta di “Wikipedia cartografica” anche se però vi sono delle differenze sostanziali: Wikipedia difatti è nota per esser spesso caratterizzata da problemi derivanti dal mito del “punto di vista neutrale” e dal fatto che le regole interne di Wikipedia sono spesso aggirate da gruppi che si organizzano appositamente per imporre le proprie posizioni politiche. OSM, al contrario, trattando dati geografici è molto meno soggetta a questo tipo di problematiche che tuttavia, anche se in forma più circoscritta, non mancano nemmeno qui (pensiamo ad esempio ai confini contesi tra nazioni in conflitto). In linea generale però le divergenze che possono verificarsi all’interno della comunità OSM sono più che altro di tipo tecnico e concettuale.
COME SI FINANZIA? OSM viene finanziata da donazioni da parte dei membri e di diversi enti, università ed aziende che, come vedremo, sono perfettamente conscie dei vantaggi che derivano dal poter utilizzare liberamente un corpus di informazioni geografiche vastissimo e sempre più preciso. Vigili del fuoco, protezione civile, pronto soccorso, associazioni umanitarie, università ma anche aziende come Amazon e Facebook utilizzano i dati di OSM a proprio vantaggio e dunque hanno un forte interesse a collaborare alla sua realizzazione o finanziarla.
DA DOVE OTTIENE I DATI E COME LI GESTISCE? Le fonti da cui OSM pesca i dati sono estremamente variegate: usa le mappe digitali fornite da diversi enti pubblici sparsi sul globo, mappe catastali, si fa consegnare i tracciati dei sentieri dai club alpinistici, raccoglie dati forniti volontariamente dagli utenti di alcune App, ottiene la concessione di dati satellitari e così via.
OSM raccoglie e unifica una moltitudine di dati di natura diversissima spesso provenienti da enti diversi: informazioni sui terreni, sui percorsi d’acqua, strade, segnaletica, numeri civici, informazioni commerciali ecc.
Tutti questi dati di natura e formato diversi vengono costantemente elaborati ed armonizzati nell’immenso database OSM da volontari che ne verificano la correttezza tramite strumenti software ed apportano manualmente correzioni e aggiunte. Si tratta, insomma, di un lavoro continuo e minuzioso estremamente complesso gestito con metodo e costante revisione: volontari esperti verificano la correttezza dei dati aggiunti dai meno esperti, ci sono forum di discussione, workshop periodici ecc.
DATI GEOGRAFICI VS. MAPPE
OSM come si è detto, non è banalmente una mappa bensì un database geografico. Che cosa vuol dire esattamente? Analogamente a quanto già esposto parlando dei Feed RSS e dei Frontend alternativi anche qui è necessario tener bene a mente la differenza tra un DATO e la sua RAPPRESENTAZIONE GRAFICA. Un dato è semplicemente un’informazione cruda, una stringa di testo nel database OSM in cui c’è scritto un valore. Per esempio “fontanella pubblica”. La sua rappresentazione grafica è il modo in cui questo dato viene mostrato sulla mappa. In questo caso l’icona di una fontanella che può essere grande, piccola, blu, rossa ecc. Ebbene, il concetto principale da tenere sempre a mente per capire cos’è OSM è che i dati e la loro rappresentazione grafica sono sempre separati. Che cosa comporta questo? Questa separazione permette di poter prendere esattamente gli stessi identici dati ma selezionarli e rappresentarli in modi diversi e, trattandosi di un database liberamente accessibile, ciò coinvolge innumerevoli siti ed App.
A sinistra i dati puri e a destra uno dei tanti possibili modi di rappresentarli
Facciamo l’esempio di due App o due siti di navigazione altamente specializzati: uno per vigili del fuoco ed uno per persone che si muovono in sedia a rotelle (come Wheelmap). Entrambe possono usufruire del database OSM ma la prima evidenzierà gli idranti, i sentieri, le altezze dei rilievi, le centraline elettriche, mentre la seconda evidenzierà marciapiedi, scalini, ostacoli e così via. Certi elementi presenti su una non verranno nemmeno mostrati nella seconda ed allo stesso modo certi elementi comuni possono esser rappresentati con diversa enfasi: dei gradini invalicabili per chi è in carrozzina potrebbero essere evidenziati con un grosso bollino rosso nella mappa pensata per gli spostamenti in sedia a rotelle ma senza particolare enfasi nella mappa per i vigili del fuoco che invece potrebbe segnalare con un colore diverso viottoli e stradine in cui non è possibile passare con i mezzi in dotazione. In sostanza, grazie al database OSM è possibile realizzare un numero infinito di mappe diversissime ed altamente personalizzate in base alle diverse esigenze ma i dati di tutte queste sarebbero sempre coerenti tra loro: non sarà mai possibile, consultando due mappe aggiornate e basate su OSM, che in una venga mostrata una nuova rotonda stradale appena creata e nell’altra no.
La stessa città vista nelle quattro visualizzazioni offerte da openstreetmap.org. Ognuna evidenzia i vari elementi in modo diverso e riporta informazioni assenti nelle altre
Le maggiori mappe digitali offrono al loro interno la possibilità di essere visualizzate in tre, quattro modalità diverse (anche su openstreetmap.org è possibile visualizzare la mappa in quattro modalità: standard, ciclabile, trasporti ed umanitaria) ma il database OSM permette di fare molto di più e realizzare un numero sconfinato di progetti impensabili per qualsiasi altra mappa esistente. Qualsiasi sito o App che utilizzi mappe commerciali come quelle di Google o di Apple mostrerà sempre e solo quella mappa lì, con quelle due-tre modalità grafiche che permette, coi suoi colori ed il logo sempre in evidenza.
