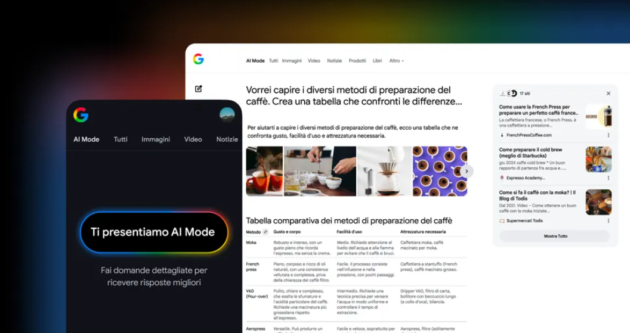
Da oggi AI Mode, la modalità di Ricerca Google basata su intelligenza artificiale, è disponibile in 36 nuove lingue, tra cui l’italiano, e in quasi 50 nuovi Paesi e territori, per un totale di oltre 200 aree coperte in tutto il mondo. L’espansione include gran parte dell’Europa e segna il debutto ufficiale di questa funzione anche in Italia, sia nella pagina dei risultati di ricerca sia nell’app Google per Android e iOS.
AI Mode rappresenta la forma più avanzata di ricerca mai proposta da Google: una modalità progettata per gestire domande complesse, articolate e multidimensionali, grazie a una versione personalizzata dei modelli Gemini ottimizzati per la Ricerca.
Rispetto alla ricerca tradizionale, AI Mode consente di formulare richieste più lunghe e dettagliate, che in passato avrebbero richiesto più interrogazioni separate. Gli utenti che l’hanno provata per primi, spiega Google, tendono a porre query due o tre volte più estese rispetto alla media.
Un esempio pratico? È possibile chiedere:
“Vorrei capire i diversi metodi di preparazione del caffè. Crea una tabella che confronti gusto, facilità d’uso e attrezzatura necessaria.” A questo punto, l’utente può continuare con una seconda domanda, ad esempio: “Qual è la macinatura migliore per ciascun metodo?”
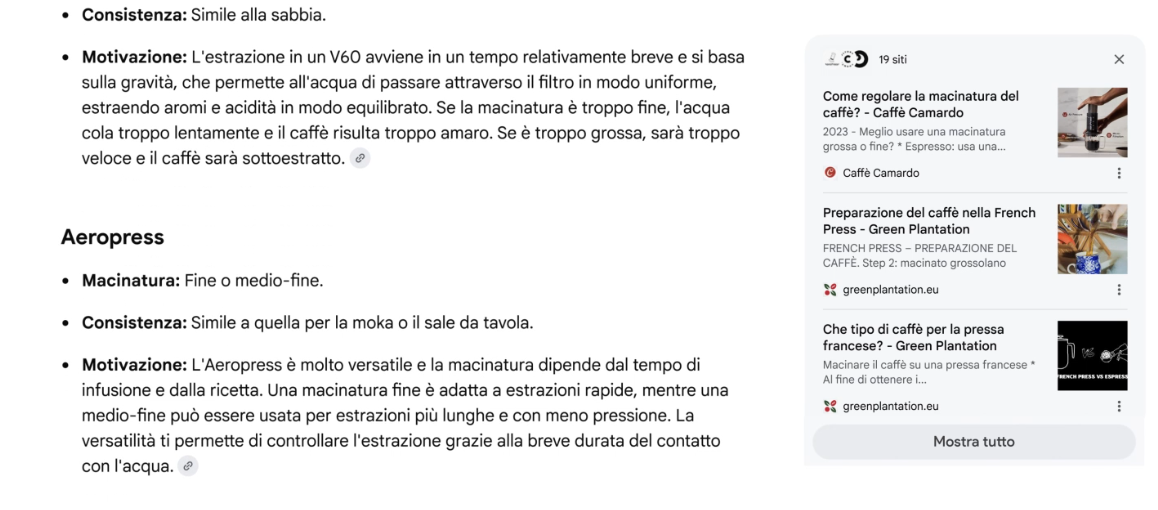
Dietro le quinte, AI Mode sfrutta una tecnologia definita query fan-out, che scompone la domanda in sottotemi ed esegue ricerche parallele per ciascuno. In questo modo, la piattaforma è in grado di esplorare il web più in profondità e proporre contenuti più ricchi, pertinenti e aggiornati.
Un altro aspetto distintivo di AI Mode è la multimodalità: l’utente può porre domande non solo tramite testo, ma anche con la voce o con un’immagine. Basta toccare l’icona del microfono per chiedere qualcosa a voce, oppure scattare o caricare una foto per ottenere informazioni visive contestuali — una funzione utile, ad esempio, per riconoscere oggetti, prodotti o monumenti.
Nonostante la crescente integrazione dell’IA, Google ribadisce che l’obiettivo di AI Mode resta quello di facilitare la scoperta di contenuti provenienti dal web, fornendo sempre link diretti alle fonti.
Secondo l’azienda, strumenti come AI Overview (la panoramica automatica di risultati basata su IA) stanno già mostrando che, dopo aver visualizzato i suggerimenti dell’IA, le persone visitano una varietà più ampia di siti web e trattano i contenuti con maggiore attenzione, trascorrendo più tempo sulle pagine visitate.
AI Mode si basa inoltre sugli stessi sistemi di ranking e qualità usati per la Ricerca classica, ma introduce nuovi approcci per valutare l’affidabilità delle informazioni. Quando il sistema non è sufficientemente sicuro della risposta, vengono mostrati i risultati web tradizionali, garantendo trasparenza e controllo.
WhatsApp continua a espandere e rinnovare le proprie funzionalità per mantenere la piattaforma competitiva nel panorama delle app di messaggistica istantanea. Tradizionalmente, l’app si è sempre basata sul numero di telefono per identificare e collegare gli account, ma questa impostazione potrebbe presto cambiare: nei più recenti aggiornamenti beta, infatti, è comparsa un’opzione per la prenotazione dei nomi utente (username).
L’introduzione di questa funzione avvicinerebbe WhatsApp a concorrenti come Telegram e Signal, che da tempo offrono la possibilità di comunicare senza condividere il proprio numero di telefono, semplicemente tramite un identificatore univoco.
La novità è stata individuata nella versione 2.25.28.12 della beta di WhatsApp per Android, dove tra le impostazioni è comparsa una nuova sezione dedicata proprio alla prenotazione del nome utente. Questo suggerisce che l’azienda stia preparando il terreno per un lancio pubblico della funzione, permettendo agli utenti di scegliere e registrare in anticipo il proprio username.
Questa fase preliminare servirebbe a garantire equità nella distribuzione dei nomi, evitando che gli utenti più rapidi possano accaparrarsi i nomi più popolari o riconoscibili prima dell’attivazione ufficiale. Inoltre, consentirebbe a Meta di testare il sistema su larga scala, verificandone stabilità e sicurezza.
Oltre a rappresentare un’evoluzione tecnica, l’introduzione dei nomi utente ha anche implicazioni importanti in termini di privacy. Attualmente, per contattare qualcuno su WhatsApp è necessario conoscere il suo numero di telefono, il che può essere percepito come un’informazione piuttosto sensibile. Con l’arrivo degli username, invece, sarà possibile interagire con altri utenti senza rivelare il proprio numero personale, aumentando la riservatezza nelle conversazioni, in particolare con nuovi contatti o in contesti pubblici.
Regole per la scelta del nome utente
Secondo le informazioni contenute nella versione beta, WhatsApp ha già stabilito alcune linee guida tecniche per la creazione degli username:
Sono ammessi solo caratteri minuscoli, numeri (0-9), punti e trattini bassi
Spazi o caratteri speciali non sono consentiti
Queste restrizioni mirano a garantire uniformità e compatibilità tra le diverse piattaforme e dispositivi, oltre a prevenire abusi o tentativi di phishing legati all’uso di nomi simili a domini web o marchi noti.
Al momento non è stato comunicato un calendario ufficiale per l’implementazione pubblica della funzione. Tuttavia, la presenza dell’opzione di prenotazione nella beta suggerisce che lo sviluppo sia già in una fase avanzata e che il rollout potrebbe iniziare nei prossimi mesi.
Come di consueto, WhatsApp procederà con un rilascio graduale, così da poter monitorare il comportamento del sistema, correggere eventuali bug e ottimizzare la gestione dei nomi duplicati o delle collisioni di username.
Android 16 è disponibile già da tempo per gli utenti Pixel e, più recentemente, per alcuni dispositivi Samsung, Motorola e Sony. A brevissimo si aggiungerà alla lista anche OnePlus, che ha annunciato ufficialmente la disponibilità di OxygenOS 16 a partire dal 16 ottobre 2025.
La nuova versione del sistema, basata su Android 16, porta con sé il motto “Intelligently Yours”, che sembra alludere all’integrazione sempre più profonda dell’intelligenza artificiale all’interno dell’esperienza utente. Un indizio arriva dalla conferma che Gemini, l’assistente AI di Google, sarà parte integrante della funzione Mind Space. Quest’ultima rappresenta un ambiente personale dove raccogliere appunti, articoli, screenshot e altri contenuti: grazie a Gemini, sarà possibile non solo recuperarli con facilità, ma anche elaborarli in maniera proattiva.
Un esempio mostrato da OnePlus riguarda proprio la pianificazione di un viaggio: un semplice comando a Gemini consente all’assistente di attingere alle informazioni già salvate in Mind Space e trasformarle in un piano organizzato, senza bisogno di richieste puntuali e frammentate.
Al momento, oltre alla data e a questa anticipazione sulle funzionalità AI, non sono stati forniti ulteriori dettagli ufficiali. Sarà quindi necessario attendere il 16 ottobre per capire meglio quali dispositivi riceveranno l’aggiornamento e in quali tempi, con la speranza che il rollout sia rapido e ampio, evitando le lunghe attese che spesso caratterizzano il mondo Android.
Lo sviluppo di One UI 8.5 sta procedendo rapidamente, con i primi firmware trapelati che hanno già svelato diverse novità in arrivo sui dispositivi Galaxy. Dopo la prima build non definitiva, che presentava elementi grafici incompleti e qualche imperfezione, è ora disponibile un nuovo firmware che mostra ulteriori affinamenti dell’interfaccia e diverse migliorie.
La prima versione trapelata di One UI 8.5 mostrava icone non rifinite e dettagli grafici provvisori. Nella nuova build, Samsung ha già corretto alcuni di questi aspetti. Ad esempio, i pulsanti della lista widget nel pannello rapido, che inizialmente risultavano poco curati, ora presentano un aspetto coerente con il resto dell’interfaccia.
Oltre ai ritocchi estetici, il nuovo firmware introduce diversi cambiamenti funzionali e stilistici:
Digital Wellbeing ha ricevuto un piccolo restyling, con pulsanti più grandi che ne semplificano l’utilizzo.