Al contrario, poiché il database di OSM è scollegato dalla grafica usata, le mappe che ne utilizzano i dati hanno una grandissima varietà di aspetti ed è assai probabile che molte persone abbiano usato più volte mappe OSM senza nemmeno mai rendersene conto (in diversi casi si viene a sapere che la mappa è basata sul database OSM solo se si entra nelle preferenze).
Vorresti andare a piedi da Messina a Copenhagen? Waymarkedtrails usa i dati OSM per rendere maggiormente fruibili i percorsi che fanno per te! Nella mappa è mostrato solo l’indispensabile per orientarsi durante i tragitti.
Un ulteriore esempio per far comprender il meccanismo può esser questo: un’associazione interessata a promuovere escursioni di tipo storico può facilmente mettere sul proprio sito una mappa basata su OSM scegliendo di dargli un colore in scala di grigi, mostrare le linee isoipse (quelle che fan capire l’altitudine dei rilievi), far visualizzare i terreni ed i centri abitati rimuovendo le strade asfaltate, mostrare tutti gli edifici di carattere storico con un colore giallo ed i siti archeologici con un colore rosso. Sarebbe una mappa decisamente particolare che per esser realizzata da zero impiegherebbe un certo dispendio di energie ma OSM permette di realizzarla con relativa semplicità: basta selezionare il tipo di dati che interessano e poi decidere come mostrarli.
TheWeatherChannel usa mappe realizzate da MapBox basate sui dati OSM
Ma non finisce qui! Diversi enti ed aziende che realizzano autonomamente mappe proprie, spesso utilizzano parte dei dati di OSM. Le mappe di Apple, ad esempio, si avvalgono di molti dati OSM. Esri, e Mapbox, un importante fornitore di tecnologie cartografiche ed un’azienda che realizza mappe personalizzate, sono donatori OSM che ne utilizzano i dati ed anche per le proprie mappe.
NON C’E’ UNA “MAPPA OSM UFFICIALE”
Poiché solitamente v’è l’abitudine di considerare i dati e la loro rappresentazione come un tutt’uno, anche nel caso delle mappe vien spontaneo considerare il suo aspetto visivo come l’informazione in sè. Di conseguenza un errore comune in cui si può cadere è quello di ritenere che l’aspetto grafico delle mappe presenti su openstreetmap.org siano “LA mappa di OSM” Ma anche la mappa su openstreetmap.org, pur essendo realizzata da OSM stesso, non mostra tutte le informazioni geografiche del suo stesso database (come già detto, una mappa che mostrasse tutto-tutto-tutto sarebbe inguardabile) e pure i colori, le icone e i font che OSM ha scelto di mostrare su openstreetmap.org non sono un qualcosa di “fisso” (dati e rappresentazione sono due cose distinte).
Le diverse App Android che usano mappe basate sul database OSM. Molte di queste usano grafica, colori e icone proprie e diverse mostrano informazioni assenti nelle mappe visibili su openstreetmap.org
Su openstreetmap.org é stato deciso di rappresentare gli edifici con un colore grigio-marroncino, di rendere molto evidenti i binari ferroviari e le strade hanno colori diversi a seconda della tipologia. Ma se si osserva lo stesso territorio dall’App Maps.me, che utilizza a sua volta lo stesso database OSM, la grafica ed i colori son talmente diversi da farci credere che si tratti di tutta un’altra mappa: i binari ferroviari manco si vedono, le aree verdi sono molto marcate,le strade son tutte bianche ad eccezione delle Autostrade, gli edifici appaiono leggermente in 3D. I dati delle due mappe sono gli stessi ma Maps.me ha semplicemente scelto di usare quegli stessi dati in modo diverso, rappresentarli con un’altra grafica e usare informazioni che OSM ha scelto di non mostrare su openstreetmap.org (l’altezza degli edifici). Non c’è nulla di strano nel fatto che vi siano siti ed App che mostrano cose che sulla mappa openstreetmap.org non appaiono e può benissimo essere che si consideri migliore la mappa basata su OSM presente sul sito taldeitali perchè i quattro tipi di mappe visualizzabili su openstreetmap.org non sono “le mappe ufficiali di OSM” ma solo quattro delle migliaia di modi possibili di usare il database OSM. Siamo di fronte ad un concetto ben noto nel mondo del software libero a cui però il software commerciale ha disabituato: mastodon.social, l’Istanza Mastodon creata dall’inventore di Mastodon stesso, non è “l’Istanza ufficiale”; matrix.org non è l’istanza ufficiale di Matrix, non esiste una distribuzione Linux ufficiale e le quattro mappe di openstreetmao.org non sono le mappe ufficiali di OpenStreetMap.
UN GRANDE, RICCHISSIMO DATABASE GEOGRAFICO
A questo punto abbiamo diversi elementi per iniziare a comprendere meglio la ricchezza di OSM: ogni persona, ente o associazione che ha interesse ad avere delle mappe precise, tarate apposta per le proprie esigenze, coerenti con informazioni geografiche di diversa natura ed arricchite da osservazioni di migliaia di altri utenti può trarne vantaggio collaborando al database di OSM aggiungendovi i dati di proprio interesse. Il tutto viene integrato nel database OSM classificando i vari elementi per tipologia e secondo tutta una serie di criteri, andando così a formare diversi livelli gestibili autonomamente. E’ il principio seguito dai GIS (Geographic Information system), sigla con cui si identificano i principali servizi di mappatura digitale.
Manhattan su Google Maps
Manhattan sulla mappa standard di openstreetmaps.org. Appare immediatamente evidente la differenza in termini di ricchezza di informazioni e precisione
Qui Manhattan su Maps.me (App che usa i dati OSM). Maps.me è interessante perché sfrutta la qualità dei dati OSM ma la restituisce con la leggerezza visiva di Google Maps
All’interno del database si può segnalare veramente di tutto: le piazzole per i camper, i distributori pubblici di sacchetti per cani, sentieri non tracciati, WiFi pubblici, cancelli, inferriate, vicoli strettissimi che solitamente non vengono segnalati, i nomi locali delle campagne, tombini, capitelli, muretti diroccati, ruderi, sentieri abbandonati, gabinetti pubblici e mille altre cose ancora. Il tutto senza doversi preoccupare del fatto che tale informazione possa interessare solo a poche persone o che possa appesantire la mappa. Giusto per dare un’idea, qui e qui è possibile vedere alcune statistiche aggiornate sulla quantità di dati che contiene, qui e qui informazioni sull’hardware usato.
Una zona in Vietnam di cui OSM ne conosce solamente la rete stradale ed i fiumi principali.
Ci sono associazioni che inseriscono in OSM la posizione dei singoli alberi nei parchi pubblici, ciclisti che segnalano ogni singola fontanella o sbarra che impedisce il passaggio, c’è chi segnala i luoghi in cui si posizionano i banchetti di cibo da strada o i cantieri apparsi all’improvviso e così via. Il database di conseguenza accumula sempre più dati la cui ricchezza, va però notato, come per tutte le mappe online è distribuita a macchia di leopardo: se le zone più note, frequentate e di maggior interesse possono avere un grado di precisione elevatissimo ce ne sono altre che invece si limitano a mostrare giusto le strade e poco più.
UN ECOSISTEMA
Il database di OSM, essendo liberamente accessibile, è quindi il perno di tutto un ecosistema di App, siti e strumenti diversissimi che collaborano alla sua diffusione ed in alcuni casi anche al suo miglioramento: certe App, ad esempio, permettono a qualsiasi utente anche privo di esperienza di fornire segnalazioni minute come la presenza di un cantiere, o la rimozione di una panchina e così via. Una di queste, molto carina, che si chiama StreetComplete, gestisce questo processo con una forma di gamification sfruttata per una volta in modo positivo: una volta avviata mostra all’utente tutti gli elementi nelle sue vicinanze riguardo ai quali mancano alcuni dati, chiedendogli di completarli con semplici domande: come si chiama questo ristorante? Quanti piani ha questa casa? E così via… Ci sono anche siti ed App indipendenti che offrono servizi basati su mappe generate dal database OSM.
Mapillary offre un servizio simile a quello di GoogleStreetView. Nell’immagine si possono veder evidenziate in verde le strade già coperte
Una di queste, Mapillary, sta creando un database fotografico simile a quello di Google Street View ma prodotto dai singoli utenti che riprendono le strade coi propri smartphone. Queste fotografie non vanno a far parte del database OSM ma vengono tuttavia rilasciate con licenza Creative Commons CC-BY-SA, dando così la possibilità a chiunque di farne libero uso. I progetti autonomi sviluppati attorno ad OSM sono moltissimi: diverse mappe metereologiche e sulla pandemia Covid sono state fatte con le mappe OSM, le usano i dispositivi Garmin, pure le mappe di Apple son state realizzate attingendo al database OSM.
CentralineDalBasso riporta i dati sulla qualità dell’aria su mappe OSM
OSM è usato pure da numerose associazioni umanitarie per vari progetti e iniziative, tanto che esiste pure un team specializzato (HOT – Humanitarian OpenStreetMap Team) che coinvolge, da solo, oltre 170 mila partecipanti.
Healthsites usa il database OSM per tracciare una mappa di tutti gli ospedali, ambulatori e centri di cura.
…i progetti sono tantissimi e questi sono solo una selezione fatta al volo!
Su https://osm-analytics.org/ vengono visualizzate le informazioni immesse dall’ Humanitarian OpenStreetMap Team. In questo caso gli edifici di due villaggi del Mali, del tutto assenti nelle mappe digitali commerciali
LA GESTIONE DEL DATABASE
Come facilmente intuibile il database OSM, ricevendo aggiornamenti ogni minuto, non sta mai fermo. Ciononostante se visualizzi la mappa di una App o un sito basato su OSM non accadono situazioni tipo “Ops! E’comparsa una panchina all’improvviso!” e questo, giustamente, per diverse ragioni. Quando viene inserito un nuovo dato il database ha bisogno di qualche tempo per elaborarlo e verificare che sia una modifica coerente e non una castroneria tipo “Una montagna di 400 metri comparsa all’improvviso davanti al Duomo di Milano”. Dopodichè vengono fatte delle verifiche da parte dei volontari che controllano la sensatezza della modifica ecc. A seconda del tipo di modifica e della zona interessata questo processo può esser più o meno lungo: se si inserisce un “cancello con sbarra” su un sentiero di campagna in una zona poco frequentata questo verrà elaborato molto velocemente, ma se si correggesse ad esempio il tracciato di una strada stadale di grande percorrenza presso una località importante, la verifica ed eventuale discussione sulla correttezza di questa modifica potrebbe durare anche qualche giorno. In ogni caso, una volta accolta la modifica, il primo luogo in cui questa potrebbe esser visibile è ovviamente la mappa di openstreetmap.org (sempre a patto che sia un tipo di dato che tale mappa mostra). Dopodichè vengono gli altri siti ed App. Questi però non pescano subito i dati dal database principale ma hanno metodi e tempi molto diversi fra loro. Alcuni difatti utilizzano dei propri server in cui copiano il database OSM a cadenza periodica (ad esempio settimanale, mensile, trimestrale o come più gli va).