Nella schermata di personalizzazione della lockscreen, toccando l’icona di un’app nei collegamenti rapidi si apre un pop-up con l’intera lista delle app disponibili.
L’app Telefono utilizza ora una barra inferiore composta solo da icone. Nella nuova build questa barra si estende per tutta la larghezza dello schermo, anche se i pulsanti effettivi restano concentrati al centro.
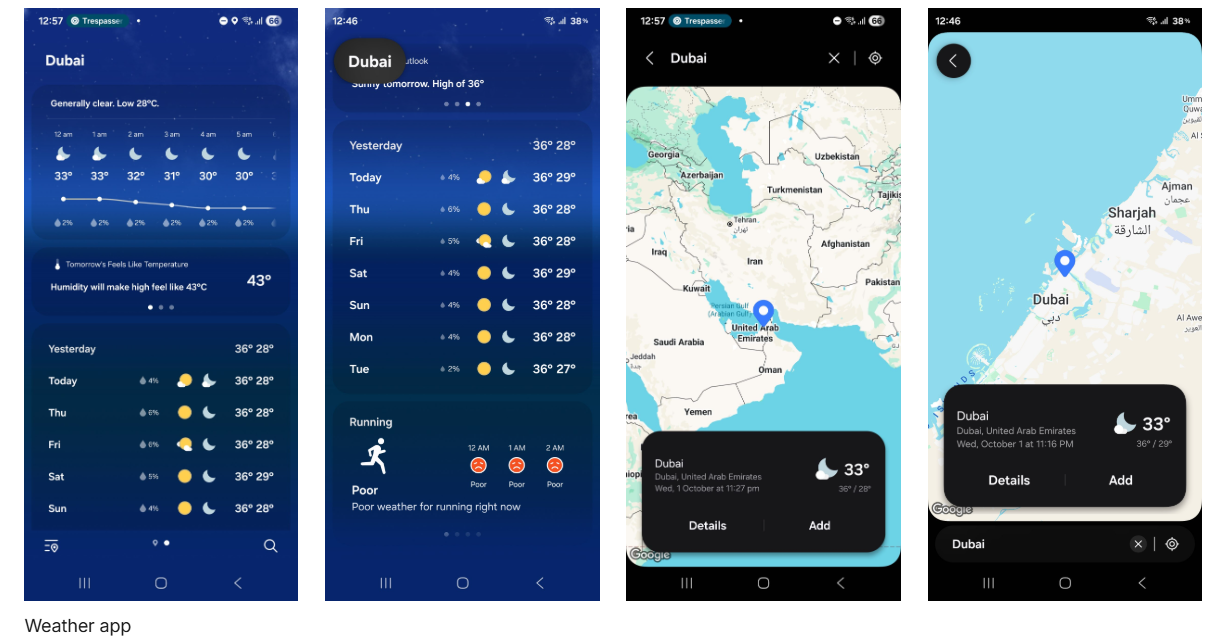
L’app Meteo segue l’approccio di Impostazioni, spostando la barra di ricerca in basso quando si attiva la funzione di ricerca. Inoltre, il nome della località viene messo in evidenza con un riquadro nella parte alta dello schermo.
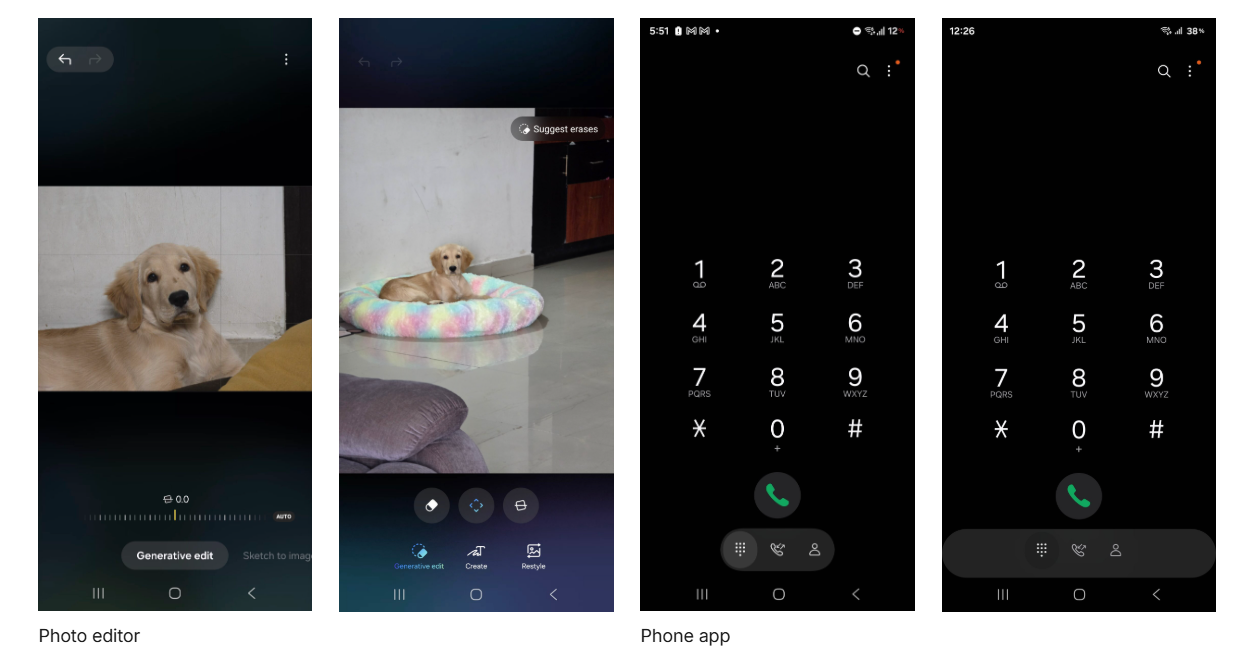
Nel menu di modifica foto con Galaxy AI presente in Galleria, la grafica è stata aggiornata, mentre la barra di navigazione inferiore mostra ora tutte le schede disponibili senza richiedere lo scorrimento laterale.
In app come Meteo, Impostazioni e Galleria compare un effetto gradiente nella parte superiore e inferiore della schermata: un accorgimento che anticipa visivamente l’elemento successivo quando si scorre.
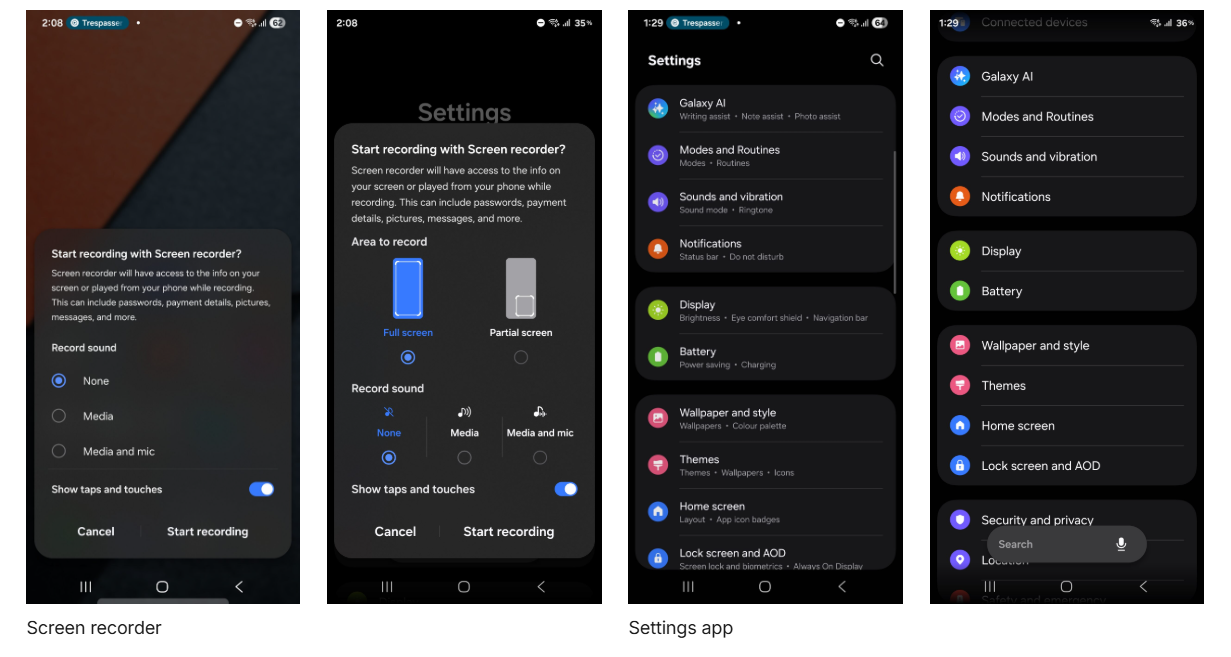
Il menu del registratore dello schermo è stato ridisegnato con pulsanti più grandi e icone dedicate che chiariscono la funzione di ogni opzione.
Va ricordato che One UI 8.5 è ancora in una fase di sviluppo iniziale. Le modifiche viste in questi firmware trapelati rappresentano soltanto una parte delle novità che Samsung introdurrà con la release finale. Come spesso accade, ulteriori cambiamenti potrebbero arrivare nelle prossime build interne, con affinamenti sia grafici che funzionali.
Samsung non ha ancora annunciato una data precisa per il debutto di One UI 8.5, ma è probabile che il rollout inizi in concomitanza con i prossimi top di gamma della serie Galaxy S26, per poi estendersi gradualmente anche ad altri modelli.
Lo sviluppo del prossimo importante aggiornamento Samsung per dispositivi mobili è in pieno svolgimento. Un flusso incontrollato di novità dalle build trapelate di One UI 8.5 ha già rivelato numerose nuove funzionalità che possiamo aspettarci dall’aggiornamento. Il mese scorso, abbiamo visto indizi che Samsung si stesse preparando a modifiche di design ispirate a iOS nell’app Impostazioni, ed oggi scopriamo le modifiche alle icone dell’app.
[ad#ad-celli]
Abbandonando il design piatto che ha caratterizzato One UI per diversi anni, Samsung sta passando ad un aspetto 3D per le icone. Il leaker Ice Universe ha presentato oggi su Weibo delle immagini aggiornate delle icone delle app.
Questa modifica è in linea con i recenti aggiornamenti dell’app Impostazioni, in cui le bolle contenenti le diverse opzioni di menu appaiono leggermente in rilievo. Sebbene le app di sistema abbiano un aspetto notevolmente diverso, sembra che Samsung stia applicando lo stesso effetto anche alle icone di altre app popolari, tra cui YouTube e Google Play Store, nonché a una serie di app di terze parti.
In particolare, questa non è la prima volta che Samsung sperimenta con le icone 3D. Se siete utenti Samsung di lunga data, ricorderete subito allora le versioni successive dell’interfaccia TouchWiz di Samsung.
Come quasi tutti i chatbot basati sull’intelligenza artificiale, Gemini ha coltivato fin dall’inizio un aspetto minimalista. All’apertura dell’app, si presenta una schermata iniziale ordinata e, negli ultimi mesi, Google ha testato piccole modifiche all’interfaccia utente. Tuttavia, secondo le ultime indiscrezioni sembra che Google stia considerando un cambio più radicale del modo in cui gli utenti interagiscono con l’app.
[ad#ad-celli]
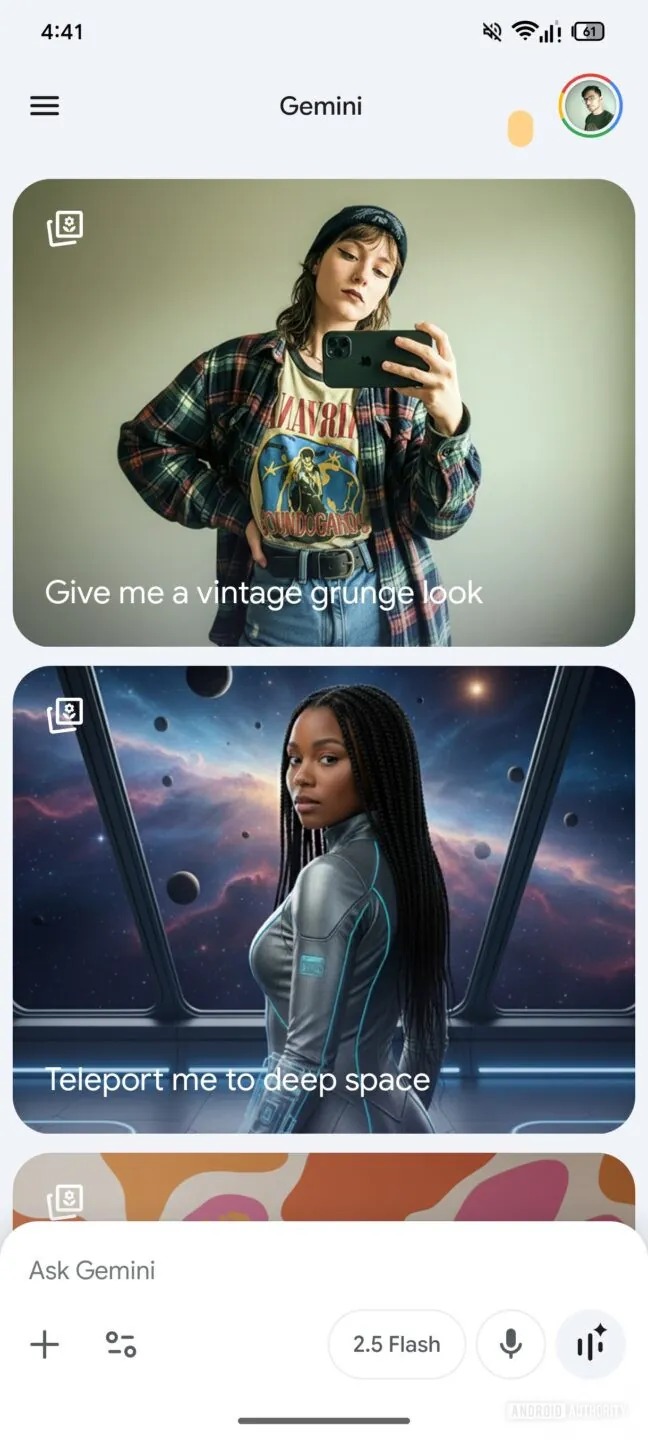
Nella versione 16.38.62.sa.arm64 dell’app Google è stata individuata una schermata iniziale Gemini riprogettata durante i test. Il layout attuale accoglie l’utente con un messaggio di benvenuto e scorciatoie per gli strumenti principali, come “Crea immagine” e “Ricerca approfondita“. Nel nuovo design, questi pulsanti si spostano verso l’alto per far spazio a un feed scorrevole di suggerimenti.
I suggerimenti visualizzati fungono da spunti di conversazione con un solo tocco. Alcuni evidenziano le capacità di Gemini in fatto di immagini, come “Datemi un look vintage”. Altri mettono in risalto abilità diverse, come l’invio di un notiziario quotidiano, un quiz di biologia di base o la programmazione di un piccolo gioco. Ovviamente essendo queste versioni ancora beta e non pensate per il pubblico, non si sa ancora quando e se questa nuova interfaccia farà capolinea su tutti gli smartphone nella versione stabile.
Buongiorno a tutti, come annunciato nei giorni precedenti RRP si rinnova e abbandona le segnalazioni online.
RRP continuerà la sua attività ma sarà incentrata su tematiche più radiotecniche e meno social.
Una rete nata per dare supporto amatoriale in caso di necessità non può appoggiarsi a internet, oggi più che mai sentiamo la necessità di avvicinarci alla classica comunicazione via etere.
Qui di seguito troverete le linee guida per le comunicazioni, potete scaricarle, stamparle e volendo plastificare per renderlo impermeabile.
Ricordiamo inoltre il nostro gruppo per le vostre segnalazioni sul territorio su Telegram all’indirizzo: http://t.me/reteradio
e il nostro gruppo Gestione emergenze all’indirizzo http://t.me/prepper_italia
Unit hacklab Milano si unisce alle voci che si alzano contro la
militarizzazione dell'industria marittima. SeaFuture, nata come mostra
di tecnologie nautiche civili, negli ultimi anni è stata trasformata in
una vetrina per le tecnologie di guerra e di morte.
This article was contributed by Vedrana Vidulin, Head of Responsible AI Unit at Intellias (LinkedIn).
As AI becomes central to smart devices, embedded systems, and edge computing, the ability to run language models locally — without relying on the cloud — is essential. Whether it’s for reducing latency, improving data privacy, or enabling offline functionality, local AI inference opens up new opportunities across industries. LiteLLM offers a practical solution for bringing large language models to resource-constrained devices, bridging the gap between powerful AI tools and the limitations of embedded hardware.
Deploying LiteLLM, an open source LLM gateway, on embedded Linux unlocks the ability to run lightweight AI models in resource-constrained environments. Acting as a flexible proxy server, LiteLLM provides a unified API interface that accepts OpenAI-style requests — allowing you to interact with local or remote models using a consistent developer-friendly format. This guide walks you through everything from installation to performance tuning, helping you build a reliable, lightweight AI system on embedded Linux distribution.
Setup checklist
Before you start, here’s what’s required:
A device running a Linux-based operating system (Debian) with sufficient computational resources to handle LLM operations.
Python 3.7 or higher installed on the device.
Access to the internet for downloading necessary packages and models.
Step-by-Step Installation
Step 1: Install LiteLLM
First, we make sure the device is up to date and ready for installation. Then we install LiteLLM in a clean and safe environment.
Update the package lists to ensure access to the latest software versions:
sudo apt-get update
Check if pip (Python Package Installer) is installed:
pip –version
If not, install it using:
sudo apt-get install python3-pip
It is recommended to use a virtual environment. Check if venv is installed:
dpkg -s python3-venv | grep “Status: install ok installed”
If venv is intalled the output would be “Status: install ok installed”. If not installed:
Use pip to install LiteLLM along with its proxy server component:
pip install ‘litellm[proxy]’
Use LiteLLM within this environment. To deactivate the virtual environment type deactivate.
Step 2: Configure LiteLLM
With LiteLLM installed, the next step is to define how it should operate. This is done through a configuration file, which specifies the language models to be used and the endpoints through which they’ll be served.
Navigate to a suitable directory and create a configuration file named config.yaml:
This configuration maps the model name codegemma to the codegemma:2b model served by Ollama at http://localhost:11434.
Step 3: Serve models with Ollama
To run your AI model locally, you’ll use a tool called Ollama. It’s designed specifically for hosting large language models (LLMs) directly on your device — without relying on cloud services.
To get started, install Ollama using the following command:
curl -fsSL https://ollama.com/install.sh | sh
This command downloads and runs the official installation script, which automatically starts the Ollama server.
Once installed, you’re ready to load the AI model you want to use. In this example, we’ll pull a compact model called codegemma:2b.
ollama pull codegemma:2b
After the model is downloaded, the Ollama server will begin listening for requests — ready to generate responses from your local setup.
Step 4: Launch the LiteLLM proxy server
With both the model and configuration ready, it’s time to start the LiteLLM proxy server — the component that makes your local AI model accessible to applications.
To launch the server, use the command below:
litellm –config ~/litellm_config/config.yaml
The proxy server will initialize and expose endpoints defined in your configuration, allowing applications to interact with the specified models through a consistent API.
Step 5: Test the deployment
Let’s confirm if everything works as expected. Write a simple Python script that sends a test request to the LiteLLM server and save it as test_script.py:
import openai client = openai.OpenAI(api_key=“anything”, base_url=“http://localhost:4000“)response = client.chat.completions.create( model=“codegemma”, messages=[{“role”: “user”, “content”: “Write me a Python function to calculate the nth Fibonacci number.”}])print(response)
Finally, run the script using this command:
python3 ./test_script.py
If the setup is correct, you’ll receive a response from the local model — confirming that LiteLLM is up and running.
Optimize LiteLLM performance on embedded devices To ensure fast, reliable performance on embedded systems, it’s important to choose the right language model and adjust LiteLLM’s settings to match your device’s limitations.
Choosing the Right Language Model
Not every AI model is built for devices with limited resources — some are just too heavy. That’s why it’s crucial to go with compact, optimized models designed specifically for such environments:
DistilBERT – a distilled version of BERT, retaining over 95% of BERT’s performance with 66 million parameters. It’s suitable for tasks like text classification, sentiment analysis, and named entity recognition.
TinyBERT – with approximately 14.5 million parameters, TinyBERT is designed for mobile and edge devices, excelling in tasks such as question answering and sentiment classification.
MobileBERT – optimized for on-device computations, MobileBERT has 25 million parameters and achieves nearly 99% of BERT’s accuracy. It’s ideal for mobile applications requiring real-time processing.
TinyLlama – a compact model with approximately 1.1 billion parameters, TinyLlama balances capability and efficiency, making it suitable for real-time natural language processing in resource-constrained environments.
MiniLM – a compact transformer model with approximately 33 million parameters, MiniLM is effective for tasks like semantic similarity and question answering, particularly in scenarios requiring rapid processing on limited hardware.
Selecting a model that fits your setup isn’t just about saving space — it’s about ensuring smooth performance, fast responses, and efficient use of your device’s limited resources.
Configure settings for better performance
A few small adjustments can go a long way when you’re working with limited hardware. By fine-tuning key LiteLLM settings, you can boost performance and keep things running smoothly.