OsmAnd permette di scaricare offline le mappe OSM più aggiornate. Molte App commerciali invece tendono ad essere più lente nel recepire gli ultimi aggiornamenti
Questo gli permette di essere operativi ed avere mappe funzionanti anche nel caso in cui il server di OSM avesse qualche problema. Quando effettuano questa copia sui propri server in realtà non copiano davvero tutto ma solo la porzione di dati che gli interessa. Per esempio, una App per ciclisti britannici copierà solo i dati relativi alla Gran Bretagna che effettivamente usa. Acquisirà dunque gli aggiornamenti sui negozi di biciclette e sulle nuove piste ciclabili ma snobberà quelli su idranti, centraline elettriche, uffici postali, autovelox ed altre cose che tanto, nell’App, non segnala. Allo stesso modo questi siti ed App spesso evitano di copiare le modifiche più recenti seguendo il principio che i dati troppo “freschi” son stati visualizzati e verificati meno rispetto a quelli presenti da più tempo. Il risultato è che se oggi viene inserita una certa modifica, le App che si appoggiano direttamente al server di OSM la riceveranno istantaneamente mentre per le App che effettuano copie periodiche dei dati sui propri server potrebbe volerci addirittura qualche mese. Anche qui è una questione di scelte personali: meglio avere i dati più aggiornati col rischio di qualche incorrettezza o meglio dati meno aggiornati ma più certi?
MAPPE OFFLINE E SICUREZZA
Quando si consultano le mappe digitali di Google ed Apple, le rispettive App dialogano costantemente col server per comunicare istantaneamente la tua posizione e fornendoti la versione più aggiornata delle loro mappe. Pur esistendo la possibilità di salvare sul telefono alcune porzioni di mappa questo meccanismo è inevitabile: non si può usare le App di mappe commerciali se non si comunica la propria posizione e senza dialogare costantemente col server. Alcune App basate su OSM (non tutte) hanno invece un approccio diverso: al loro interno hanno solo una mappa-base del pianeta e lasciano all’utente la possibilità di scaricare sullo smartphone la porzione di mondo di cui vogliono avere la mappa dettagliata.
Alcune App “conoscono” solo le porzioni di territorio che hai scaricato sullo smartphone
In alcuni casi questo processo è manuale e bisogna selezionare la mappa del paese, regione o città che interessa da una lista, mentre in altri casi quest’operazione è semi-automatica (se zoommi sull’Abruzzo parte il download della mappa dell’Abruzzo). In altri casi ancora v’è un sistema misto (le mappe visualizzate sono quelle del server a meno che non le scarichi). In alcune App, ad esempio, si può scaricare una mappa generale dell’Italia che contiene solamente le strade principali e poi scaricarsi la mappa dettagliata di singole regioni o città che interessano. Ad esempio è possibile salvarsi offline la mappa delle strade dell’intera Italia, la mappa dettagliata della Sicilia e quella dettagliata di Roma. Su queste App gli aggiornamenti delle mappe scaricate oggline funzionano allo stesso modo: semi-automatico per alcune, manuale per altre e misto per altre ancora. Poter scaricare le mappe sul proprio dispositivo porta co sè diversi vantaggi, i primi dei quali sono l’essere accessibili anche se non c’è campo e non consumare costantemente banda per ri-scaricare sempre e solo le stesse strade. Poichè lo spazio su smartphone è quello che è non si avrà mai l’intero database OSM salvato, ma le App basate su mappe offline solitamente sanno gestire la cosa a dovere e se per il tuo viaggio hai necessità di salvarti la mappa dell’intera Romania ma non hai più spazio è del tutto indolore liberarne un po cancellando quelle di territori che non ti serve consultare al momento. Tra i vantaggi delle mappe offline v’è anche il fatto che sono solitamente più scattanti e possono essere consultate, navigate, si possono fare ricerche su di essa senza trasmettere mai a nessuno la propria posizione o informazioni su cosa stai cercando (se cerchi “Ascoli” su Google Maps la richiesta viene inviata ai server di Google che innanzitutto registrano che hai “cercato Ascoli alle 17.34” e solo dopo di ciò inviano la posizione di Ascoli al tuo smartphone). Con questo tipo di App invece si possono pure registrare i propri tracciati GPS nella certezza che questi saranno presenti solo e soltanto sul proprio telefono.
La preferenza per soluzioni offline però porta con sè anche qualche piccolo inghippo. Il primo è che gli aggiornamenti delle mappe scaricabili offline non sono sempre automatiche o ben segnalate ed ovviamente è un qualcosa a cui bisogna prestare una certa attenzione.
Il secondo riguarda il tempo che l’App può impiegare a calcolare i percorsi. Se si chiede a Google Maps di calcolare il percorso da Milano a Napoli, fondamentalmente l’App manda la richiesta ai server di Google i quali innanzitutto registrano che hai “cercato il percorso da Milano a Napoli alle 18.42”, poi effettuano il calcolo e restituiscono all’App il percorso consigliato. Il tutto in pochissimi secondi. Al contrario se si usa una App indipendente che fa fare questo calcolo allo smartphone senza comunicare nulla al server, da un lato non si regalano i propri dati in giro ma dall’altro questo ci metterà molto più tempo (il processore di uno smartphone è niente rispetto a quello di un grosso server). Su certe App, ad esempio, calcolare un percorso di 400Km può impiegare anche tre minuti. Anche qui è una questione di scelte: preferire una App scattante ma che comunica le proprie ricerche ad un server cui dobbiamo fidarci o una più solida ma lenta? Bisogna però considerare che una App che sa fare questi calcoli in proprio sarà autonoma anche nel bel mezzo di una grotta in fondo a un burrone in una valle sperduta in cui non c’è campo.
Il terzo inghippo riguarda la funzione “cerca” delle App, ma lo vedremo meglio più avanti.