Restrict the number of tokens
Shorter responses mean faster results. Limiting the maximum number of tokens in response can reduce memory and computational load. In LiteLLM, this can be achieved by setting the max_tokens parameter when making API calls. For example:
import openai client = openai.OpenAI(api_key=“anything”, base_url=“http://localhost:4000“)response = client.chat.completions.create( model=“codegemma”, messages=[{“role”: “user”, “content”: “Write me a Python function to calculate the nth Fibonacci number.”}], max_tokens=500 # Limits the response to 500 tokens)print(response)
Adjusting max_tokens helps keep replies concise and reduces the load on your device. Managing simultaneous requests
If too many requests hit the server at once, even the best-optimized model can get bogged down. That’s why LiteLLM includes an option to limit how many queries it processes at the same time. For instance, you can restrict LiteLLM to handle up to 5 concurrent requests by setting max_parallel_requests as follows:
This setting helps distribute the load evenly and ensures your device stays stable — even during periods of high demand. A Few More Smart Moves
Before going live with your setup, here are two additional best practices worth considering:
Secure your setup – implement appropriate security measures, such as firewalls and authentication mechanisms, to protect the server from unauthorized access.
Monitor performance – use LiteLLM’s logging capabilities to track usage, performance, and potential issues.
LiteLLM makes it possible to run language models locally, even on low-resource devices. By acting as a lightweight proxy with a unified API, it simplifies integration while reducing overhead. With the right setup and lightweight models, you can deploy responsive, efficient AI solutions on embedded systems — whether for a prototype or a production-ready solution.
Summary
Running LLMs on embedded devices doesn’t necessarily require heavy infrastructure or proprietary services. LiteLLM offers a streamlined, open-source solution for deploying language models with ease, flexibility, and performance — even on devices with limited resources. With the right model and configuration, you can power real-time AI features at the edge, supporting everything from smart assistants to secure local processing.
Join Our Community
We’re continuously exploring the future of tech, innovation, and digital transformation at Intellias — and we invite you to be part of the journey.
Visit our Intellias Blog and dive deeper into industry insights, trends, and expert perspectives.
This article was written by Vedrana Vidulin, Head of Responsible AI Unit at Intellias. Connect with Vedrana through her LinkedIn page.
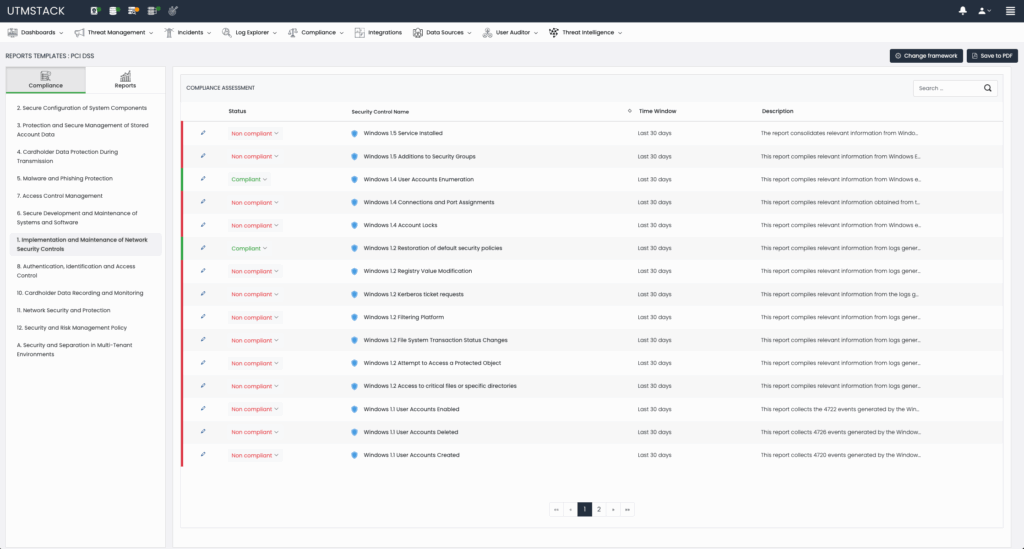
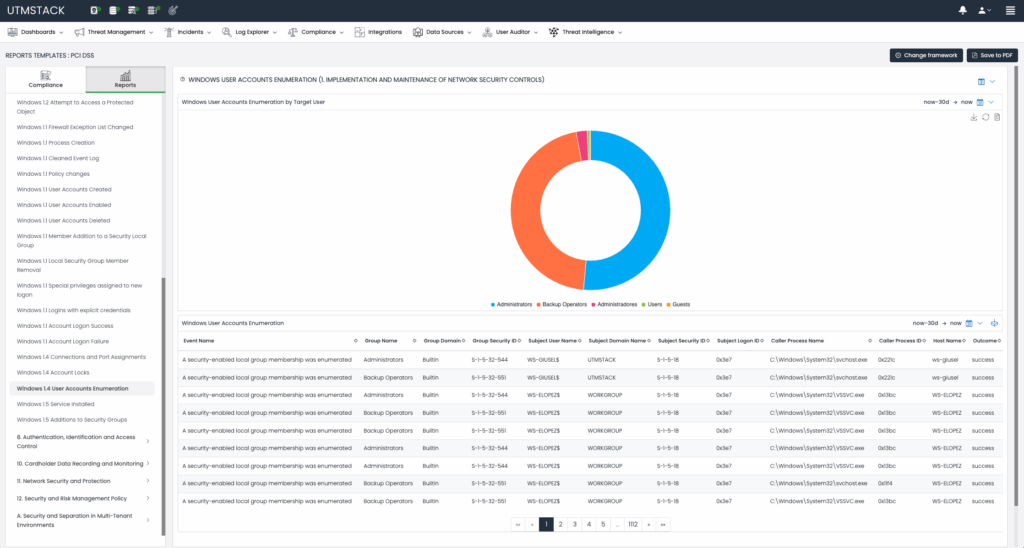
Achieving and maintaining compliance with regulatory frameworks can be challenging for many organizations. Managing security controls manually often leads to excessive use of time and resources, leaving less available for strategic initiatives and business growth.
Standards such as CMMC, HIPAA, PCI DSS, SOC2 and GDPR demand ongoing monitoring, detailed documentation, and rigorous evidence collection. Solutions like UTMStack, an open source Security Information and Event Management (SIEM) and Extended Detection and Response (XDR) solution, streamlines this complex task by leveraging its built-in log centralization, correlation, and automated compliance evaluation capabilities. This article explores how UTMStack simplifies compliance management by automating assessments, continuous monitoring, and reporting.
Understanding Compliance Automation with UTMStack
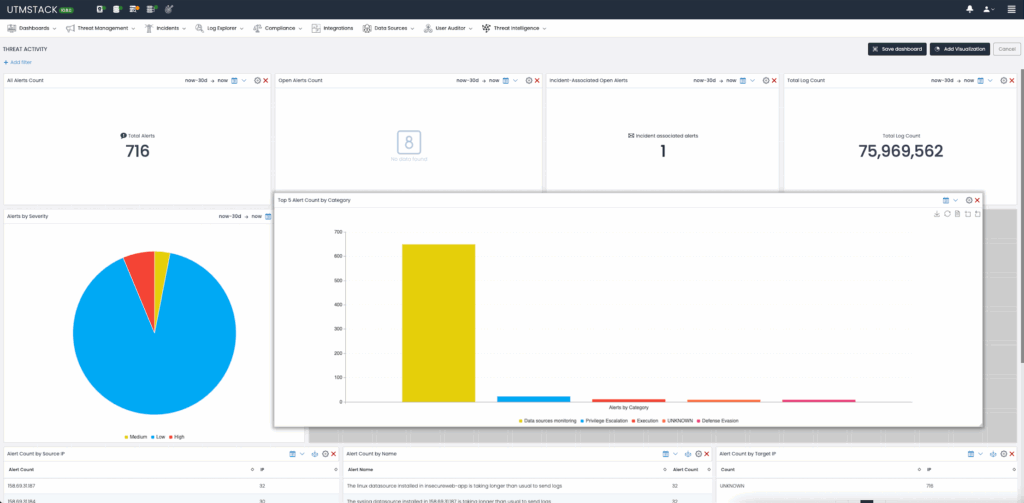
UTMStack inherently centralizes logs from various organizational systems, placing it in an ideal position to dynamically assess compliance controls. By continuously processing real-time data, UTMStack automatically evaluates compliance with critical controls. For instance, encryption usage, implementation of two-factor authentication (2FA) and user activity auditing among many others can be evaluated automatically.
Figure 1: Automated evaluation of Compliance framework controls.
Example Compliance Control Evaluations:
Encryption Enforcement: UTMStack continuously monitors logs to identify instances where encryption is mandatory (e.g., data in transit or at rest). It evaluates real-time compliance status by checking log events to confirm whether encryption protocols such as TLS are actively enforced and alerts administrators upon detection of potential non-compliance. The following event, for example would trigger an encryption control failure:
“message”: [{“The certificate received from the remote server was issued by an untrusted certificate authority. Because of this, none of the data contained in the certificate can be validated. The TLS connection request has failed. The attached data contains the server certificate”.}]
Two-Factor Authentication (2FA): By aggregating authentication logs, UTMStack detects whether 2FA policies are consistently enforced across the enterprise. Compliance is assessed in real-time, and automated alerts are generated if deviations occur, allowing immediate remediation. Taking Office365 as an example, the following log would confirm the use of 2FA in a given use authentication attempt:
User Activity Auditing: UTMStack processes comprehensive activity logs from applications and systems, enabling continuous auditing of user and devices actions. This includes monitoring privileged account usage, data access patterns, and identifying anomalous behavior indicative of compliance risks. This is a native function of UTMSatck and automatically checks the control if the required integrations are configured.
No-Code Compliance Automation Builder
One of UTMStack’s standout features is its intuitive, no-code compliance automation builder. Organizations can easily create custom compliance assessments and automated monitoring workflows tailored to their unique regulatory requirements without any programming experience. This flexibility empowers compliance teams to build bespoke compliance frameworks rapidly that update themselves and send reports on a schedule.
Figure 2: Compliance Framework Builder with drag and drop functionality.
Creating Custom Compliance Checks
UTMStack’s no-code interface allows users to:
Define custom compliance control logic visually.
Establish automated real-time monitoring of specific compliance conditions.
Generate and schedule tailored compliance reports.
This approach significantly reduces the administrative overhead, enabling compliance teams to respond swiftly to evolving regulatory demands.
Unified Compliance Management and Integration
Beyond automation, UTMStack serves as a centralized compliance dashboard, where controls fulfilled externally can be manually declared compliant within the platform. This unified “pane of glass” ensures that all compliance assessments—automated and manual—are consolidated into one comprehensive view, greatly simplifying compliance audits.
Moreover, UTMStack offers robust API capabilities, facilitating easy integration with existing Governance, Risk, and Compliance (GRC) tools, allowing seamless data exchange and further enhancing compliance management.