IL GPS DI PER SE’ NON CI “TRACCIA”
Una domanda comune a questo punto riguarda il sistema GPS a causa di una certa confusione su come funziona questo sistema e vale dunque la pena spendere due parole per spiegare mooooolto grossolanamente come funziona. Il sistema GPS si basa su una trentina di satelliti geostazionari che circondano l’intero globo da una distanza di circa ventimila chilometri dalla superficie terrestre. Per geostazionario si intende un satellite che “staziona”, ossia che sta sempre fisso sopra lo stesso punto della Terra: se un satellite GPS fosse stato posizionato, per esempio, esattamente sopra la verticale di casa tua, questo resterebbe sempre lì, di notte e di giorno. Questi satelliti si trovano ad un’altezza tale che da ogni punto del globo sia sempre possibile “vederne” almeno tre, per esempio, osservando il cielo dall’Italia potresti vedere quello sopra casa tua, uno che sta sopra la casa di un tizio di Mosca ed uno che sta sopra un cinema in Islanda. Questi satelliti trasmettono costantemente dei segnali radio contenenti alcuni dati, i più importanti dei quali sono la sua posizione e l’ora esatta, con una precisione al microsecondo.
Laura, Mario e Andrea all’opera
Quando ti perdi nel bel mezzo della campagna ed apri una App per capire cove cavolo sei, questa riceve i segnali radio trasmessi dai satelliti esattamente come la radiolina da quattro soldi che becca sempre Radio Maria. L’App, quindi, riceve una roba tipo questa:
SATELLITE LAURA “Ciao! Sono Laura! La mia posizione esatta è XYZ e sono le ore 16:04:07…e 6 millisecondi“
SATELLITE MARIO “Ciao! Sono Mario! La mia posizione esatta è XYZ e sono le ore 16:04:07…e 23 millisecondi“
SATELLITE ANDREA “Ciao! Sono Andrea! La mia posizione esatta è XYZ e sono le ore 16:04:07…e 49 millisecondi“
L’App riceve tutti questi segnali contemporaneamente ma… il suo orologio interno indica le 16:04:07… e 52 millisecondi! Questa differenze di orario dipendono dal fatto che il segnale inviato da satelliti tanto lontani ci mette un po ad arrivare allo stesso punto. Non serve molto per capire che più il satellite è lontano e più ci mette. A questo punto l’App calcola molto velocemente la differenza microscopica tra gli orari e capisce di essere molto vicino ad Andrea, un po meno vicino da Mario e molto lontano da Laura. Di conseguenza, conoscendo le loro posizioni esatte (che han trasmesso) e la velocità di trasmissione delle onde radio, riesce a calcolare le proprie coordinate e mostrarle sulla mappa. Si tratta di un processo chiamato triangolazione.
Per chi volesse saperne di più, online ci sono diverse mappe live come questa che mostrano la posizione in orbita di migliaia di satelliti artificiali di tutti i tipi. Su F-Droid è pure possibile scaricare GPStest, una curiosa App che elenca tutti i satelliti che il tuo smartphone sta rilevando in questo momento (e si, quello sopra casa tua lo becca SEMPRE).
Capito il meccanismo appare chiaro che un ricevitore GPS, in questo caso il tuo smartphone, per funzionare non ha bisogno di trasmettere niente a nessuno riguardo alla tua posizione! Quando si parla di localizzare qualcuno tramite il suo GPS non si intende certo che il suo smartphone comunichi la propria posizione ai satelliti (A Laura, Mario ed Andrea non gliene frega una cippa di dove tu sia) ma significa che lo smartphone sta inviando -via Internet- quelle coordinate che ha calcolato grazie ai segnali che ha ricevuto dai satelliti GPS. I navigatori da auto stand-alone tipo i TomTom o i Garmin da escursionismo difatti sono anch’essi ricevitori GPS eppure non si è mai sentito dire che si possa “rilevare la posizione” di un TomTom o di un Garmin. Questo può essere verificato facilmente anche provando ad utilizzare una App che funziona con mappe offline e verificare la propria posizione GPS con la modalità aereo attivata.
MANCANZE e “MEH”
A parte le valutazioni su pregi e difetti delle App che usano mappe e calcoli di percorso offline (che non sono dei difetti ma osservazioni su pro e contro di certe caratteristiche), al’ecosistema stesso di OSM è caratterizzato da alcune mancanze che fanno particolarmente sentire, soprattutto nel fare un paragone con gli strumenti commerciali.
I MODULI DI RICERCA La prima mancanza che si riscontra quella di un ricerca interno efficiente. openstreetmap.org usa un certo software di ricerca e le App basate su OSM ne usano degli altri ma tuttavia il problema è abbastanza comune: è estremamente facile NON trovare quel che si cerca. In linea generale si può dire che più l’App è specializzata (per esempio una App dedicata solo agli spostamenti in automobili) e migliori sono i risultati, ma non è una regola che vale sempre. Giusto per fare due esempi, L’App Maps.me, pensata principalmente per viaggi turistici, ha un modulo di ricerca abbastanza intuitivo e veloce mentre al contrario, OsmAnd, che è una eccezionale App multifuzione opensource, ha un modulo di ricerca che necessita un po di pratica per esser appreso. In nessun caso però si arriva all’immediatezza del modulo di ricerca di Google Maps. Le capacità predittive di Google nel capire che se digiti “Parigi” è più probabile tu stia cercando la capitale francese che non una oscura “via Parigi” di una città vicina, da questo punto di vista è decisamente più efficiente rispetto alle altre soluzioni disponibili.
openstreetmap.org elabora in pochi secondi tragitti intercontinentali, ma se sbagli e scrivi Vladivostock col “ck” finale, è convinto tu voglia visitare uno stagno a qualche km. da Parigi
Le varie App rispondono a questa mancanza con diverse strategie: quelle specialistiche riescono a starci dentro perché gestiscono una quantità di informazioni minori e sono usate per scopi mirati; quelle più complesse, come OsmAnd, dovendo gestire una quantità di informazioni elevata utilizzano dei moduli di ricerca in cui l’utente deve compilare diversi passaggi. Per fare un esempio: su Google Maps, digitando anche malamente “via cavur roma”, il modulo di ricerca comprende comunque che si sta cercando Via Cavour a Roma e lo propone come prima soluzione. Per trovare la stessa via su OsmAnd è necessario:
saltare il modulo di ricerca base
selezionare “indirizzo”
selezionare “prima specifica la città”
digitando correttamente “Roma” le prime soluzioni proposte sono le località più vicine alla propria posizione che contengono “Roma” nel nome (Campagnano di Roma, Casa Roma, Chiarano Roma). La città di Roma, nel mio caso, è in quarta posizione
tornare indietro su “indirizzo”
digitare correttamente “via Cavour”
Dopo un po che ci si fa l’abitudine a fare tutti questi passaggi ci si mette un nonnulla ma resta il fatto che non c’è paragone con la semplicità del modulo di ricerca di Google.
In altre App e siti le ricerche funzionano benissimo a patto che nomi ed indirizzi siano indicati esattamente come vogliono loro (p.es. prima il nome della via, poi una virgola ed invine il nome della città. O il contrario). Insomma: effettuare le ricerche sulle proprie App non è proprio immediato ed è un campo che necessita certamente di miglioramenti.
A questa difficoltà va a sommarsi nuovamente la questione delle mappe offline: se sul tuo smartphone hai scaricato solo la mappa d’Italia e cerchi una via di Londra, l’App magari conoscerà Londra ma non troverà la via se prima non ne scarichi la mappa. Pare scontato, ma se si ha l’abitudine di usare le mappe di Google può non essere così immediato. Tutto ciò può risultare anche abbastanza antipatico perché se si dovesse ad esempio fare una ricerca sulla località chiamata Fauske senza sapere se sta in Svezia, Norvegia, Finlandia o Islanda non si potrebbe ottenere quest’informazione dall’App di mappe, ma bisognerebbe cercarsela sul web e solo dopo aver scoperto che sta in Norvegia si potrà tornare sull’App e scaricare la mappa corretta in modo che l’App stessa la possa trovare.
NIENTE TRAFFICO La seconda mancanza riguarda le indicazioni del traffico live. Semplicemente non ci sono, ne su openstreetmap.org nè sulle App per OSM. Aggiungere questo tipo di dati non è tecnicamente difficile ma l’ostacolo principale è che le informazioni sul traffico perlopiù devono essere acquistate, non sono di libero accesso ed in alcuni casi vengono ottenute dalle big tech anche carpendo dati dalla posizione degli smartphone degli utenti. Insomma: non se ne fa niente.
3D La terza ed ultima mancanza è quella di una mappa in rilievo paragonabile a quella di Google Earth. Il database OSM contiene i dati altimetrici di terreni e rilievi così come le altezze di numerosi edifici, ma solo alcune App proprietarie, al momento, li sfruttano in modo utile. Diversi sviluppatori stan portando avanti progetti collaterali ad OSM per renderne le mappe in 3D e l’argomento è “caldo” ma attualmente non v’è ancora nulla di utilizzabile da semplici utenti.
Uno dei tanti progetti intesi a dare tridimensionalità alle mappe OSM
“MEH” Non proprio un punto debole ma piuttosto un “meh” da rilevare è che le informazioni sugli esercizi commerciali sono tendenzialmente più complete sulle mappe di Google. Non è solitamente un problema ma in alcuni casi può risultar antipatico dover uscire da OSM, fare una ricerca altrove e poi rientrare in OSM. Ovviamente non c’è nulla che impedisca di aggiornare i dati di tutte le attività commerciali su OSM ma poichè il mercato è Google-oriented è lì che i mercanti vanno a parare.
Un secondo, debolissimo “meh” è che in alcuni casi sarebbe apprezzabile veder convergere su openstreetmap.org alcune funzioni offerte dai progetti che gli ruotano attorno. Un esempio tra questi è Mapillary, il servizio simile a Street View. Se si naviga una mappa su openstreetmap.org e si volessero vedere le immagini a livello strada di una certa zona bisogna andare su mapillary.com, tornare nuovamente sulla stessa zona e lì si potrebbero vedere queste immagini. Questa convergenza tuttavia viene ottenuta da alcune App. Sulla già citata OsmAnd, per esempio, basta un comando per visualizzare le foto di Mapillary.
VOGLIO CONTRIBUIRE!
Se a questo punto, ci si sentisse dentro un irrefrenabile impulso di contribuire ad OSM mappando a più non posso è sufficiente iscriversi su openstreetmap.org ed iniziare a frequentarne i forum, leggere la wiki, prendere dimestichezza col suo funzionamento e chiedere consigli alla sua community.
Un editor di OSM
Questo articolo è giusto una panoramica su cos’è OpenStreetMap e sulle sue potenzialità ma per quanto riguarda il lavoro che c’è dietro è decisamente meglio chiedere direttamente a chi si occupa attivamente della sua gestione. L’unico consiglio che si può dare qui, semmai, è di farci un po un giro prima di modificare la mappa di Milano e indicare che è apparsa una montagna davanti al Duomo, ecco.