Sample Use Case: CMMC Automation
For CMMC compliance, organizations must demonstrate rigorous data security, availability, processing integrity, confidentiality, and privacy practices. UTMStack automatically evaluates controls related to these areas by analyzing continuous log data, such as firewall configurations, user access patterns, and audit trails.
Automated reports clearly detail compliance status, including specific control numbers and levels, enabling organizations to proactively address potential issues, dramatically simplifying CMMC assessments and future audits.
Figure 3: CMMC Compliance Control details
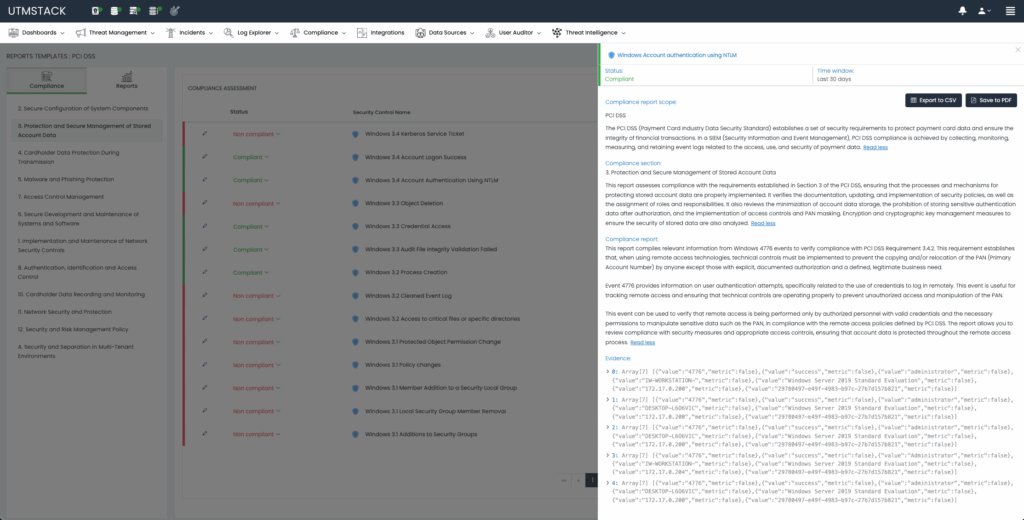
Compliance Control Evidence Remediation
When a framework control is identified as compliant, UTMStack automatically gathers the necessary evidence to demonstrate compliance. This evidence includes logs extracted from source systems and a dedicated, interactive dashboard for deeper exploration and analysis. Conversely, if the control evaluation identifies non-compliance, UTMStack employs an AI-driven technique known as Retrieval-Augmented Generation to provide remediation steps to security analysts and system engineers.
Compliance controls for each framework are not only evaluated but also provide dashboards for better understanding and navigation:
Figure 4: Compliance automation dashboards.
API-First Compliance Integration
UTMStack’s API-first approach enables compliance automation workflows to integrate effortlessly into existing IT ecosystems. Organizations leveraging various GRC platforms can easily synchronize compliance data, automate reporting, and centralize compliance evidence, thus minimizing manual data handling and significantly improving accuracy and efficiency.
Summary
Compliance management doesn’t have to be complicated or resource-draining. UTMStack’s open source SIEM and XDR solution simplifies and automates compliance with major standards such as CMMC, HIPAA, PCI DSS, SOC2, GDPR, and GLBA. By continuously monitoring logs, dynamically assessing compliance controls, and providing a user-friendly, no-code automation builder, UTMStack dramatically reduces complexity and enhances efficiency.
Organizations can easily customize and automate compliance workflows, maintain continuous monitoring, and integrate seamlessly with existing compliance tools, making UTMStack an invaluable resource for streamlined compliance management.
Join Our Community
We’re continuously improving UTMStack and welcome contributions from the cybersecurity and compliance community.
GitHub Discussions: Explore our codebase, submit issues, or contribute enhancements.
Discord Channel: Engage with other users, share ideas, and collaborate on improvements.
Your participation helps shape the future of compliance automation. Join us today!
Un’occasione di confronto sui temi caldi delle TLC, appuntamento 21 novembre ore 15:30 Dopo il seguito delle prime due edizioni, torna la Maratona delle TCL, un’iniziativa ideata da Assoprovider che punta a mettere a confronto gli operatori delle TLC. L’evento, aperto a tutti, si terrà il 21 novembre e sarà visibile sulle piattaforme Linkedin e […]
Roma, 22 novembre L'Associazione Assoprovider ha presentato un esposto alla Procura regionale della Corte dei Conti di Roma riguardante il sistema Piracy Shield, adottato dall'Autorità per le garanzie nelle comunicazioni (Agcom). L'esposto chiede di accertare la sussistenza di un eventuale danno erariale e la congruità dell'azione dell'Agcom nella gestione delle risorse economiche relative al Piracy […]
Nell'ottobre del 2024, a 19 anni esatti dalla storica vittoria che liberalizzò l'uso del Wi-Fi in Italia, Assoprovider si trova nuovamente in prima linea per difendere il futuro del settore delle telecomunicazioni. Con l'approvazione del decreto Omnibus, ora legge dello Stato, affrontiamo una delle sfide più critiche della nostra storia. 2005-2024: Dal trionfo alla nuova […]
Il rischio di carcerazione per gli Internet Service Provider (ISP) rappresenta una minaccia senza precedenti per il settore delle telecomunicazioni in Italia Assoprovider, l'associazione rappresentativa dei piccoli e medi fornitori di servizi Internet in Italia, lancia un forte allarme riguardo agli emendamenti recentemente approvati dalle Commissioni Bilancio e Finanze del Senato nell'ambito del DL Omnibus […]
La NIS2 è la direttiva sulla sicurezza informatica dell’Unione Europea. I Paesi membri hanno tempo fino al 17 ottobre 2024 per recepirla. Ma cosa cambia? Acronimo di Network and Information Security 2, la NIS2 è la direttiva emanata dall’Unione Europea, allo scopo di rafforzare la sicurezza informatica e la resilienza delle infrastrutture critiche in tutti […]
We are pleased to announce the availability of a new mailing list
service running under the new lists.linux.dev domain. The goal of this deployment is to
offer a subscription service that:
prioritizes mail delivery to public-inbox archives available
via lore.kernel.org
conforms to DMARC requirements to ensure subscriber delivery
makes minimal changes to email headers and no changes to the message
body content for the purposes of preserving patch attestation
If you would like to host a Linux development mailing list on this
platform, please see further details on the subspace.kernel.org site.
Why another mailing list service?
Linux development started in 1991 and has been ongoing for the past 30
years at an ever-increasing pace. Many popular code collaboration
platforms have risen throughout these three decades -- and while some of
them are still around, many others have shut down and disappeared
without offering any way to preserve the history of the projects they
used to host.
Development via mailed-in patches remains the only widely used mechanism
for code collaboration that does not rely on centralized infrastructure
maintained by any single entity. The Linux developer community sees
transparency, independence and decentralization as core guiding
principles behind Linux development, so it has deliberately chosen to
continue using email for all its past and ongoing collaboration efforts.
What about vger.kernel.org?
The infrastructure behind lists.linux.dev supports multiple domains, so
all mailing lists hosted on vger.kernel.org will be carefully migrated
to the same platform while preserving current addresses, subscribers,
and list ids. The only thing that will noticeably change is the
procedure to subscribe and unsubscribe from individual lists. As
majordomo is no longer maintained, we will instead switch to using
separate subscribe/unsusbscribe addresses per each list.
There are no firm ETAs for this migration, but if you are currently
subscribed to any mailing list hosted on vger.kernel.org, you will
receive a message when the migration date is approaching.
If you are a developer located around Beijing, or if your connection to
Beijing is faster and more reliable than to locations outside of China,
then you may benefit from the new git.kernel.org mirror kindly provided
by Code Aurora Forum at https://kernel.source.codeaurora.cn/. This is
a full mirror that is updated just as frequently as other git.kernel.org
nodes (in fact, it is managed by the same team as the rest of kernel.org
infrastructure, since CAF is part of Linux Foundation IT projects).
To start using the Beijing mirror, simply clone from that location or
add a separate remote to your existing checkouts, e.g.:
We are trialing out a new feature that can send you a notification when
the patches you send to the LKML are applied to linux-next or to the
mainline git trees. If you are interested in trying it out, here are the
details:
Alternatively, there should be a "X-Patchwork-Bot: notify" email header.
The patches must not have been modified by the maintainer(s).
All patches in the series must have been applied, not just some of them.
The last two points are important, because if there are changes between
the content of the patch as it was first sent to the mailing list, and
how it looks like by the time it is applied to linux-next or mainline,
the bot will not be able to recognize it as the same patch. Similarly,
for series of multiple patches, the bot must be able to successfully
match all patches in the series in order for the notification to go out.
If you are using git-format-patch, it is best to add the special
header instead of using the Cc notification address, so as to avoid any
unnecessary email traffic:
--add-header="X-Patchwork-Bot: notify"
You should receive one notification email per each patch series, so if
you send a series of 20 patches, you will get a single email in the form
of a reply to the cover letter, or to the first patch in the series. The
notification will be sent directly to you, ignoring any other addresses
in the Cc field.
The bot uses our LKML patchwork instance to perform matching and
tracking, and the source code for the bot is also available if you
would like to suggest improvements.
You may access the archives of many Linux development mailing lists on
lore.kernel.org. Most of them include a full archive of messages going
back several decades.
If you would like to suggest another kernel development mailing list to
be included in this list, please follow the instructions on the
following wiki page:
The software managing the archive is called Public Inbox and offers
the following features:
Fast, searchable web archives
Atom feeds per list or per individual thread
Downloadable mbox archives to make replying easy
Git-backed archival mechanism you can clone and pull
Read-only nntp gateway
We collected many list archives going as far back as 1998, and they are
now all available to anyone via a simple git clone. We would like to
extend our thanks to everyone who helped in this effort by donating
their personal archives.
Obtaining full list archives
Git clone URLs are provided at the bottom of each page. Note, that due
mailing list volume, list archives are sharded into multiple
repositories, each roughly 1GB in size. In addition to cloning from
lore.kernel.org, you may also access these repositories on
erol.kernel.org.
Mirroring
You can continuously mirror the entire mailing list archive collection
by using the grokmirror tool. The following repos.conf file should get
you all you need:
Please note, that you will require at least 20+ GB of local storage. The
mirroring process only replicates the git repositories themselves -- if
you want to use public-inbox with them, you will need to run
"public-inbox-init" and "public-inbox-index" to create the
database files required for public-inbox operation.
Linking to list discussions from commits
If you need to reference a mailing list discussion inside code comments
or in a git commit message, please use the "permalink" URL provided by
public-inbox. It is available in the headers of each displayed message
or thread discussion. Alternatively, you can use a generic message-id
redirector in the form:
We'd like to announce several small changes to the way Linux tarballs
are produced.