LE APP BASATE SU OSM
E per finire non si poteva che segnalare le App che usano mappe basate sul database OSM. Ce ne sono diverse decine tra cui scegliere ed alcune sono abbastanza particolari e molto specifiche. Essendoci quindi un po di tutto, prima di pigliare App a caso forse è meglio fare una prima breve riflessione sull’utilizzo che se ne vuol fare e delle situazioni in cui ci capita di aver bisogno di una mappa: spostamenti in auto? Viaggi all’estero? Escursionismo? Ciclismo? Deve poter registrare i tracciati GPS, esportarli ecc? Deve poter permettere di segnalare modifiche ad OSM? Che tipo di dati si preferisce visualizzare? Meglio una App che fa di tutto ma complessa o una che fa poche cose ma che sia chiara e semplice? Può valer la pena usare due App per due tipi di utilizzo distinti? In ogni caso, sia per Android che iOS le due App più note sono le già segnalate OsmAnd e Maps.me
OsmAnd è un vero e proprio coltellino svizzero: fa TUTTO! Navigatore vocale per auto, modalità escursionismo, registra i tracciati con le statistiche altimetriche, integra Mapillary, permette di visualizzate le mappe in innumerevoli modi e tantissime altre cose. Tanta ricchezza ovviamente significa alto grado di complessità e di conseguenza richiede un certo “addestramento” per esser usato al meglio, ma una volta fatto proprio diventa uno strumento insostituibile! E’disponibile anche su F-Droid.
Maps.me è pensata per viaggi turistici. E’molto leggera e le mappe che usa hanno una grafica leggera che ricorda quella di Google Maps ed è adatta a chi ha bisogno di un navigatore facile da usare e senza fronzoli. Su F-Droid è presente un suo fork (una “versione modificata”) chiamata semplicemente Maps.
Navit è concepito puramente come navigatore automobilistico e può essere installato su diversi dispositivi.
OsmAnd e Navit sono software completamente liberi ed open source mentre Maps.me, pur essendo open source, è collegato ad una azienda che si occupa di viaggi. La versione su F-Droid chiamapa Maps invece è “pulita”.
Le altre App, come detto, sono diverse decine e ve n’è di tutti i tipi. Questi due link portano a pagine della wiki di OSM in cui vengono descritte una ad una e confrontate fra loro (in inglese):
OsmAnd ed altre App permettono di fare piccole segnalazioni ad OSM, ad esempio per indicare che una certa strada è stata chiusa, ma se si volesse fare qualcosa di più anche da smartphone esiste Vespucci, una App pensata appositamente per i volontari di OSM. E’però consigliabile usarla solo se si ha già un minimo di esperienza nel modificare i dati OSM da desktop.
Chi volesse dare una mano ad aggiornare i dati OSM ma senza dover imparare a modificare le mappe ed aggiornarle può contrinuire usando StreetComplete! Si tratta di un’App carinissima che, una volta avviata, pone delle semplici domande riguardo alla zona in cui ti trovi e su cui OSM ha informazioni incomplete. E’ un modo molto intelligente ed utile di sfruttare alcuni elementi della gamification per realizzare un progetto da cui ne trae vantaggio il mondo intero!
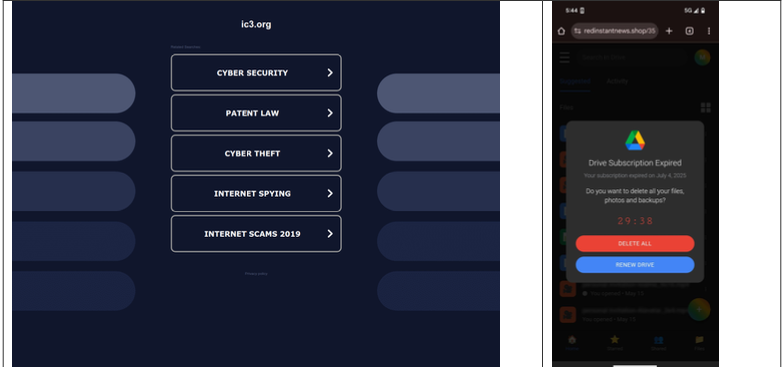
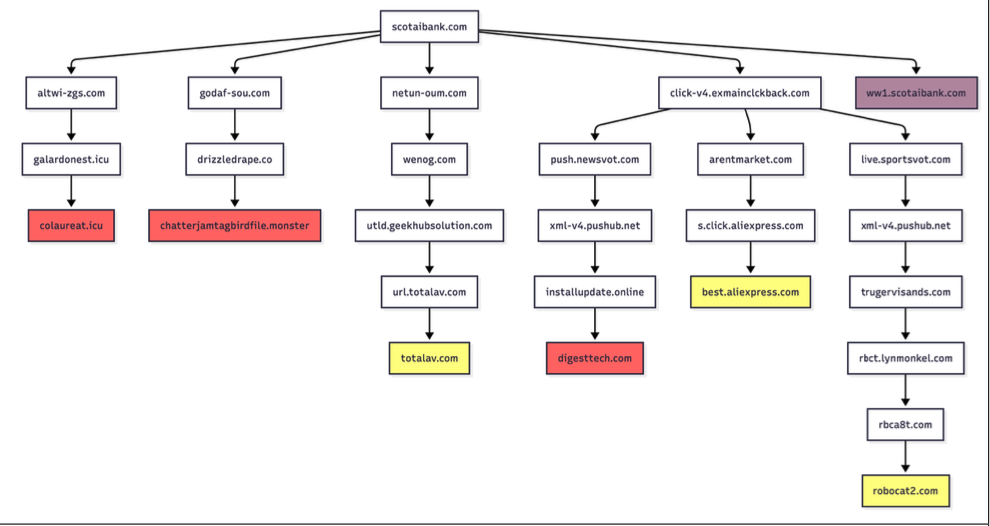






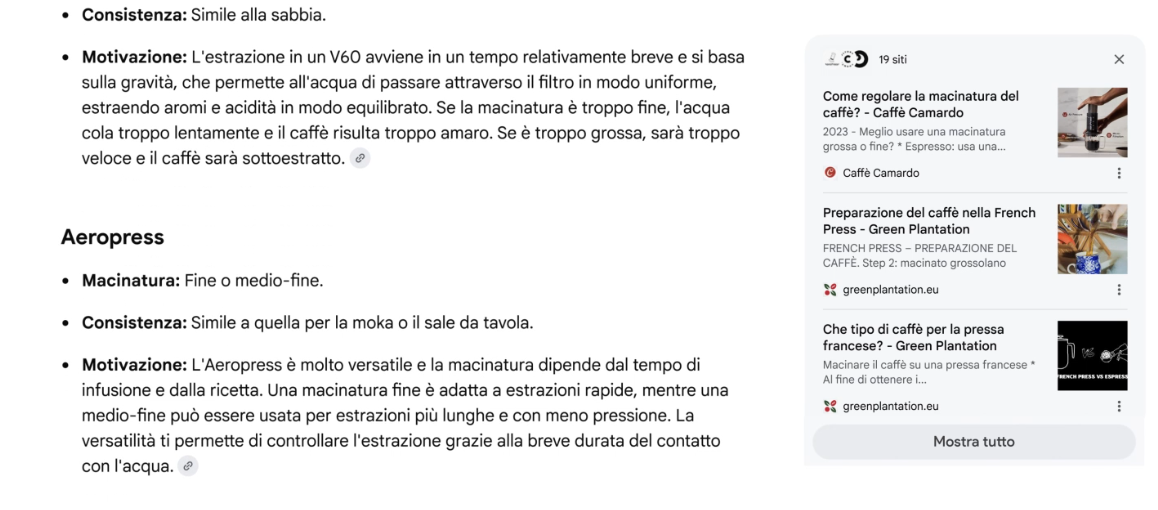



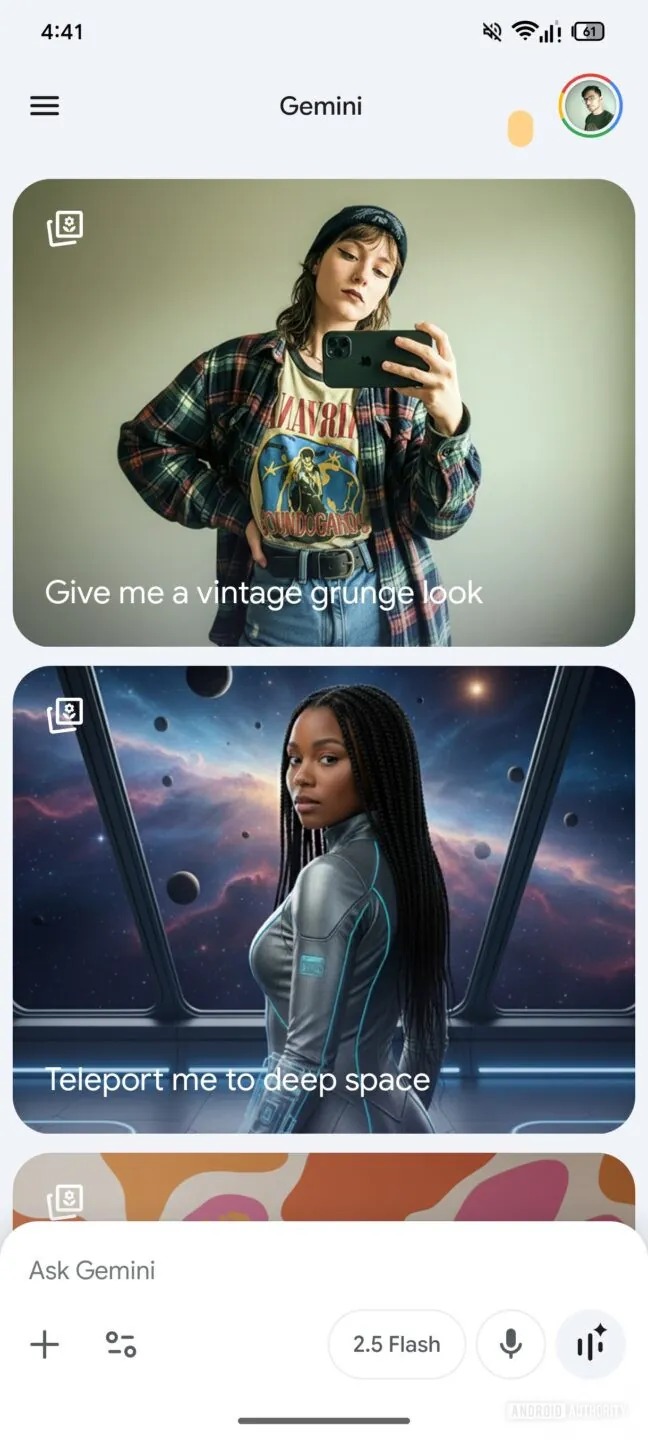

































 Ipoteticamente, una rete distribuita é quasi indistruttibile: in uno scenario in cui tutti i computer del pianeta facessero parte della rete Yacy, anche se la maggior parte di questi fosse improvvisamente tagliata fuori o distrutta da un colossale meteorite, é sufficiente che solo una minima parte resti attiva perché tutto il database comune resti attivo. Progetto interessantissimo dunque, ma che dovrebbe essere reso molto più user-friendly per sperare in una adozione di massa. Chi volesse provare ad installarselo e smanettarci lo trova
Ipoteticamente, una rete distribuita é quasi indistruttibile: in uno scenario in cui tutti i computer del pianeta facessero parte della rete Yacy, anche se la maggior parte di questi fosse improvvisamente tagliata fuori o distrutta da un colossale meteorite, é sufficiente che solo una minima parte resti attiva perché tutto il database comune resti attivo. Progetto interessantissimo dunque, ma che dovrebbe essere reso molto più user-friendly per sperare in una adozione di massa. Chi volesse provare ad installarselo e smanettarci lo trova 

