Mainline release tarball signatures
Starting with the 4.18 final release, all mainline tarball PGP
signatures will be made by Greg Kroah-Hartman instead of Linus Torvalds.
The main goal behind this change is to simplify the verification
process and make all kernel tarball releases available for download on
kernel.org be signed by the same developer.
Linus Torvalds will continue to PGP-sign all tags in the mainline
git repository. They can be verified using the git verify-tag
command.
Sunsetting .gz tarball generation
We stopped creating .bz2 copies of tarball releases 5 years ago, and the
time has come to stop producing .gz duplicate copies of all our content
as well, as XZ tools and libraries are now available on all major
platforms. Starting September 1st, 2018, all tarball releases available
via /pub download locations will only be available in XZ-compressed
format.
If you absolutely must have .gz compressed tarballs, you may obtain them
from git.kernel.org by following snapshot download links in the
appropriate repository view.
No future PGP signatures on patches and changelogs
For legacy purposes, we will continue to provide pre-generated
changelogs and patches (both to the previous mainline and incremental
patches to previous stable). However, from now on they will be generated
by automated processes and will no longer carry detached PGP signatures.
If you require cryptographically verified patches, please generate them
directly from the stable git repository after verifying the PGP
signatures on the tags using git verify-tag.
If you are in charge of CI infrastructure that needs to perform frequent
full clones of kernel trees from git.kernel.org, we strongly recommend
that you use the git bundles we provide instead of performing a full
clone directly from git repositories.
It is better for you, because downloading the bundle from CDN is
probably going to be much faster for you than cloning from our frontends
due to the CDN being more local. You can even copy the bundle to a
fileserver on your local infrastructure and save a lot of repeated
external traffic.
It is better for us, because if you first clone from the bundle, you
only need to fetch a handful of newer objects directly from
git.kernel.org frontends. This not only uses an order of magnitude less
bandwidth, but also results in a much smaller memory footprint on our
systems -- git daemon needs a lot of RAM when serving full clones of
linux repositories.
Here is a simple script that will help you automate the process of first
downloading the git bundle and then fetching the newer objects:
The Linux Foundation IT team has been working to improve the code
integrity of git repositories hosted at kernel.org by promoting the use
of PGP-signed git tags and commits. Doing so allows anyone to easily
verify that git repositories have not been altered or tampered with no
matter from which worldwide mirror they may have been cloned. If the
digital signature on your cloned repository matches the PGP key
belonging to Linus Torvalds or any other maintainer, then you can be
assured that what you have on your computer is the exact replica of the
kernel code without any omissions or additions.
To help promote the use of PGP signatures in Linux kernel development,
we now offer a detailed guide within the kernel documentation tree:
Further, we are happy to announce a new special program sponsored by
The Linux Foundation in partnership with Nitrokey -- the developer
and manufacturer of smartcard-compatible digital tokens capable of
storing private keys and performing PGP operations on-chip. Under this
program, any developer who is listed as a maintainer in the MAINTAINERS
file, or who has a kernel.org account can qualify for a free digital
token to help improve the security of their PGP keys. The cost of the
device, including any taxes, shipping and handling will be covered by
The Linux Foundation.
To participate in this program, please access the special store front
on the Nitrokey website:
To qualify for the program, you need to have an account at kernel.org or
have your email address listed in the MAINTAINERS file (following the
"M:" heading). If you do not currently qualify but think you should,
the easiest course of action is to get yourself added to the MAINTAINERS
file or to apply for an account at kernel.org.
Which devices are available under this program?
The program is limited to Nitrokey Start devices. There are several
reasons why we picked this particular device among several available
options.
First of all, many Linux kernel developers have a strong preference not
just for open-source software, but for open hardware as well. Nitrokey
is one of the few companies selling GnuPG-compatible smartcard devices
that provide both, since Nitrokey Start is based on Gnuk cryptographic
token firmware developed by Free Software Initiative of Japan. It is
also one of the few commercially available devices that offer native
support for ECC keys, which are both faster computationally than large
RSA keys and generate smaller digital signatures. With our push to use
more code signing of git objects themselves, both the open nature of the
device and its support for fast modern cryptography were key points in
our evaluation.
Additionally, Nitrokey devices (both Start and Pro models) are already
used by open-source developers for cryptographic purposes and they
are known to work well with Linux workstations.
What is the benefit of digital smartcard tokens?
With usual GnuPG operations, the private keys are stored in the home
directory where they can be stolen by malware or exposed via other
means, such as poorly secured backups. Furthermore, each time a GnuPG
operation is performed, the keys are loaded into system memory and can
be stolen from there using sufficiently advanced techniques (the likes
of Meltdown and Spectre).
A digital smartcard token like Nitrokey Start contains a cryptographic
chip that is capable of storing private keys and performing crypto
operations directly on the token itself. Because the key contents never
leave the device, the operating system of the computer into which the
token is plugged in is not able to retrieve the private keys themselves,
therefore significantly limiting the ways in which the keys can be
leaked or stolen.
Questions or problems?
If you qualify for the program, but encounter any difficulties
purchasing the device, please contact Nitrokey at shop@nitrokey.com.
For any questions about the program itself or with any other comments,
please reach out to info@linuxfoundation.org.
As you may be aware, starting with 4.12-rc1 Linus will no longer provide
signed tarballs and patches for pre-release ("-rc") kernels. Reasons for
this are multiple, but largely this is because people who are most
interested in pre-release tags -- kernel developers -- do not rely on
patches and tarballs to do their work.
Obtaining tarballs on your own
Here is how you can generate the tarball from a pre-release tag using
the "git archive" command (we'll use 4.12-rc1 in these examples):
git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
cd linux
git verify-tag v4.12-rc1
git archive --format=tar.gz --prefix=linux-4.12-rc1/ \
-o linux-4.12-rc1.tar.gz v4.12-rc1
The upside of this method is that during the "git verify-tag" step
you will check the PGP signature on the tag to make sure that what you
cloned is exactly the same tree as on Linus Torvalds's computer.
The downside of this method is that you will need to download about 1
GiB of data -- the entire git history of the Linux kernel -- just to get
the latest tag. Notably, when -rc2 is tagged, all you'll need to do is
run a quick "git pull" to get the latest objects and it will be
dramatically less data to download, so cloning the whole tree may be
worth it to you in the long run if you plan to do this again in the
future.
If you do not want to download the whole git repository and just want to
get the latest tarball, you can download the version automatically
generated by cgit at the following (or similar URL):
Please note that you will not be able to cryptographically verify the
integrity of this archive, but the download will be about 10 times less
in size than the full git tree.
Obtaining patches to the previous mainline
If you would like to get just the patch to the previous mainline
release, you can get it from cgit as well:
Unfortunately, cgit does not currently offer an easy way to get
gzip-compressed patches, but if you would like to reduce the amount of
data you download, you can use http-level gzip compression:
We intentionally did not provide these automatically generated tarballs
and patches in locations previously used by Linus
(/pub/linux/kernel/v4.x/testing), even if this meant potentially
breaking automated scripts relying on contents published there. Anything
placed in the /pub tree is signed and curated directly by developers
and all patches and software archives published there invariably come
with a PGP signature provided directly by the developer of that software
(or one of the developers).
Patches and tarballs automatically generated by git.kernel.org are NOT
a replacement for this stringent process, but merely a convenience
service that comes with very different trust implications. By providing
these at different URLs we wanted all users of these services to make a
conscious decision on whether they want to trust these automatically
generated tarballs and patches, or whether they want to change their
process to continue to use PGP-verifiable tags directly from the git
tree.
The XZ tarballs for the following kernel releases did not initially pass
signature verification due to benign changes to the tarball structure
done by the pixz compression tool:
4.11.1
4.10.16
4.9.28
4.4.68
These changes would have resulted in GPG returning "Bad Signature" if
you tried to verify their integrity. Once we identified the problem, we
generated new XZ tarballs without tar header modifications and now they
should all pass PGP signature verification.
We preserved the original .xz tarballs as -badsig files in the archives
in case you wanted to verify that there was nothing malicious in them,
merely tar header changes. You can find them in the same v4.x directory:
We are extremely happy to announce that Packet has graciously donated
the new hardware systems providing read-only public access to the
kernel.org git repositories and the public website (git.kernel.org and
www.kernel.org, respectively). We have avoided using cloud providers in
the past due to security implications of sharing hypervisor memory with
external parties, but Packet's hardware-based single-tenant approach
satisfies our security requirements while taking over the burden of
setting up and managing the physical hardware in multiple worldwide
datacenters.
As of March 11, 2017, the four new public frontends are located in the
following geographical locations:
San Jose, California, USA
Parsippany, New Jersey, USA
Amsterdam, Netherlands
Tokyo, Japan
We have changed our DNS configuration to support GeoDNS, so your
requests should be routed to the frontend nearest to you.
Each Packet-hosted system is significantly more powerful than our
previous generation frontends and have triple the amount of available
RAM, so they should be a lot more responsive even when a lot of people
are cloning linux.git simultaneously.
Our special thanks to the following organizations who have graciously
donated hosting for the previous incarnation of kernel.org frontends:
Those of you who have been around for a while may remember a time when
you used to be able to mount kernel.org directly as a partition on your
system using NFS (or even SMB/CIFS). The Wayback Machine shows that this
was still advertised some time in January 1998, but was removed by
the time the December 1998 copy was made.
Let's face it -- while kinda neat and convenient, offering a public
NFS/CIFS server was a Pretty Bad Idea, not only because both these
protocols are pretty terrible over high latency connections, but also
because of important security implications.
Well, 19 years later we're thinking it's time to terminate another
service that has important protocol and security implications -- our
FTP servers. Our decision is driven by the following considerations:
The protocol is inefficient and requires adding awkward kludges to
firewalls and load-balancing daemons
FTP servers have no support for caching or accelerators, which has
significant performance impacts
Most software implementations have stagnated and see infrequent updates
All kernel.org FTP services will be shut down by the end of this year.
In hopes to minimise the potential disruption, we will be doing it in
two stages:
If your browser alerted you that the site certificates have changed,
that would be because we replaced our StartCOM, Ltd certificates with
those offered by our DNS registrar, Gandi. We are very thankful to
Gandi for this opportunity.
A common question is why we aren't using the certificates offered by the
Let's Encrypt project, and the answer is that there are several
technical hurdles (on our end) that currently make it complicated. Once
we resolve them, we will most likely switch to using certificates issued
by our fellow Linux Foundation project.
If you find yourself on an unreliable Internet connection and need to
perform a fresh clone of Linux.git, you may find it tricky to do so if
your connection resets before you are able to complete the clone. There
is currently no way to resume a git clone using git, but there is a neat
trick you can use instead of cloning directly -- using git bundle
files.
Here is how you would do it.
Start with "wget -c", which tells wget to continue interrupted
downloads. If your connection resets, just rerun the same command while
in the same directory, and it will pick up where it left off:
Now, point the origin to the live git repository and get the latest changes:
cd linux
git remote remove origin
git remote add origin https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
git pull origin master
Once this is done, you can delete the "clone.bundle" file, unless
you think you will need to perform a fresh clone again in the future.
The "clone.bundle" files are generated weekly on Sunday, so they
should contain most objects you need, even during kernel merge windows
when there are lots of changes committed daily.
We are happy to announce that Fastly has offered their worldwide CDN
network to provide fast download services for Linux kernel releases,
which should improve download speeds for those of you located outside
North America. We have modified the front page to offer CDN-powered
download links, but all the existing URLs should continue to work.
If you would like to avoid using Fastly, you can simply change the URL
to have "www.kernel.org" instead of "cdn.kernel.org". As always, please
use PGP Signature Verification for all downloaded files regardless of
where you got them.
Linus named the upcoming 4.0 release of the kernel "Hurr Durr I'ma
Sheep" (see his git commit), so we are celebrating this April Fool's
day with a minor prank. If you've been redirected to
imasheep.hurrdurr.org, do not panic. It's all part of the joke.
We've also restored all FTP and Rsync access to the
mirrors.kernel.org servers, as we seem to have resolved our SSD
and dm_cache problems. If you're still using FTP, however, please
consider switching to HTTP. FTP is a protocol designed for a different
era -- these days everyone should be avoiding it for multiple
reasons.
We've had to temporarily limit FTP access to mirrors.kernel.org due
to high IO load.
We have recently upgraded our hardware in order to increase capacity --
16TB was no longer nearly sufficient enough to host all the distro
mirrors and archives. We chose larger but slower disks and offset the
loss of performance by heavily utilizing SSD IO caching using dm-cache.
While it was performing very well, we have unfortunately run across an
FS data corruption bug somewhere along this stack:
megaraid_sas + dm_cache + libvirt/virtio + xfs
We've temporarily removed dm-cache from the picture and switched to
Varnish on top of SSD for http object caching. Unfortunately, as Varnish
does not support FTP, we had to restrict FTP protocol to a limited
number of concurrent sessions in order to reduce disk IO. If you are
affected by this, simply switch to HTTP protocol that does not have such
restrictions.
This is a temporary measure until we identify the dm-cache problem that
was causing data corruption, at which point we will restore unrestricted
FTP access.
Since we rely on the OpenSSL library for serving most of our websites,
we, together with most of the rest of the open-source world, were
vulnerable to the HeartBleed vulnerability. We have switched to the
patched version of OpenSSL within hours of it becoming available, plus
have performed the following steps to mitigate any sensitive information
leaked via malicious SSL heartbeat requests:
Replaced all SSL keys across all kernel.org sites.
Expired all active sessions on Bugzilla, Patchwork, and Mediawiki
sites, requiring everyone to re-login.
Changed all passwords used for admin-level access to the above sites.
As kernel.org developers do not rely on SSL to access git repositories,
there is no need to replace any SSH or PGP keys used for developer
authentication.
If you have any questions or concerns, please email us at
webmaster@kernel.org for more information.
We started listing xz-compressed versions of kernel archives in all our
announcements back in March 2013, and the time has come to complete the
switch. Effective immediately, we will no longer be providing
bzip2-compressed versions for new releases of the Linux kernel and other
software. Any previously released .tar.bz2 archives will continue to be
available without change, and we will also continue to provide
gzip-compressed versions of all new releases for the foreseeable future.
So, from now on, all releases will be offered as both .tar.gz and
.tar.xz, but not as .tar.bz2. We apologize if this interferes with any
automated tools.
Happy new year!
Happy new year to all kernel.org users and visitors. The Linux
Foundation and Linux Kernel Archives teams extend their warmest wishes
to you all, and we hope that 2014 proves to be just as awesome (or
awesomer) for the Linux kernel.
We have added another official frontend for serving the kernel content,
courtesy of Vexxhost, Inc. There is now a total of three frontends,
one in Palo Alto, California, one in Portland, Oregon, and one in
Montreal, Quebec. This should allow for better geographic dispersion of
official mirrors, as well as better fault tolerance.
Kernel.googlesource.com
We are happy to announce that kernel.googlesource.com is now relying on
grokmirror manifest data to efficiently mirror git.kernel.org, which
means that if accessing git.kernel.org is too high latency for you due
to your geographical location (EMEA, APAC), kernel.googlesource.com
should provide you with a fast local mirror that is at most 5 minutes
behind official sources.
We extend our thanks to Google for making this available to all kernel
hackers and enthusiasts worldwide.
TLS 1.2 and PFS
With the latest round of upgrades, we are now serving TLS 1.2 with PFS
across all kernel.org sites, offering higher protection against
eavesdropping.
If you would like to mirror all or a subset of kernel.org git
repositories, please use a tool we wrote for this purpose, called
grokmirror. Grokmirror is git-aware and will create a complete mirror of
kernel.org repositories and keep them automatically updated with no
further involvement on your part.
Grokmirror works by keeping track of repositories being updated by
downloading and comparing the master manifest file. This file is only
downloaded if it's newer on the server, and only the repositories that
have changed will be updated via "git remote update".
You can read more about grokmirror by reading the README file.
Obtaining grokmirror
If grokmirror is not yet packaged for your distribution, you can obtain
it from a git repository:
It is recommended that you create a dedicated "mirror" user that will
own all the content and run all the cron jobs. It is generally
discouraged to run this as user "root".
The default repos.conf already comes pre-configured for kernel.org. We
reproduce the minimal configuration here:
[kernel.org]
site = git://git.kernel.org
manifest = http://git.kernel.org/manifest.js.gz
default_owner = Grokmirror User
#
# Where are we going to put the mirror on our disk?
toplevel = /var/lib/git/mirror
#
# Where do we store our own manifest? Usually in the toplevel.
mymanifest = /var/lib/git/mirror/manifest.js.gz
#
# Where do we put the logs?
log = /var/log/mirror/kernelorg.log
#
# Log level can be "info" or "debug"
loglevel = info
#
# To prevent multiple grok-pull instances from running at the same
# time, we first obtain an exclusive lock.
lock = /var/lock/mirror/kernelorg.lock
#
# Use shell-globbing to list the repositories you would like to mirror.
# If you want to mirror everything, just say "*". Separate multiple entries
# with newline plus tab. Examples:
#
# mirror everything:
#include = *
#
# mirror just the main kernel sources:
#include = /pub/scm/linux/kernel/git/torvalds/linux.git
# /pub/scm/linux/kernel/git/stable/linux-stable.git
# /pub/scm/linux/kernel/git/next/linux-next.git
#
# mirror just git:
#include = /pub/scm/git/*
include = *
#
# This is processed after the include. If you want to exclude some specific
# entries from an all-inclusive globbing above. E.g., to exclude all
# linux-2.4 git sources:
#exclude = */linux-2.4*
exclude =
Install this configuration file anywhere that makes sense in your
environment. You'll need to make sure that the following directories (or
whatever you changed them to) are writable by the "mirror" user:
/var/lib/git/mirror
/var/log/mirror
/var/lock/mirror
Mirroring kernel.org git repositories
Now all you need to do is to add a cronjob that will check the
kernel.org mirror for updates. The following entry in
/etc/cron.d/grokmirror.cron will check the mirror every 5 minutes:
# Run grok-pull every 5 minutes as "mirror" user
*/5 * * * * mirror /usr/bin/grok-pull -p -c /etc/grokmirror/repos.conf
(You will need to adjust the paths to the grok-pull command and to
repos.conf accordingly to reflect your environment.)
The initial run will take many hours to complete, as it will need to
download about 50 GB of data.
Mirroring a subset of repositories
If you are only interested in carrying a subset of git repositories
instead of all of them, you are welcome to tweak the include and
exclude parameters.
Special thanks to Benoît Monin for donating a MIT-licensed CSS theme to
the kernel.org project to replace the one we hastily put together.
Though the Pelican authors have since obtained a free-license
commitment from the copyright owners of the CSS files shipping with
Pelican, we wanted to have something that looked a bit less like the
default theme anyway.
If anyone else wants to participate, full sources of the kernel.org
website are available from the git repository.
We've implemented two oft-requested features today:
The download links now default to .tar.xz versions of archives
There is now a JSON file with the release information located in
https://www.kernel.org/releases.json. If you've been screen-scraping
the front page, please use this instead.
If you have any other feature suggestions, please send them to
webmaster@kernel.org.
Due to a failure in one of the rsync scripts during the maintenance
window, the mirrors of /pub hierarchy on www.kernel.org got erased. We
are resyncing them now from the master storage, but in the meantime you
will probably get an occasional "Forbidden". The entirety of the archive
should be rsync'ed in a few hours.
We apologize profusely for the problem and will fix the script to make
sure this doesn't happen again.
You are probably wondering what happened to the site's look.
Unfortunately, we've been alerted that the default theme shipped by
Pelican (which we largely adapted) has an unclear license. Until this is
cleared up, we've put together a quick-and-dirty cleanroom CSS
reimplementation that preserves the functional aspects of the site, but
sacrifices a lot of the bells and whistles.
If you are a CSS designer and would like to donate your own cleanroom
style, please let us know at webmaster@kernel.org.
Our apologies, and we promise to keep a keener eye on licensing
details of various templates distributed with open-source products.
Welcome to the reworked kernel.org website. We have switched to using
Pelican in order to statically render our site content, which
simplifies mirroring and distribution. You can view the sources used to
build this website in its own git repository.
Additionally, we have switched from using gitweb-caching to using cgit
for browsing git repositories. There are rewrite rules in place to
forward old gitweb URLs to the pages serviced by cgit, so there
shouldn't be any broken links, hopefully. If you notice that something
that used to work with gitweb no longer works for you with cgit, please
drop us a note at webmaster@kernel.org.
L’associazione dei provider di servizi internet contesta la sanzione amministrativa comminata da AGCOM, nel caso del Piracy Shield e sceglie di impugnare la decisione davanti al Tribunale Amministrativo Assoprovider, l’associazione che tutela i diritti dei provider indipendenti di servizi Internet, si rivolge al Tar contro la multa che AGCOM le ha comminato nello scorso aprile […]
Negli ultimi avvenimenti meteo dell’autunno 2019 ci si è resi conto di quanto fragili siano i sistemi di comunicazione che necessitano di un’accesso alla rete per funzionare, la radio fa parte di uno di quei pochi sistemi di comunicazione che non necessità di internet.
In caso di blocco della rete le radio sono indispensabili, sono state utili in passato e lo sono tutt’ora e nonostante la tecnologia avanzi non c’è nulla che possa sostituirle.
Meteonuvola è un progetto amatoriale, nato su Telegram, fatto di soli appassionati che hanno l’intento di creare un sistema di informazione culturale e di sostegno emergenziale, per questo, per rendere ancora più efficace il progetto, abbiamo creato dato vita ad un nuovo servizio, la Rete Radio Prepper.
In caso di necessità (o per semplici prove radio) l’utente si collega al bot telegram http://t.me/meteonuvolabote manda la propria segnalazione (radio, meteo, eventi sociopolitici ecc..) seguendo le istruzioni a schermo ( è molto semplice ), una volta inviata quest’ultima comparirà nella mappa interattiva che contiene anche altre informazioni, automaticamente la notifica arriverà nel canale http://t.me/radiosegnalazioni , gli utenti del canale quindi riceveranno una notifica e si potranno mettere in contatto con il segnalatore più vicino a lui.
Gli utenti che vogliono entrare a fare parte della nostra rete non devono fare altro che collegarsi al bot Telegrammeteonuvolabot, seguire le istruzioni per ricevere un nominativo e segnalare la propria stazione fissa.
La Rete Radio Prepper usa il canale 2 PMR/CB (am o fm), 145.300 FM e 7190 LSB HF.
In caso di rete fuori uso la mappa non sarà accessibile ovviamente ma è possibile scaricare i file KMZ per poterla caricare su altre mappe utilizzate su cellulare o google earth, consigliamo comunque di fare una stampa della propria zona.
I PMR sono ricetrasmittenti che soffrono degli ostacoli, in città difficilmente si arriverà a coprire oltre il km, fuori città in area esposta circa 5-7 km, in altura si possono superare anche i 20km, con alcuni casi particolari di oltre 100 km, i CB permettono di raggiungere distanze notevoli ma hanno bisogno di antenne più impegnative, sono più indicati per essere montati sull’autovettura o in casa.
Ricapitolando:
Rete Radio Prepper, canale 2 PMR e canale 2 CB in am o fm, 145.300 FM e 7190 LSB solo per radioamatori.
Bot telegram per aderire e per segnalarsi : http://t.me/meteonuvolabot
Canale segnalazioni ( dove giungono le proprie segnalazioni radio..) : http://t.me/radiosegnalazioni
Gruppo emergenze e segnalazioni eventi avversi http://t.me/prepper_italia
Gruppo semplici segnalazioni meteo : http://t.me/italiameteo
Vogliamo precisare che non c’è alcuna intenzione di prendere iniziative al di fuori della competenza amatoriale, la rete “potrebbe servire in caso di…” ma non si sostituisce in nessun caso agli Organi Ufficiali, si tratta di un progetto volontario e di libero uso.
Buongiorno a tutti, è in fase di sperimentazione un servizio di avvisi condizioni meteo avverse in modalità MFSK32 sulla banda dei 20 metri, frequenza 14.310 mhz.
Gli avvisi verranno emessi in caso di effettiva necessità quindi senza un orario ben preciso.
Zona di emissione 1 Torino, potenza 20w.
Zona di emissione 2 Cagliari, potenza 20w
Per l’ascolto su windows consigliamo il programma fldigi, per Android andflmsg
Servizio a cura di IW1GHG e IS0AGS.
Per chi volesse la QSL di ascolto si prega di contattarci fornendo il nominativo SWL o radioamatoriale , l’ora, il giorno e l’RST.
Dalla tarda serata è previsto l’arrivo di nevicate deboli diffuse su parte del nord ovest in spostamento verso est nel corso della notte. Maggiormente coinvolti i settori a sud del Po, in particolare Liguria, Piemonte meridionale, Emilia, Appennino Tosco-Emiliano, Lombardia meridionale e da domattina tutto il nord Est la Romagna. Prestare particolare attenzione nella guida stante le temperature negative e le possibili condizioni critiche della rete viaria per presenza di neve e ghiaccio.
Il 16.5 u.s. il Presidente dell’associazione Assoprovider Giovanbattista Frontera e il Consulente Giuridico Fulvio Sarzana sono stati ricevuti dal Sottosegretario all’innovazione tecnologica Sen. Alessio Butti, al Dipartimento per la Trasformazione Digitale. L’incontro sui temi caldi della digitalizzazione è stato molto proficuo vista la notevole identità di vedute su molti argomenti. Si è delineata anche una […]
Roma, 22 aprile. Assoprovider, l’associazione di operatori di TLC indipendenti, continua la sua battaglia di legalità sulla piattaforma dell’AGCOM, Piracy shield, ed impugna le disposizioni regolamentari davanti al Consiglio di Stato, attraverso lo Studio Legale Sarzana di Roma. Le decine di segnalazioni di utenti, imprese ed associazioni, ingiustamente lese nei propri diritti, hanno convinto l’Associazione […]
L’Autorità per le Garanzie nelle Comunicazioni (AGCOM) ha multato l’Associazione Assoprovider per ostacolo all’attività di vigilanza nel caso Piracy Shield. Roma, 4 aprile. Assoprovider, l’associazione degli Internet Service Provider, è stata multata da AGCOM per ostacolo ad attività di vigilanza nel contesto dell’attività della piattaforma Piracy Shield. Il provvedimento giunge dopo il rifiuto da parte […]
Sono due i grandi limiti della Zona Zes Unica Sud, l’esclusione della banda larga e di tutti i progetti di investimento di importo inferiore a 200 mila euro, come spiega il vice presidente di Assoprovider in quest’intervista. «Dobbiamo farci sentire, chiudere i nostri servizi per qualche giorno, per far comprendere a questo governo quanto le […]
Aggiornamento: per motivi termici indipendenti dalla nostra volontà l'incontro
inizialmente previsto per le ore 16 è stato posticipato di due ore. L'inizio
sarà alle ore 18.00.
Campagna di autofinanziamento per abbiamoundominio.org di unit hacklab.
C'è/Abbiamo bisogno, come ogni anno, di pagare il server e anche il dominio.
Stiamo anche ragionando di allargarci e prendere un server più capace, perchè
quello che stiamo usando, pagato attraverso iniziative di autofinanziamento, è
arrivato a tappo.
Quarta puntata di Bitume: trasmissione radiofonica aperiodica a cura di unit
hacklab di Milano.
L'approfondimento satirico della rivoluzione digitale.
Bitume parla di diritti digitali, di nuove forme di protesta incentrate sulla
tecnologia, di media caldi e freddi, di server liberi, di hacking, di sicurezza …
Terza puntata di Bitume: trasmissione radiofonica aperiodica a cura di unit
hacklab di Milano.
L'approfondimento satirico della rivoluzione digitale.
Bitume parla di diritti digitali, di nuove forme di protesta incentrate sulla
tecnologia, di media caldi e freddi, di server liberi, di hacking, di sicurezza …
acheritivo di autofinanziamento unit hacklab: rooting libero del telefono,
elettronica usata a offerta libera. Hai bisogno di un lettore dvd? Di uno
scanner? Noi di fare spazio e pagare il server.
Seconda puntata di Bitume: trasmissione radiofonica aperiodica a cura di unit
hacklab di Milano.
L'approfondimento satirico della rivoluzione digitale.
Bitume parla di diritti digitali, di nuove forme di protesta incentrate sulla
tecnologia, di media caldi e freddi, di server liberi, di hacking, di sicurezza …
Prima puntata di bitume, trasmissione radiofonica aperiodica a cura di unit
hacklab di Milano.
L'approfondimento satirico della rivoluzione digitale.
Bitume parla di diritti digitali, di nuove forme di protesta incentrate sulla
tecnologia, di media caldi e freddi, di server liberi, di hacking, di sicurezza …
Quarta visione libera del ciclo di proiezioni a cura di Unit hacklab.
Life of Brian, Monty Python, 1979
ENG sub ITA
... gli unici che odiamo più dei romani
sono il Fronte del Popolo Giudeo.
E il Fronte Popolare dei Giudei.
Ah, sì.
Separatisti.
E il Fronte Popolare della Giudea.
Già …
Terza visione libera del ciclo di proiezioni a cura di Unit hacklab.
Risk, Laura Poitras, 2016
Documentario su Julian Assange, fondatore di Wikileaks.
Motivazioni e contraddizioni su Assange e le sue cerchie, con un occhio in particolare sui rischi che sono stati
presi. Il documentario copre il periodo dal 2010 …
Prima visione libera del ciclo di proiezioni a cura di Unit hacklab.
Nirvana, Salvatores, 1997
Film cyberpunk girato a Milano (e nei sotterranei di Macao). Fortemente influenzato dai romanzi di Gibson e sua volta
ritenuto tra le fonti di ispirazione della trilogia di Matrix. Affronta il tema dell'esistenza autonoma o …
Vi invitiamo questo sabato 25 febbraio dalle 16 al Salone Polivalente di Bussoleno
per un evento preparatorio ad Hackmeeting 0x14 (che ricordiamo quest'anno si terrá
qui vicino in Val Susa, in particolare a Venaus, dal 15 al 18 giugno).
Ci sará il collettivo Ippolita che parlerá di social network e tecnologie del dominio,
a seguire un avvocato fará una panoramica sull'utilizzo dei captatori informatici,
mentre noi come _TO hacklab mostreremo nella pratica l'utilizzo di un captatore informatico.
A seguire domande, chiacchiere e condivisione di idee in preparazione di Hackmeeting.
Il 21 Gennaio dalle 16 saremo al Gabrio (via Millio 42) per il warmup di Hackmeeting 0x14 (che quest'anno si terrà in Val Susa) e faremo due chiacchiere su hackmeeting e trojan di stato con il collettivo tracciabi.li.
Volevamo un hacklab più aperto, ma non in questo senso.
Durante la perquisizione al CSOA Gabrio di ieri le divise blu hanno deciso di accanirsi anche contro _TO*hacklab, tentando di forzare la porta blindata per poi distruggere il muro a fianco, entrare e constatare che quello spazio era un'officina per computer come effettivamente poteva sembrare dalla breccia nella finestra.
Per giustificare l'impegno speso nel distruggere questo muro è stata staccata la spina all'armadio hub/gateway; come conseguenza un alimentatore si è sentito male ed è stato soccorso nelle ore successive, quando tutto è tornato operativo.
Ci fa sorridere la miseria di queste indagini e di questi piccoli personaggi ancora a cavalcare un modello proibizionista che nessuno più intende perseguire perché ampiamente fallimentare, decidendo di colpire una delle poche esperienze di autoproduzione nello stesso giorno in cui un magistrato di rilevo occupa le prime pagine dei quotidiani schierandosi a favore della legalizzazione.
Siamo solidali con i due compagni colpiti dalla repressione, continueremo ad essere complici del CSOA Gabrio nell'antiproibizionismo come nelle diverse lotte.
Stiamo ricostruendo l'hacklab (e il sito, e tutto quanto). Se vuoi darci una mano ci trovi al primo piano del CSOA Gabrio, in Via F. Millio 42 a Torino. Non c'è (ancora) un orario stabilito, la cosa migliore è contattarci con una mail a underscore[at]autistici[dot]org . A presto!





























{kind=link}